Mulesoft MCIA-Level 1 MuleSoft Certified Integration Architect – Level 1 Online Training
Mulesoft MCIA-Level 1 Online Training
The questions for MCIA-Level 1 were last updated at Mar 29,2026.
- Exam Code: MCIA-Level 1
- Exam Name: MuleSoft Certified Integration Architect - Level 1
- Certification Provider: Mulesoft
- Latest update: Mar 29,2026
An insurance provider is implementing Anypoint platform to manage its application infrastructure and is using the customer hosted runtime for its business due to certain financial requirements it must meet. It has built a number of synchronous API’s and is currently hosting these on a mule runtime on one server
These applications make use of a number of components including heavy use of object stores and VM queues.
Business has grown rapidly in the last year and the insurance provider is starting to receive reports of reliability issues from its applications.
The DevOps team indicates that the API’s are currently handling too many requests and this is over loading the server. The team has also mentioned that there is a significant downtime when the server is down for maintenance.
As an integration architect, which option would you suggest to mitigate these issues?
- A . Add a load balancer and add additional servers in a server group configuration
- B . Add a load balancer and add additional servers in a cluster configuration
- C . Increase physical specifications of server CPU memory and network
- D . Change applications by use an event-driven model
An organization uses a set of customer-hosted Mule runtimes that are managed using the Mulesoft-hosted control plane.
What is a condition that can be alerted on from Anypoint Runtime Manager without any custom components or custom coding?
- A . When a Mule runtime on a given customer-hosted server is experiencing high memory consumption during certain periods
- B . When an SSL certificate used by one of the deployed Mule applications is about to expire
- C . When the Mute runtime license installed on a Mule runtime is about to expire
- D . When a Mule runtime’s customer-hosted server is about to run out of disk space
A
Explanation:
Correct answer is When a Mule runtime on a given customer-hosted server is experiencing high memory consumption during certain periods Using Anypoint Monitoring, you can configure two different types of alerts: Basic alerts for servers and Mule apps Limit per organization: Up to 50 basic alerts for users who do not have a Titanium subscription to Anypoint Platform You can set up basic alerts to trigger email notifications when a metric you are measuring passes a specified threshold. You can create basic alerts for the following metrics for servers or Mule apps:
For on-premises servers and CloudHub apps:
* CPU utilization
* Memory utilization
* Thread count Advanced alerts for graphs in custom dashboards in Anypoint Monitoring.
You must have a Titanium subscription to use this feature. Limit per organization: Up to 20 advanced alerts
What is an example of data confidentiality?
- A . Signing a file digitally and sending it using a file transfer mechanism
- B . Encrypting a file containing personally identifiable information (PV)
- C . Providing a server’s private key to a client for secure decryption of data during a two-way SSL handshake
- D . De-masking a person’s Social Security number while inserting it into a database
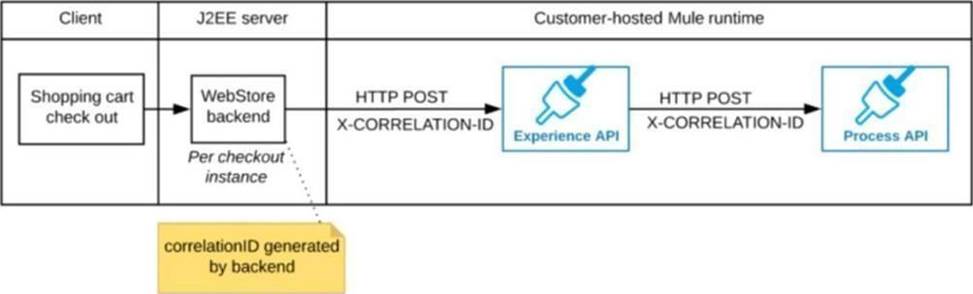
Refer to the exhibit.
