

A solution architect is considering a vSAN Cluster with two hosts per rack. The design should be configured to minimize the potential exposure to rack failure with the capacity to automatically restore compliance with the configured vSAN storage policy.
Which design consideration would minimize potential risks?
- A . Create four fault domains and failures to tolerate set to one with mirroring.
- B . Create four fault domains and failures to tolerate set to two with mirroring.
- C . Create four fault domains and failures to tolerate set to one with Erasure Coding.
- D . Create four fault domains and failures to tolerate set to two with Erasure Coding.
A company has reserved the last Saturday of the month to conduct server maintenance. An administrator is allowed to perform maintenance from 5 AM to 12 PM. During the upcoming maintenance window, the administrator will upgrade the controller driver, controller firmware, and vSphere version.
Environment details:
• vCenter is already at the latest version
• 5 node vSAN cluster
• The VMs are using a mix of RAID-0, RAID-1, and RAID-5 policies
• Each node is storing 20 TBs worth of VMs
Which maintenance mode option will allow an administrator to successfully perform the required upgrades, while ensuring all VMs remain online?
- A . Full data migration
- B . No Data Migration
- C . Ensure Accessibility
- D . Admission Control Enabled
A vSAN administrator wants to implement end-to-end prioritization of vSAN traffic across the network in a shared network infrastructure that is using vSphere Distributed Switches (VDS).
Which two can help achieve this objective? (Choose two.)
- A . Configure CoS or DSCP with high priority tag at the VDS and equivalent in the physical network.
- B . Enable jumbo frames for vSAN VMkernel ports and configure LACP for optimal load balancing.
- C . Enable Network I/O Control and allocate higher shares for vSAN traffic.
- D . Configure multiple vSAN VMkernel interfaces to load balance across multiple uplinks.
- E . Enable network resource pool at the VDS level to prioritize vSAN traffic
An infrastructure architect is submitting a proposal for a vSAN Cluster.
These are the customer’s requirements:
• Maximize the amount of usable capacity.
• Deduplication and compression will be enabled to help maximize usable capacity.
Which disk group configuration should the architect include in their design?
- A . One disk group with one flash device for cache and six flash devices for capacity.
- B . Three disk groups with one flash device for cache and two flash devices for capacity per disk group.
- C . Five disk groups with one flash device for cache and one magnetic device for capacity per disk group.
- D . One disk group with one flash device for cache and six magnetic devices for capacity.
An administrator observes this health check warning:
Controller firmware is VMware certified
They proceed to update the latest firmware on the Storage Controller. After a successful firmware upgrade, the same health check alert continues to display.
Which statement is true?
- A . Controller is not VMware certified and hence any firmware version displays a warning.
- B . The recently installed firmware is yet to be certified and included in VMware Compatibility Guide.
- C . The VMware vSAN Health Service needs to be restarted for changes to take effect.
- D . The alert can be ignored and silenced, since the firmware is newer than the recommended firmware.
B
Explanation:
Reference: https://kb.vmware.com/s/article/2150398
As part of a security strategy for data, a company has elected to migrate to a new KMS system.
Existing vSAN clusters are configured for Data At Rest Encryption. Considering the scenario, which statement is true?
- A . Full data evacuation will be required to use the new KMS system.
- B . Existing unencrypted datastores can be encrypted without data migration.
- C . Existing encrypted vSAN Clusters will need to be decrypted to use the new KMS system.
- D . Keys from the new KMS system can be applied without any data movement.
Which storage policy can be assigned to virtual machines In a 5-node, all flash vSAN cluster, to provide the highest level of redundancy?
- A . 2 failures – RAID-1 (Mirroring)
- B . 1 failure – RAID-5 (Erasure Coding)
- C . 2 failures – RAID-6 (Erasure Coding)
- D . 3 failures – RAID-1 (Mirroring)
Refer to the exhibit.


An administrator is managing a 4-node, hybrid vSAN cluster. One of the hosts in the cluster went offline.
Referencing the information displayed in the resyncing objects section of the vSAN UI, what is the current state of this cluster?
- A . Offline host reconnected to the cluster and all objects are synchronized.
