
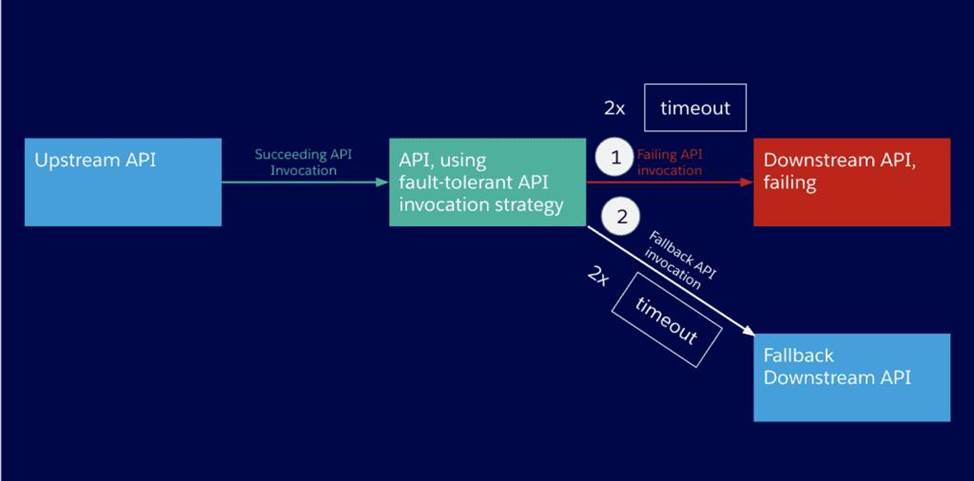
An API implementation is being designed that must invoke an Order API which is known to repeatedly experience downtime. For this reason a fallback API is to be called when the Order API is unavailable.
What approach to designing invocation of the fallback API provides the best resilience?
- A . Redirect client requests through an HTTP 303 temporary redirect status code to the fallback API whenever the Order API is unavailable
- B . Set an option in the HTTP Requester component that invokes the order API to instead invoke a fallback API whenever an HTTP 4XX or 5XX response status code is received from Order API
- C . Create a separate entry for the order API in API manager and then invoke this API as a fallback API if the primary Order API is unavailable
- D . Search Anypoint Exchange for a suitable existing fallback API and them implement invocations to their fallback API in addition to the Order API
A
Explanation:
* Resilience testing is a type of software testing that observes how applications act under stress. It’s meant to ensure the product’s ability to perform in chaotic conditions without a loss of core functions or data; it ensures a quick recovery after unforeseen, uncontrollable events.
* In case an API invocation fails ― even after a certain number of retries ― it might be adequate to invoke a different API as a fallback. A fallback API, by definition, will never be ideal for the purpose of the API client, otherwise it would be the primary API.
* Here are some examples for fallback APIs:
– An old, deprecated version of the same API.
– An alternative endpoint of the same API and version (e.g. API in another CloudHub region).
– An API doing more than required, and therefore not as performant as the primary API.
– An API doing less than required and therefore forcing the API Client to offer a degraded service, which is still better than no service at all.
* API clients implemented as Mule applications offer the ‘Until Successful Scope and Exception’ strategies at their disposal, which together allow configuring fallback actions such as a fallback API invocation.
* All HTTP response status codes within the 3xx category are considered redirection messages. These codes indicate to the user agent (i.e. your web browser) that an additional action is required in order to complete the request and access the desired resource

Diagram
Description automatically generated
Hence correct answer is Redirect client requests through an HTTP 303 temporary redirect status code to the fallback API whenever the Order API is unavailable
An organization has an HTTPS-enabled Mule application named Orders API that receives requests from another Mule application named Process Orders.
The communication between these two Mule applications must be secured by TLS mutual authentication (two-way TLS).
At a minimum, what must be stored in each truststore and keystore of these two Mule applications to properly support two-way TLS between the two Mule applications while properly protecting each Mule application’s keys?
- A . Orders API truststore: The Orders API public key
Process Orders keystore: The Process Orders private key and public key - B . Orders API truststore: The Orders API private key and public key
Process Orders keystore: The Process Orders private key public key - C . Orders API truststore: The Process Orders public key
Orders API keystore: The Orders API private key and public key
Process Orders truststore: The Orders API public key
Process Orders keystore: The Process Orders private key and public key - D . Orders API truststore: The Process Orders public key
Orders API keystore: The Orders API private key
Process Orders truststore: The Orders API public key
Process Orders keystore: The Process Orders private key
C
Explanation:
Reference: https://www.caeliusconsulting.com/blogs/one-way-and-two-way-tls-and-their-implementation-in-mulesoft/
As an enterprise architect, what are the two reasons for which you would use a canonical data model in the new integration project using Mulesoft Anypoint platform (choose two answers )
- A . To have consistent data structure aligned in processes
- B . To isolate areas within a bounded context
- C . To incorporate industry standard data formats
- D . There are multiple canonical definitions of each data type
- E . Because the model isolates the back and systems and support mule applications from change
Insurance organization is planning to deploy Mule application in MuleSoft Hosted runtime plane. As a part of requirement, application should be scalable. highly available. It also has regulatory requirement which demands logs to be retained for at least 2 years. As an Integration Architect what step you will recommend in order to achieve this?
- A . It is not possible to store logs for 2 years in CloudHub deployment. External log management system is required.