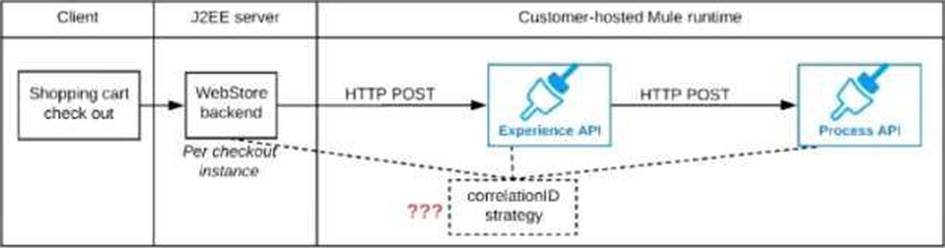
A shopping cart checkout process consists of a web store backend sending a sequence of API invocations to an Experience API, which in turn invokes a Process API. All API invocations are over HTTPS POST. The Java web store backend executes in a Java EE application server, while all API implementations are Mule applications executing in a customer -hosted Mule runtime.
End-to-end correlation of all HTTP requests and responses belonging to each individual checkout Instance is required. This is to be done through a common correlation ID, so that all log entries written by the web store backend, Experience API implementation, and Process API implementation include the same correlation ID for all requests and responses belonging to the same checkout instance.
What is the most efficient way (using the least amount of custom coding or configuration) for the web store backend and the implementations of the Experience API and Process API to participate in end-to-end correlation of the API invocations for each checkout instance?
A) The web store backend, being a Java EE application, automatically makes use of the thread-local correlation ID generated by the Java EE application server and automatically transmits that to the Experience API using HTTP-standard headers
No special code or configuration is included in the web store backend, Experience API, and Process API implementations to generate and manage the correlation ID
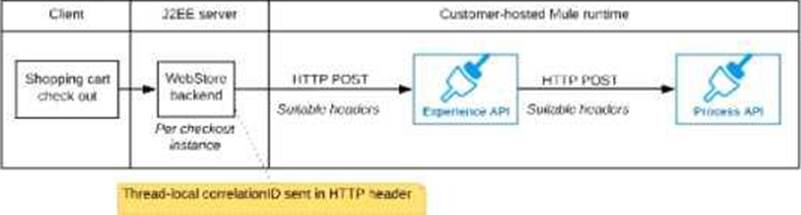
B) The web store backend generates a new correlation ID value at the start of checkout and sets it on the X-CORRELATlON-lt HTTP request header In each API invocation belonging to that checkout
No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID

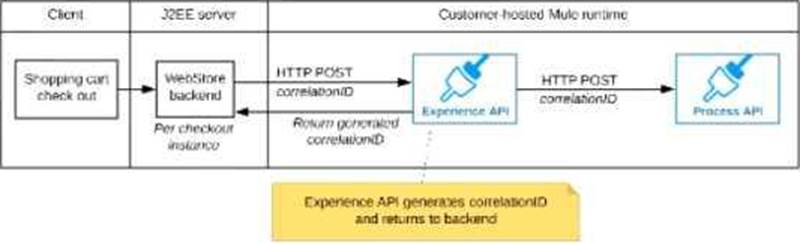
C) The Experience API implementation generates a correlation ID for each incoming HTTP request and passes it to the web store backend in the HTTP response, which includes it in all subsequent API invocations to the Experience API.
The Experience API implementation must be coded to also propagate the correlation ID to the Process API in a suitable HTTP request header
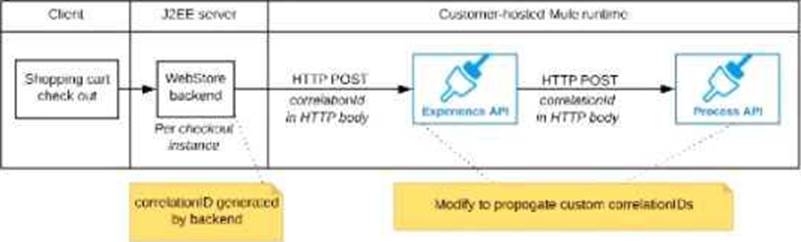
D) The web store backend sends a correlation ID value in the HTTP request body In the way required by the Experience API
The Experience API and Process API implementations must be coded to receive the custom correlation ID In the HTTP requests and propagate It in suitable HTTP request headers
- A . Option A
- B . Option B
- C . Option C
- D . Option D
B
Explanation:
Correct answer is "The web store backend generates a new correlation ID value at the start of checkout and sets it on the X¬CORRELATION-ID HTTP request header in each API invocation belonging to that checkout No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID" Explanation: By design, Correlation Ids cannot be changed within a flow in Mule 4 applications and can be set only at source. This ID is part of the Event Context and is generated as soon as the message is received by the application. When a HTTP Request is received, the request is inspected for "X-Correlation-Id" header. If "X-Correlation-Id" header is present, HTTP connector uses this as the Correlation Id. If "X-Correlation-Id" header is NOT present, a Correlation Id is randomly generated. For Incoming HTTP Requests: In order to set a custom Correlation Id, the client invoking the HTTP request must set "X-Correlation-Id" header. This will ensure that the Mule Flow uses this Correlation Id. For Outgoing HTTP Requests: You can also propagate the existing Correlation Id to downstream APIs. By default, all outgoing HTTP Requests send "X-Correlation-Id" header. However, you can choose to set a different value to "X-Correlation-Id" header or set "Send Correlation Id" to NEVER.