- B . Objects will be resynchronized when the Object Repair Timer expires.
- C . Resync Throttling has caused data resynchronization scheduling.
- D . Metadata resynchronization is scheduled to occur every 60 minutes.
D
Explanation:
Reference: https://core.vmware.com/resource/vsan-2-node-guide#sec11-sub3
Which is true of the vSAN iSCSI target service?
- A . It is a VMware supported cost effective way to provide shared storage to another hypervisor.
- B . The vSAN default storage policy determines the characteristics of the vSAN iSCSI target service storage objects.
- C . Security is provided through the iSCSI CHAP & Mutual CHAP Authentication methods.
- D . It is a VMware supported solution to provide iSCSI targets to applications that require multiple connections per session (MCS).
Where would an administrator enable deduplication and compression in a vSAN environment?
- A . at the cluster level under vSAN services
- B . at the object level using storage policies
- C . at the host level using ESXCLI commands
- D . at the disk group level
A vSAN administrator is changing the number of stripes in the vSAN policy from 1 to 2 on a 3-node vSAN Cluster .
What is a possible impact of this policy change?
- A . Stripes will be placed on separate media, but does not guarantee separate hosts or disk groups.
- B . Policy cannot be applied as the cluster does not meet the minimum number of fault domains.
- C . The amount of raw capacity required to comply with this policy will double.
- D . The amount of raw capacity required to comply with this policy will decrease by half.
When designing a vSAN Cluster, which three should be considered when sizing a vSAN datastore? (Choose three.)
- A . Storage Policy or Policies to be used
- B . capacity device queue depth
- C . vSAN Slack Space
- D . cache disks with 10% of the Disk Group
- E . On-Disk Format overheard
- F . endurance level of capacity disk used
A,B,C
Explanation:
Reference: https://core.vmware.com/resource/vmware-vsan-design-guide
Which step can be avoided when replacing a capacity tier device on a controller with passthrough mode and support for hot-plug?
- A . Shut down the host.
- B . Add the new disk to the disk group.
- C . Replace the physical drive.
- D . Remove the disk from the disk group.
C
Explanation:
Reference: https://docs.vmware.com/en/VMware-vSphere/6.5/virtual-san-66-administration-guide.pdf (31)
Refer to the exhibit:
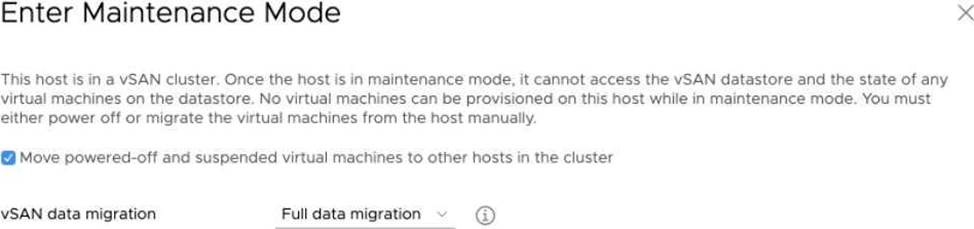

There are three hosts in a vSAN cluster. All virtual machines in the cluster are assigned a
storage policy with failures to tolerate set to 1 failure – RAID-1 (Mirroring) .
What is the result of placing a host in maintenance mode using the options shown in the image?
- A . The host will not enter maintenance mode. A general vSAN error is reported.
- B . The host will enter maintenance mode. A reduced redundancy warning is displayed.
- C . The host will enter maintenance mode. All powered-off and suspended VMs are migrated to other hosts.
- D . The host will not enter maintenance mode. The administrator is prompted to select a different data migration option.
An administrator arrives at work and begins their morning checks on a four node, all-flash vSAN Cluster. They notice the vSAN datastore reached 99% capacity due to a single node failure.
How can the administrator provide temporary relief?
- A . change FTT=1 with RAID-1 (Mirroring) to FTT=0 No data redundancy
- B . change FTT=1 with RAID-1 (Mirroring) to FTT=1 with RAID-5 (Erasure coding)
- C . change FTT=1 with RAID-5 (Erasure coding) to FTT=0 No data redundancy
- D . change FTT=1 with RAID-5 (Erasure coding) to FTT=1 with RAID-1 (Mirroring)
Reference the exhibit.