- B . When deploying an application to CloudHub, logs retention period should be selected as 2 years
- C . When deploying an application to CloudHub, worker size should be sufficient to store 2 years data
- D . Logging strategy should be configured accordingly in log4j file deployed with the application.
A
Explanation:
Correct answer is It is not possible to store logs for 2 years in CloudHub deployment. External log management system is required. CloudHub has a specific log retention policy, as described in the documentation: the platform stores logs of up to 100 MB per app & per worker or for up to 30 days, whichever limit is hit first. Once this limit has been reached, the oldest log information is deleted in chunks and is irretrievably lost. The recommended approach is to persist your logs to a external logging system of your choice (such as Splunk, for instance) using a log appender. Please note that this solution results in the logs no longer being stored on our platform, so any support cases you lodge will require for you to provide the appropriate logs for review and case resolution
A project uses Jenkins to implement CI/CD process. It was observed that each Mule package contains some of the Jenkins files and folders for configurations of CI/CD jobs.
As these files and folders are not part of the actual package, expectation is that these should not be part of deployed archive.
Which file can be used to exclude these files and folders from the deployed archive?
- A . muleignore
- B . _unTrackMule
- C . mulelnclude
- D . _muleExclude
As part of a growth strategy, a supplier signs a trading agreement with a large customer. The customer sends purchase orders to the supplier according to the ANSI X12 EDI standard, and the supplier creates the orders in its ERP system using the information in the EDI document.
The agreement also requires that the supplier provide a new RESTful API to process request from the customer for current product inventory level from the supplier’ s ERP system.
Which two fundamental integration use cases does the supplier need to deliver to provide an end-to-end solution for this business scenario? (Choose two.)
- A . Synchronized data transfer
- B . Sharing data with external partners
- C . User interface integration
- D . Streaming data ingestion
- E . Data mashups
A MuteSoft developer must implement an API as a Mule application, run the application locally, and execute unit tests against the Running application.
Which Anypoint Platform component can the developer use to full all of these requirements?
- A . API Manager
- B . API Designer
- C . Anypoint CLI
- D . Anypoint Studio
A global organization operates datacenters in many countries. There are private network links between these datacenters because all business data (but NOT metadata) must be exchanged over these private network connections.
The organization does not currently use AWS in any way.
The strategic decision has Just been made to rigorously minimize IT operations effort and investment going forward.
What combination of deployment options of the Anypoint Platform control plane and runtime plane(s) best serves this organization at the start of this strategic journey?
- A . MuleSoft-hosted Anypoint Platform control plane CloudHub Shared Worker Cloud in multiple AWS regions
- B . Anypoint Platform – Private Cloud Edition Customer-hosted runtime plane in each datacenter
- C . MuleSoft-hosted Anypoint Platform control plane Customer-hosted runtime plane in multiple AWS regions
- D . MuleSoft-hosted Anypoint Platform control plane Customer-hosted runtime plane in each datacenter
D
Explanation:
Correct answer is MuleSoft-hosted Anypoint Platform control plane Customer-hosted runtime plane in each datacenter There are two things to note about the question which can help us figure out correct answer.
* Business data must be exchanged over these private network connections which means we can not use MuleSoft provided Cloudhub option. So we are left with either customer hosted runtime in external cloud provider or customer hosted runtime in their own premises. As customer does not use AWS at the moment. Hence that don’t have the immediate option of using Customer-hosted runtime plane in multiple AWS regions. hence the most suitable option for runtime plane is Customer-hosted runtime plane in each datacenter
* Metadata has no limitation to reside in organization premises. Hence for control plane MuleSoft hosted Anypoint platform can be used as a strategic solution.
Hybrid is the best choice to start. Mule hosted Control plane and Customer hosted Runtime to start with.Once they mature in cloud migration, everything can be in Mule hosted.
A key Cl/CD capability of any enterprise solution is a testing framework to write and run repeatable tests.
Which component of Anypoint Platform provides the te6t automation capabilities for customers to use in their pipelines?
- A . Anypoint CLl
- B . Mule Maven Plugin
- C . Exchange Mocking Service
- D . MUnit
An automation engineer needs to write scripts to automate the steps of the API lifecycle, including steps to create, publish, deploy and manage APIs and their implementations in Anypoint Platform.
What Anypoint Platform feature can be used to automate the execution of all these actions in scripts in the easiest way without needing to directly invoke the Anypoint Platform REST APIs?
- A . Automated Policies in API Manager
- B . Runtime Manager agent
- C . The Mule Maven Plugin
- D . Anypoint CLI
D
Explanation:
Anypoint Platform provides a scripting and command-line tool for both Anypoint Platform and Anypoint Platform Private Cloud Edition (Anypoint Platform PCE). The command-line interface (CLI) supports both the interactive shell and standard CLI modes and works with: Anypoint Exchange Access management Anypoint Runtime Manager
An organization designing a hybrid, load balanced, single cluster production environment. Due to performance service level agreement goals, it is looking into running the Mule applications in an active-active multi node cluster configuration.
What should be considered when running its Mule applications in this type of environment?
- A . All event sources, regardless of time, can be configured as the target source by the primary node in the cluster
- B . An external load balancer is required to distribute incoming requests throughout the cluster nodes
- C . A Mule application deployed to multiple nodes runs in an isolation from the other nodes in the cluster
- D . Although the cluster environment is fully installed configured and running, it will not process any requests until an outage condition is detected by the primary node in the cluster.