Mulesoft
Reference: https://help.mulesoft.com/s/article/How-to-Set-Custom-Correlation-Id-for-Flows-with-HTTP-Endpoint-in-Mule-4
Graphical user interface, application, Word
Description automatically generated
An organization has deployed runtime fabric on an eight note cluster with performance profile. An API uses and non persistent object store for maintaining some of its state data.
What will be the impact to the stale data if server crashes?
- A . State data is preserved
- B . State data is rolled back to a previously saved version
- C . State data is lost
- D . State data is preserved as long as more than one more is unaffected by the crash
Refer to the exhibit.

What is the type data format shown in the exhibit?
- A . JSON
- B . XML
- C . YAML
- D . CSV
According to MuleSoft’s recommended REST conventions, which HTTP method should an API use to specify how AP clients can request data from a specified resource?
- A . POST
- B . PUT
- C . PATCH
- D . GET
An organization is designing an integration Mule application to process orders by submitting them to a back-end system for offline processing. Each order will be received by the Mule application through an HTTPS POST and must be acknowledged immediately. Once acknowledged, the order will be submitted to a back-end system. Orders that cannot be successfully submitted due to rejections from the back-end system will need to be processed manually (outside the back-end system).
The Mule application will be deployed to a customer-hosted runtime and is able to use an existing ActiveMQ broker if needed. The ActiveMQ broker is located inside the organization’s firewall. The back-end system has a track record of unreliability due to both minor network connectivity issues and longer outages.
What idiomatic (used for their intended purposes) combination of Mule application components and ActiveMQ queues are required to ensure automatic submission of orders to the back-end system while supporting but minimizing manual order processing?
- A . An Until Successful scope to call the back-end system One or more ActiveMQ long-retry queues
One or more ActiveMQ dead-letter queues for manual processing - B . One or more On Error scopes to assist calling the back-end system An Until Successful scope containing VM components for long retries A persistent dead-letter VM queue configured in CloudHub
- C . One or more On Error scopes to assist calling the back-end system One or more ActiveMQ long-retry queues
A persistent dead-letter object store configured in the CloudHub Object Store service - D . A Batch Job scope to call the back-end system
An Until Successful scope containing Object Store components for long retries A dead-letter object store configured in the Mule application
A system API EmployeeSAPI is used to fetch employee’s data from an underlying SQL database.
The architect must design a caching strategy to query the database only when there is an update to the employees stable or else return a cached response in order to minimize the number of redundant transactions being handled by the database.
What must the architect do to achieve the caching objective?
- A . Use an On Table Row on employees table and call invalidate cache Use an object store caching strategy and expiration interval to empty
- B . Use a Scheduler with a fixed frequency every hour triggering an invalidate cache flow Use an object store caching strategy and expiration interval to empty
- C . Use a Scheduler with a fixed frequency every hour triggering an invalidate cache flow Use an object store caching strategy and set expiration interval to 1-hour
- D . Use an on table rule on employees table call invalidate cache and said new employees data to cache
Use an object store caching strategy and set expiration interval to 1-hour
Which Exchange asset type represents a complete API specification in RAML or OAS format?
- A . Connectors
- B . REST APIs
- C . API Spec Fragments
- D . SOAP APIs
Latest MCIA-Level 1 Dumps Valid Version with 79 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