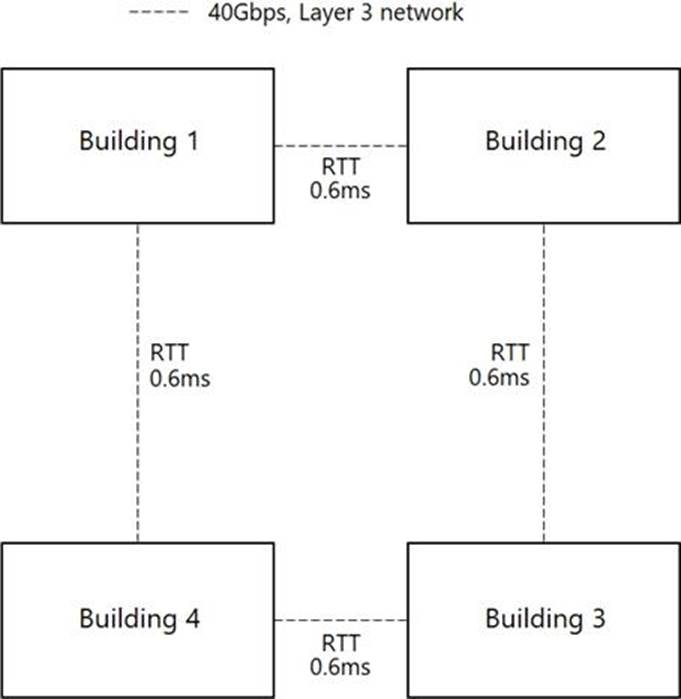

A university campus has a site topology illustrated in the exhibit. Adjacent connected buildings are connected with a single 40gb layer 3 network with a RTT of 0.6ms as depicted by each line. An architect wants to configure a fault domain in each building.
What would the architect need change in order to implement a fully supported vSAN Cluster?
- A . Enable a single Layer 2 network across all buildings for vSAN connectivity.
- B . Decrease the existing RTT between the existing links by 0.1ms or more.
- C . Add an additional link to the existing adjacent links to make it redundant.
- D . Enable IPv6 networks across all buildings for vSAN connectivity.
A customer has lost connectivity to one of their sites In a vSAN Stretched Cluster.
When connectivity is restored, what DRS setting will ensure VMs are not migrated back before resyncs are complete?
- A . DRS configured in Manual Mode
- B . DRS turned off
- C . DRS configured in Fully Automated mode
- D . DRS configured in Partially Automated mode
A failed storage controller has two vSAN disk groups attached. The components contained on the dnves in those disk groups are marked Degraded. vSAN reports that some objects do not comply with their assigned storage policy.
How is the compliance issue resolved?
- A . Initiate a proactive rebalance to force component repairs.
- B . Storage policies must be reapplied to all affected objects.
- C . Rebuilding of the degraded components starts immediately.
- D . Degraded components are repaired after CLOM Repair Delay Timer expires.
An administrator receives an alert for vCenter being unavailable. With vCenter running on vSAN, the administrator wants to know if any other VMs are impacted .
What command can an administrator run to determine the overall health of the vSAN objects?
- A . esxcli vsan errands timemachine get
- B . esxcli vsan storage list
- C . esxcli vsan cluster get
- D . esxcli vsan health cluster list
C
Explanation:
Reference: https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/products/vsan/vmwarevirtual-san-health-check-guide-6.1.pdf
During planned maintenance of a four-node vSAN cluster, an outsourced IT contractor accidentally removed a 2.5" SSD cache disk from one of the vSAN nodes. The storage policy has been configured with FTT=1 RAID 1, and the disk management UI marked the disk group as absent.
Which remediation steps should the administrator select to ensure VMs become compliant with the storage policy as soon as possible?
- A . replace the SSD cache disk > rescan > add disk back in disk group
- B . enter host in maintenance > remove from disk group > shutdown host > replace disk > power on host
- C . remove disk group > enter host in maintenance > fully evacuate all data > exit maintenance
- D . vSAN Health Check > retest > object health > repair objects immediately