Refer to the exhibit.
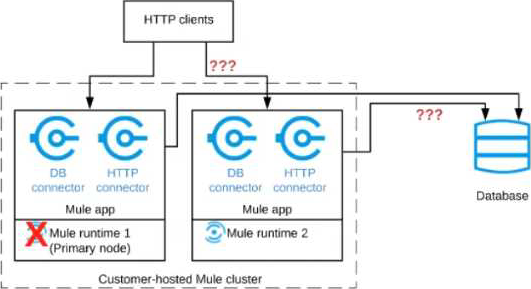
A Mule application is deployed to a cluster of two customer-hosted Mute runtimes. The Mute application has a flow that polls a database and another flow with an HTTP Listener. HTTP clients send HTTP requests directly to individual cluster nodes.
What happens to database polling and HTTP request handling in the time after the primary (master) node of the cluster has railed, but before that node is restarted?
A . Database polling continues Only HTTP requests sent to the remaining node continue to be accepted
B . Database polling stops All HTTP requests continue to be accepted
C . Database polling continues All HTTP requests continue to be accepted, but requests to the failed node Incur increased latency
D . Database polling stops All HTTP requests are rejected
Answer: A
Explanation:
Correct answer is Database polling continues Only HTTP requests sent to the remaining node continue to be accepted: Architecture descripted in the question could be described as follows. When node 1 is down, DB polling will still continue via node 2. Also requests which are coming directly to node 2 will also be accepted and processed in BAU fashion. Only thing that wont work is when requests are sent to Node 1 HTTP connector. The flaw with this architecture is HTTP clients are sending HTTP requests directly to individual cluster nodes. By default, clustering Mule runtime engines ensures high system availability. If a Mule runtime engine node becomes unavailable due to failure or planned downtime, another node in the cluster can assume the workload and continue to process existing events and messages
Latest MuleSoft Integration Architect I Dumps Valid Version with 244 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