Customer has deployed mule applications to different customer hosted mule run times.
Mule applications are managed from Anypoint platform.
What needs to be configured to monitor these Mule applications from Anypoint monitoring and what sends monitoring data to Anypoint monitoring?
- A . Enable monitoring of individual applications from runtime manager application settings Runtime manager agent sends monitoring data from the mule applications to Anypoint monitoring
- B . Install runtime manager agent on each mule runtime
Runtime manager agent since monitoring data from the mule applications to Anypoint monitoring - C . Anypoint monitoring agent on each mule runtime
Anypoint monitoring agent sends monitoring data from the mule applications to Anypoint monitoring - D . By default, Anypoint monitoring agent will be installed on each Mule run time
Anypoint Monitoring agent automatically sends monitoring data from the Mule applications to Anypoint monitoring
An organization has chosen Mulesoft for their integration and API platform.
According to the Mulesoft catalyst framework, what would an integration architect do to create achievement goals as part of their business outcomes?
- A . Measure the impact of the centre for enablement
- B . build and publish foundational assets
- C . agree upon KPI’s and help develop and overall success plan
- D . evangelize API’s
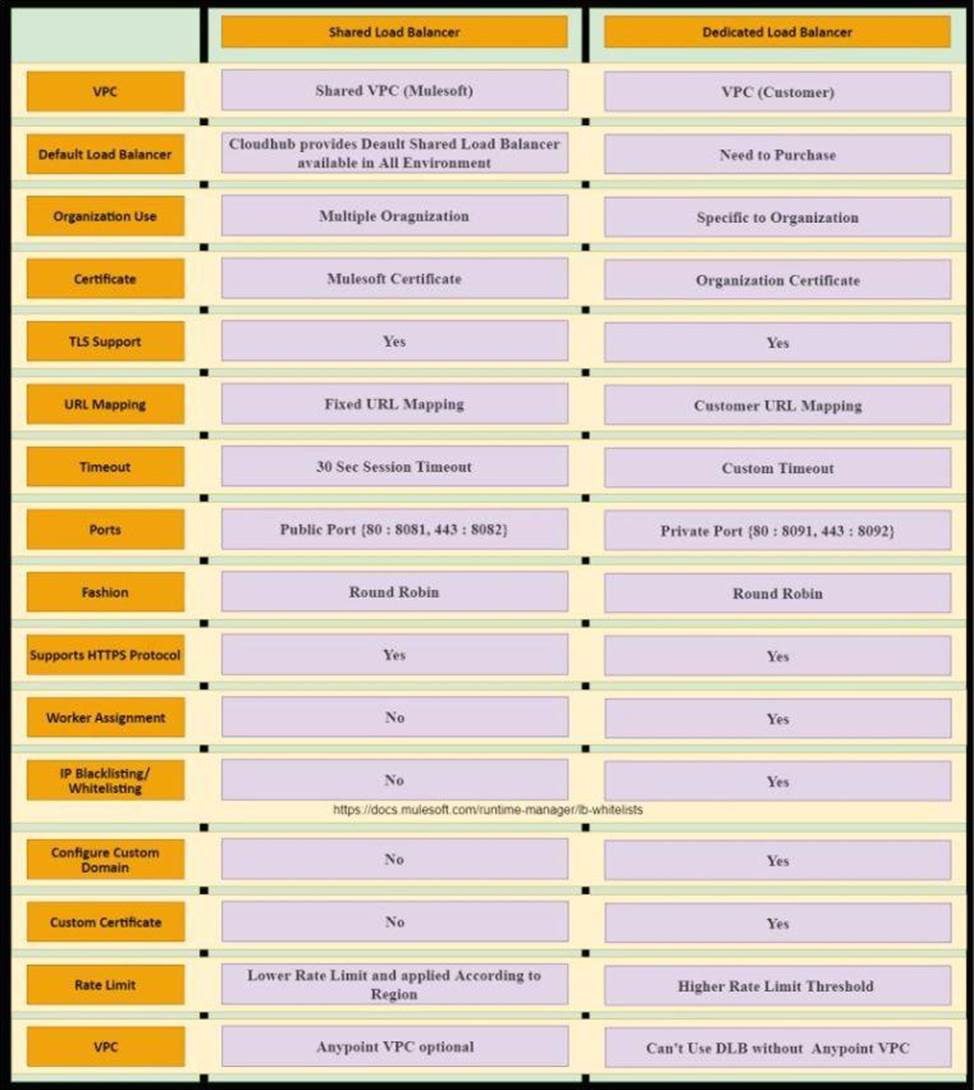
An organization is evaluating using the CloudHub shared Load Balancer (SLB) vs creating a CloudHub dedicated load balancer (DLB). They are evaluating how this choice affects the various types of certificates used by CloudHub deployed Mule applications, including MuleSoft-provided, customer-provided, or Mule application-provided certificates.
What type of restrictions exist on the types of certificates for the service that can be exposed by the CloudHub Shared Load Balancer (SLB) to external web clients over the public internet?
