HOTSPOT
You are designing an Al solution that must meet the following processing requirements:
– Use a parallel processing framework that supports the in-memory processing of high volumes of data.
– Use in-memory caching and a columnar storage engine for Apache Hive queries.
What should you use to meet each requirement? To answer, select the appropriate options in the
answer area. NOTE: Each correct selection is worth one point.
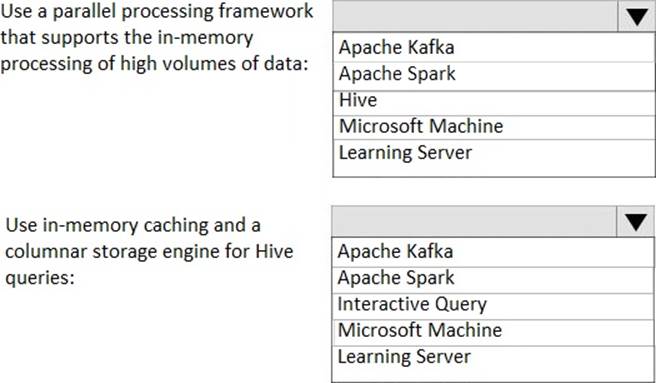
Answer: 
Explanation:
Box 1: Apache Spark
Apache Spark is a parallel processing framework that supports in-memory processing to boost the performance of big-data analytic applications. Apache Spark in Azure HDInsight is the Microsoft implementation of Apache Spark in the cloud.
Box 2: Interactive Query
Interactive Query provides In-memory caching and improved columnar storage engine for Hive queries.
References: https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-overview
https://docs.microsoft.com/bs-latn-ba/azure/hdinsight/interactive-query/apache-interactive-queryget-started
Latest AI-100 Dumps Valid Version with 166 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
