You create a datastore named training_data that references a blob container in an Azure Storage account. The blob container contains a folder named csv_files in which multiple comma-separated values (CSV) files are stored.
You have a script named train.py in a local folder named ./script that you plan to run as an experiment using an estimator.
The script includes the following code to read data from the csv_files folder:
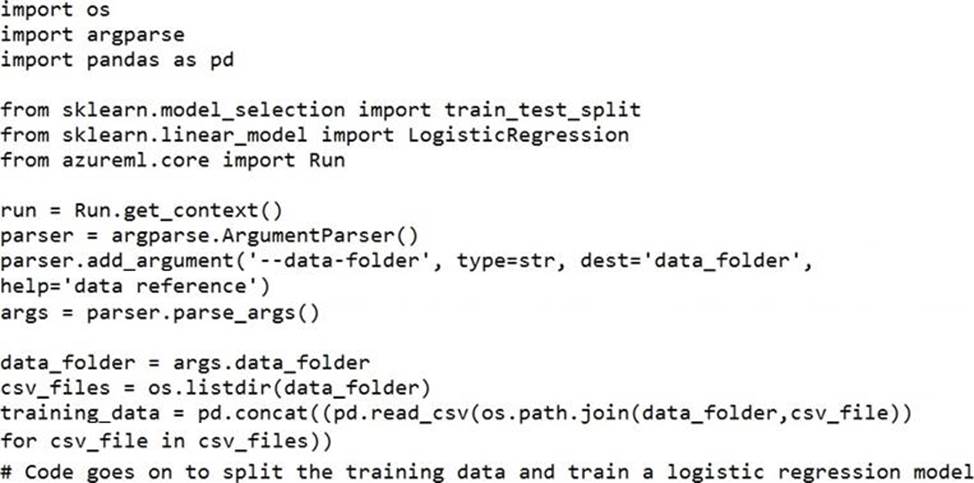
You have the following script.
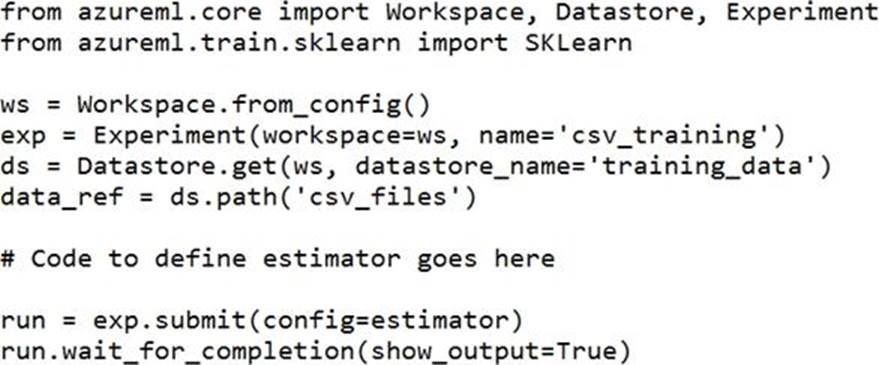
You need to configure the estimator for the experiment so that the script can read the data from a data reference named data_ref that references the csv_files folder in the training_data datastore.
Which code should you use to configure the estimator?
A)

B)
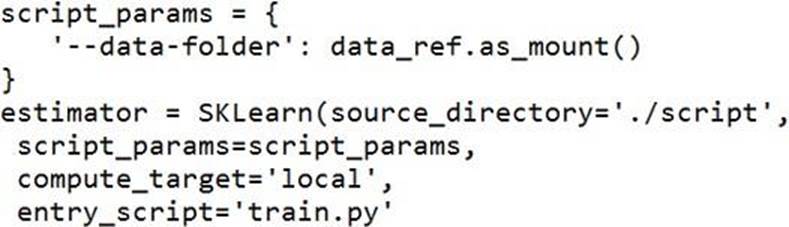
C)

D)

E)

A . Option A
B . Option B
C . Option C
D . Option D
E . Option E
Answer: B
Explanation:
Besides passing the dataset through the inputs parameter in the estimator, you can also pass the dataset through script_params and get the data path (mounting point) in your training script via arguments. This way, you can keep your training script independent of azureml-sdk. In other words, you will be able use the same training script for local debugging and remote training on any cloud platform.
Example:
from azureml.train.sklearn import SKLearn
script_params = {
# mount the dataset
on the remote compute and pass the mounted path as an argument to the training
script
‘–data-folder’:
mnist_ds.as_named_input(‘mnist’).as_mount(),
‘–regularization’:
Latest DP-100 Dumps Valid Version with 227 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