- A . Underlying Mule applications need to implement own certificates
- B . Only MuleSoft provided certificates can be used for server side certificate
- C . Only self signed certificates can be used
- D . All certificates which can be used in shared load balancer need to get approved by raising support ticket
B
Explanation:
Correct answer is Only MuleSoft provided certificates can be used for server side certificate
* The CloudHub Shared Load Balancer terminates TLS connections and uses its own server-side certificate.
* You would need to use dedicated load balancer which can enable you to define SSL configurations to provide custom certificates and optionally enforce two-way SSL client authentication.
* To use a dedicated load balancer in your environment, you must first create an Anypoint VPC. Because you can associate multiple environments with the same Anypoint VPC, you can use the same dedicated load balancer for your different environments.
Additional Info on SLB Vs DLB:

Table
Description automatically generated
An airline is architecting an API connectivity project to integrate its flight data into an online aggregation website. The interface must allow for secure communication high-performance and asynchronous message exchange.
What are suitable interface technologies for this integration assuming that Mulesoft fully supports these technologies and that Anypoint connectors exist for these interfaces?
- A . AsyncAPI over HTTPS AMQP with RabbitMQ JSON/REST over HTTPS
- B . XML over ActiveMQ XML over SFTP XML/REST over HTTPS
- C . CSV over FTP YAM L over TLS JSON over HTTPS
- D . SOAP over HTTPS HOP over TLS gRPC over HTTPS
An organization has defined a common object model in Java to mediate the communication between different Mule applications in a consistent way. A Mule application is being built to use this common object model to process responses from a SOAP API and a REST API and then write the processed results to an order management system.
The developers want Anypoint Studio to utilize these common objects to assist in creating mappings for various transformation steps in the Mule application.
What is the most idiomatic (used for its intended purpose) and performant way to utilize these common objects to map between the inbound and outbound systems in the Mule application?
- A . Use JAXB (XML) and Jackson (JSON) data bindings
- B . Use the WSS module
- C . Use the Java module
- D . Use the Transform Message component
A
Explanation:
Reference: https://docs.mulesoft.com/mule-runtime/3.9/understanding-mule-configuration
An organization is designing the following two Mule applications that must share data via a common persistent object store instance:
– Mule application P will be deployed within their on-premises datacenter.
– Mule application C will run on CloudHub in an Anypoint VPC.
The object store implementation used by CloudHub is the Anypoint Object Store v2 (OSv2).
What type of object store(s) should be used, and what design gives both Mule applications access to the same object store instance?
- A . Application P uses the Object Store connector to access a persistent object store Application C accesses this persistent object store via the Object Store REST API through an IPsec tunnel
- B . Application C and P both use the Object Store connector to access the Anypoint Object Store v2
- C . Application C uses the Object Store connector to access a persistent object Application P accesses the persistent object store via the Object Store REST API
- D . Application C and P both use the Object Store connector to access a persistent object store
C
Explanation:
Correct answer is Application A accesses the persistent object store via the Object Store REST API Application B uses the Object Store connector to access a persistent object
* Object Store v2 lets CloudHub applications store data and states across batch processes, Mule components and applications, from within an application or by using the Object Store REST API.
* On-premise Mule applications cannot use Object Store v2.
* You can select Object Store v2 as the implementation for Mule 3 and Mule 4 in CloudHub by checking the Object Store V2 checkbox in Runtime Manager at deployment time.
* CloudHub Mule
applications can use Object Store connector to write to the object store
* The only way on-premises Mule applications can access Object Store v2 is via the Object Store REST API.
* You can configure a Mule app to use the Object Store REST API to store and retrieve values from an object store in another Mule app.
What is true about automating interactions with Anypoint Platform using tools such as Anypoint Platform REST API’s, Anypoint CLI or the Mule Maven plugin?
- A . By default, the Anypoint CLI and Mule Maven plugin are not included in the Mule runtime
- B . Access to Anypoint Platform API;s and Anypoint CLI can be controlled separately thruough the roles and permissions in Anypoint platform, so that specific users can get access to Anypoint CLI while others get access to the platform API’s
- C . Anypoint Platform API’s can only automate interactions with CloudHub while the Mule
maven plugin is required for deployment to customer hosted Mule runtimes - D . API policies can be applied to the Anypoint platform API’s so that only certain LOS’s has access to specific functions
A
Explanation:
Correct answer is By default, the Anypoint CLI and Mule Maven plugin are not included in the Mule runtime Maven is not part of runtime though it is part of studio. You do not need it to deploy in order to deploy your app. Same is the case with CLI.
How does timeout attribute help inform design decisions while using JMS connector listening for incoming messages in an extended architecture (XA) transaction?
- A . After the timeout is exceeded, stale JMS consumer threads are destroyed and new threads are created
- B . The timeout specifies the time allowed to pass between receiving JMS messages on the same JMS connection and then after the timeout new JMS connection is established
- C . The time allowed to pass between committing the transaction and the completion of the mule flow and then after the timeout flow processing triggers an error
- D . The timeout defines the time that is allowed to pass without the transaction ending explicitly and after the timeout expires, the transaction rolls back
An organization is designing multiple new applications to run on CloudHub in a single Anypoint VPC and that must share data using a common persistent Anypoint object store V2 (OSv2).
Which design gives these mule applications access to the same object store instance?
- A . AVM connector configured to directly access the persistence queue of the persistent object store
- B . An Anypoint MQ connector configured to directly access the persistent object store
- C . Object store V2 can be shared across cloudhub applications with the configured osv2 connector
- D . The object store V2 rest API configured to access the persistent object store
In Anypoint Platform, a company wants to configure multiple identity providers (IdPs) for multiple lines of business (LOBs). Multiple business groups, teams, and environments have been defined for these LOBs.
What Anypoint Platform feature can use multiple IdPs across the company’s business groups, teams, and environments?
- A . MuleSoft-hosted (CloudHub) dedicated load balancers
- B . Client (application) management
- C . Virtual private clouds
- D . Permissions
A
Explanation:
To use a dedicated load balancer in your environment, you must first create an Anypoint VPC. Because you can associate multiple environments with the same Anypoint VPC, you can use the same dedicated load balancer for your different environments.
Reference: https://docs.mulesoft.com/runtime-manager/cloudhub-dedicated-load-balancer
A global, high-volume shopping Mule application is being built and will be deployed to CloudHub. To improve performance, the Mule application uses a Cache scope that maintains cache state in a CloudHub object store. Web clients will access the Mule application over HTTP from all around the world, with peak volume coinciding with business hours in the web client’s geographic location.
To achieve optimal performance, what Anypoint Platform region should be chosen for the CloudHub object store?
- A . Choose the same region as to where the Mule application is deployed
- B . Choose the US-West region, the only supported region for CloudHub object stores
- C . Choose the geographically closest available region for each web client
- D . Choose a region that is the traffic-weighted geographic center of all web clients
A
Explanation:
CloudHub object store should be in same region where the Mule application is deployed.
This will give optimal performance.
Before learning about Cache scope and object store in Mule 4 we understand what is in general Caching is and other related things. WHAT DOES “CACHING” MEAN?
Caching is the process of storing frequently used data in memory, file system or database which saves processing time and load if it would have to be accessed from original source location every time.
In computing, a cache is a high-speed data storage layer which stores a subset of data, so that future requests for that data are served up faster than is possible by accessing the data’s primary storage location. Caching allows you to efficiently reuse previously retrieved or computed data.
How does Caching work?
The data in a cache is generally stored in fast access hardware such as RAM (Random-access memory) and may also be used in correlation with a software component. A cache’s primary purpose is to increase data retrieval performance by reducing the need to access the underlying slower storage layer.
Caching in MULE 4
In Mule 4 caching can be achieved in mule using cache scope and/or object-store. Cache scope internally uses Object Store to store the data.
What is Object Store
Object Store lets applications store data and states across batch processes, Mule components, and applications, from within an application. If used on cloud hub, the object store is shared between applications deployed on Cluster. Cache Scope is used in below-mentioned cases:
Need to store the whole response from the outbound processor
Data returned from the outbound processor does not change very frequently
As Cache scope internally handle the cache hit and cache miss scenarios it is more readable
Object Store is used in below-mentioned cases:
Need to store custom/intermediary data
To store watermarks
Sharing the data/stage across applications, schedulers, batch.
If CloudHub object store is in same region where the Mule application is deployed it will aid in fast access of data and give optimal performance.
Refer to the exhibit.
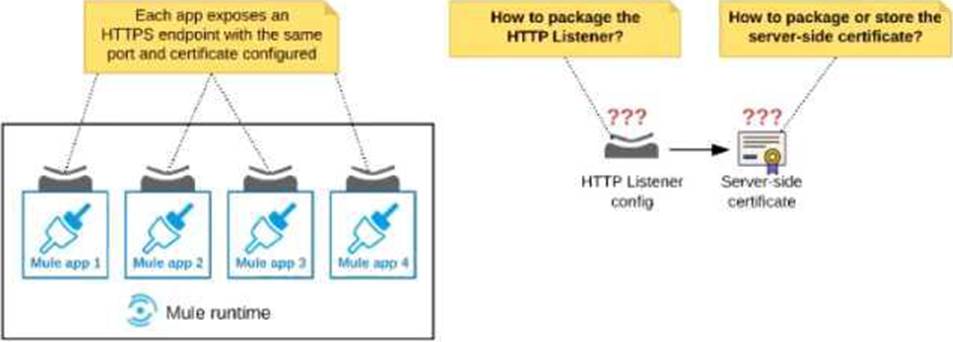

An organization deploys multiple Mule applications to the same customer -hosted Mule runtime. Many of these Mule applications must expose an HTTPS endpoint on the same port using a server-side certificate that rotates often.
What is the most effective way to package the HTTP Listener and package or store the server-side certificate when deploying these Mule applications, so the disruption caused by certificate rotation is minimized?
- A . Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint Package the server-side certificate in ALL Mule APPLICATIONS that need to expose an HTTPS endpoint
- B . Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint. Store the server-side certificate in a shared filesystem location in the Mule runtime’s classpath, OUTSIDE the Mule DOMAIN or any Mule APPLICATION
- C . Package an HTTPS Listener configuration In all Mule APPLICATIONS that need to expose an HTTPS endpoint Package the server-side certificate in a NEW Mule DOMAIN project
- D . Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing It from all Mule applications that need to expose an HTTPS endpoint. Package the server-side certificate in the SAME Mule DOMAIN project Go to Set
B
Explanation:
In this scenario, both A & C will work, but A is better as it does not require repackage to the domain project at all.
Correct answer is Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint. Store the server-side certificate in a shared filesystem location in the Mule runtime’s classpath, OUTSIDE the Mule DOMAIN or any Mule APPLICATION.
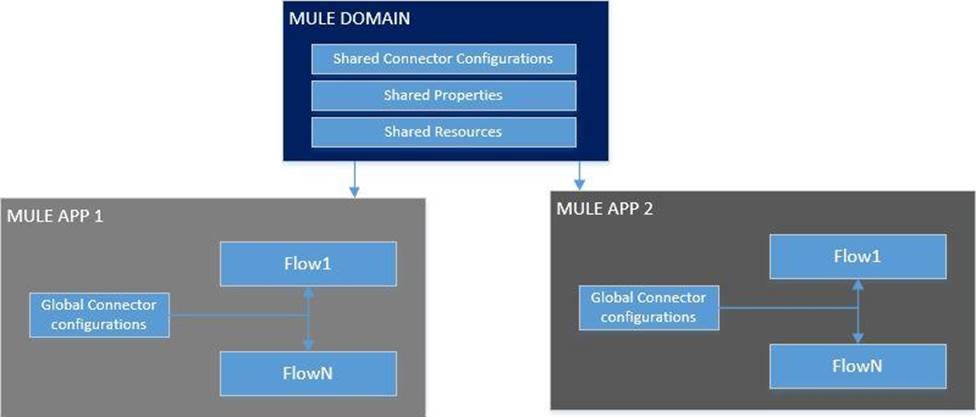
What is Mule Domain Project?
* A Mule Domain Project is implemented to configure the resources that are shared among different projects. These resources can be used by all the projects associated with this domain. Mule applications can be associated with only one domain, but a domain can be associated with multiple projects. Shared resources allow multiple development teams to work in parallel using the same set of reusable connectors. Defining these connectors as shared resources at the domain level allows the team to: – Expose multiple services within the domain through the same port. – Share the connection to persistent storage. – Share services between apps through a well-defined interface. – Ensure consistency between apps upon any changes because the configuration is only set in one place.
* Use domains Project to share the same host and port among multiple projects. You can declare the http connector within a domain project and associate the domain project with other projects. Doing this also allows to control thread settings, keystore configurations, time outs for all the requests made within multiple applications. You may think that one can also achieve this by duplicating the http connector configuration across all the applications. But, doing this may pose a nightmare if you have to make a change and redeploy all the applications.
* If you use connector configuration in the domain and let all the applications use the new domain instead of a default domain, you will maintain only one copy of the http connector configuration. Any changes will require only the domain to the redeployed instead of all the applications.
You can start using domains in only three steps:
1) Create a Mule Domain project
2) Create the global connector configurations which needs to be shared across the applications inside the Mule Domain project
3) Modify the value of domain in mule-deploy.properties file of the applications

Graphical user
interface
Description automatically generated
Use a certificate defined in already deployed Mule domain Configure the certificate in the domain so that the API proxy HTTPS Listener references it, and then deploy the secure API proxy to the target Runtime Fabric, or on-premises target. (CloudHub is not supported with this approach because it does not support Mule domains.)
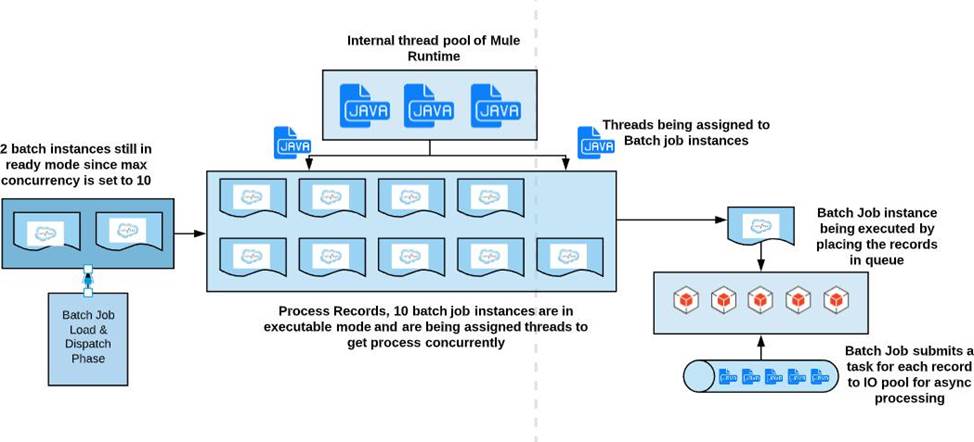
A Mule application contains a Batch Job with two Batch Steps (Batch_Step_l and Batch_Step_2). A payload with 1000 records is received by the Batch Job.
How many threads are used by the Batch Job to process records, and how does each Batch Step process records within the Batch Job?
- A . Each Batch Job uses SEVERAL THREADS for the Batch Steps Each Batch Step instance receives ONE record at a time as the payload, and RECORDS are processed IN PARALLEL within and between the two Batch Steps
- B . Each Batch Job uses a SINGLE THREAD for all Batch steps Each Batch step instance receives ONE record at a time as the payload, and RECORDS are processed IN ORDER, first through Batch_Step_l and then through Batch_Step_2
- C . Each Batch Job uses a SINGLE THREAD to process a configured block size of record Each Batch Step instance receives A BLOCK OF records as the payload, and BLOCKS of records are processed IN ORDER
- D . Each Batch Job uses SEVERAL THREADS for the Batch Steps Each Batch Step instance receives ONE record at a time as the payload, and BATCH STEP INSTANCES execute IN PARALLEL to process records and Batch Steps in ANY order as fast as possible
A
Explanation:
* Each Batch Job uses SEVERAL THREADS for the Batch Steps
* Each Batch Step instance receives ONE record at a time as the payload. It’s not received in a block, as it does not wait for multiple records to be completed before moving to next batch step. (So Option D is out of choice)
* RECORDS are processed IN PARALLEL within and between the two Batch Steps.
* RECORDS are not processed in order. Let’s say if second record completes
batch_step_1 before record 1, then it moves to batch_step_2 before record 1. (So option C and D are out of choice)
* A batch job is the scope element in an application in which Mule processes a message payload as a batch of records. The term batch job is inclusive of all three phases of
processing: Load and Dispatch, Process, and On Complete.
* A batch job instance is an occurrence in a Mule application whenever a Mule flow executes a batch job. Mule creates the batch job instance in the Load and Dispatch phase. Every batch job instance is identified internally using a unique String known as batch job instance id.

An Integration Mule application is being designed to synchronize customer data between two systems. One system is an IBM Mainframe and the other system is a Salesforce Marketing Cloud (CRM) instance. Both systems have been deployed in their typical configurations, and are to be invoked using the native protocols provided by Salesforce and IBM.
What interface technologies are the most straightforward and appropriate to use in this Mute application to interact with these systems, assuming that Anypoint Connectors exist that implement these interface technologies?
- A . IBM: DB access CRM: gRPC
- B . IBM: REST CRM:REST
- C . IBM: Active MQ CRM: REST
- D . IBM: CICS CRM: SOAP
D
Explanation:
Correct answer is IBM: CICS CRM: SOAP
* Within Anypoint Exchange, MuleSoft offers the IBM CICS connector. Anypoint Connector for IBM CICS Transaction Gateway (IBM CTG Connector) provides integration with back-end CICS apps using the CICS Transaction Gateway.
* Anypoint Connector for Salesforce Marketing Cloud (Marketing Cloud Connector) enables you to connect to the Marketing Cloud API web services (now known as the Marketing
Cloud API), which is also known as the Salesforce Marketing Cloud. This connector exposes convenient operations via SOAP for exploiting the capabilities of Salesforce Marketing Cloud.
A company is modernizing its legal systems lo accelerate access lo applications and data while supporting the adoption of new technologies. The key to achieving this business goal is unlocking the companies’ key systems and dala including microservices miming under Docker and kubernetes containers using apis.
Considering the current aggressive backlog and project delivery requirements the company wants to take a strategic approach in the first phase of its transformation projects by quickly deploying API’s in mule runtime that are able lo scale, connect to on premises systems and migrate as needed.
Which runtime deployment option supports company’s goals?
- A . Customer hosted self provisioned runtimes
- B . Cloudhub runtimes
- C . Runtime fabric on self managed Kubernetes
- D . Runtime fabric on Vmware metal
An integration team follows MuleSoft’s recommended approach to full lifecycle API development.
Which activity should this team perform during the API implementation phase?
- A . Validate the API specification
- B . Use the API specification to build the MuleSoft application
- C . Design the API specification
- D . Use the API specification to monitor the MuleSoft application
An organization is not meeting its growth and innovation objectives because IT cannot deliver projects last enough to keep up with the pace of change required by the business.
According to MuleSoft’s IT delivery and operating model, which step should the organization lake to solve this problem?
- A . Modify IT governance and security controls so that line of business developers can have direct access to the organization’s systems of record
- B . Switch from a design-first to a code-first approach for IT development
- C . Adopt a new approach that decouples core IT projects from the innovation that happens within each line of business
- D . Hire more |T developers, architects, and project managers to increase IT delivery
Mule application is deployed to Customer Hosted Runtime. Asynchronous logging was implemented to improved throughput of the system. But it was observed over the period of time that few of the important exception log messages which were used to rollback transactions are not working as expected causing huge loss to the Organization. Organization wants to avoid these losses. Application also has constraints due to which they cant compromise on throughput much.
What is the possible option in this case?
- A . Logging needs to be changed from asynchronous to synchronous
- B . External log appender needs to be used in this case
- C . Persistent memory storage should be used in such scenarios
- D . Mixed configuration of asynchronous or synchronous loggers should be used to log exceptions via synchronous way
D
Explanation:
Correct approach is to use Mixed configuration of asynchronous or synchronous loggers shoud be used to log exceptions via synchronous way Asynchronous logging poses a performance-reliability trade-off. You may lose some messages if Mule crashes before the logging buffers flush to the disk. In this case, consider that you can have a mixed configuration of asynchronous or synchronous loggers in your app. Best practice is to use asynchronous logging over synchronous with a minimum logging level of WARN for a production application. In some cases, enable INFO logging level when you need to confirm events such as successful policy installation or to perform troubleshooting. Configure your logging strategy by editing your application’s src/main/resources/log4j2.xml file
In a Mule Application, a flow contains two (2) JMS consume operations that are used to connect to a JMS broker and consume messages from two (2) JMS destination. The Mule application then joins the two JMS messages together.
The JMS broker does not implement high availability (HA) and periodically experiences scheduled outages of upto 10 mins for routine maintenance.
What is the most idiomatic (used for its intented purpose) way to build the mule flow so it can best recover from the expected outages?
- A . Configure a reconnection strategy for the JMS connector
- B . Enclose the two (2) JMS operation in an Until Successful scope
- C . Consider a transaction for the JMS connector
- D . Enclose the two (2) JMS operations in a Try scope with an Error Continue error handler
A
Explanation:
When an operation in a Mule application fails to connect to an external server, the default behavior is for the operation to fail immediately and return a connectivity error. You can modify this default behavior by configuring a reconnection strategy for the operation. You can configure a reconnection strategy for an operation either by modifying the operation properties or by modifying the configuration of the global element for the operation. The following are the available reconnection strategies and their behaviors: None Is the default behavior, which immediately returns a connectivity error if the attempt to connect is unsuccessful Standard (reconnect) Sets the number of reconnection attempts and the interval at which to execute them before returning a connectivity error Forever (reconnect-forever) Attempts to reconnect continually at a given interval
An organization is creating a set of new services that are critical for their business. The project team prefers using REST for all services but is willing to use SOAP with common WS-" standards if a particular service requires it.
What requirement would drive the team to use SOAP/WS-* for a particular service?
- A . Must use XML payloads for the service and ensure that it adheres to a specific schema
- B . Must publish and share the service specification (including data formats) with the consumers of the service
- C . Must support message acknowledgement and retry as part of the protocol
- D . Must secure the service, requiring all consumers to submit a valid SAML token
D
Explanation:
Security Assertion Markup Language (SAML) is an open standard that allows identity providers (IdP) to pass authorization credentials to service providers (SP).
SAML transactions use Extensible Markup Language (XML) for standardized communications between the identity provider and service providers.
SAML is the link between the authentication of a user’s identity and the authorization to use a service.
WS-Security is the key extension that supports many authentication models including:
basic username/password credentials, SAML, OAuth and more.
A common way that SOAP API’s are authenticated is via SAML Single Sign On (SSO). SAML works by facilitating the exchange of authentication and authorization credentials across applications. However, there is no specification that describes how to add SAML to REST web services.
Reference: https://www.oasis-open.org/committees/download.php/16768/wss-v1.1-spec-os-SAMLTokenProfile.pdf
An application load balancer routes requests to a RESTful web API secured by Anypoint Flex Gateway.
Which protocol is involved in the communication between the load balancer and the Gateway?
- A . SFTP
- B . HTTPS
- C . LDAP
- D . SMTP
A trading company handles millions of requests a day. Due to nature of its business, it requires excellent performance and reliability within its application.
For this purpose, company uses a number of event-based API’s hosted on various mule clusters that communicate across a shared message queue sitting within its network.
Which method should be used to meet the company’s requirement for its system?
- A . XA transactions and XA connected components
- B . JMS transactions
- C . JMS manual acknowledgements with a reliability pattern
- D . VM queues with reliability pattern
An XA transaction Is being configured that involves a JMS connector listening for Incoming JMS messages.
What is the meaning of the timeout attribute of the XA transaction, and what happens after the timeout expires?
- A . The time that is allowed to pass between committing the transaction and the completion of the Mule flow After the timeout, flow processing triggers an error
- B . The time that Is allowed to pass between receiving JMS messages on the same JMS connection After the timeout, a new JMS connection Is established
- C . The time that Is allowed to pass without the transaction being ended explicitly After the timeout, the transaction Is forcefully rolled-back
- D . The time that Is allowed to pass for state JMS consumer threads to be destroyed After the timeout, a new JMS consumer thread is created
C
Explanation:
* Setting a transaction timeout for the Bitronix transaction manager Set the transaction timeout either
C In wrapper.conf
C In CloudHub in the Properties tab of the Mule application deployment The default is 60 secs. It is defined as
mule.bitronix.transactiontimeout = 120
* This property defines the timeout for each transaction created for this manager.
If the transaction has not terminated before the timeout expires it will be automatically rolled back.
———————————————————————————————————————
Additional Info around Transaction Management:
Bitronix is available as the XA transaction manager for Mule applications
To use Bitronix, declare it as a global configuration element in the Mule application <bti:transaction-manager />
Each Mule runtime can have only one instance of a Bitronix transaction manager, which is shared by all Mule applications
For customer-hosted deployments, define the XA transaction manager in a Mule domain C Then share this global element among all Mule applications in the Mule runtime


Graphical user interface, table
Description automatically generated with medium confidence
As a part of design, Mule application is required call the Google Maps API to perform a distance computation. The application is deployed to cloudhub.
At the minimum what should be configured in the TLS context of the HTTP request configuration to meet these requirements?
- A . The configuration is built-in and nothing extra is required for the TLS context
- B . Request a private key from Google and create a PKCS12 file with it and add it in keyStore as a part of TLS context
- C . Download the Google public certificate from a browser, generate JKS file from it and add it in key store as a part of TLS context
- D . Download the Google public certificate from a browser, generate a JKS file from it and add it in Truststore as part of the TLS context
An organization has strict unit test requirement that mandate every mule application must have an MUnit test suit with a test case defined for each flow and a minimum test coverage of 80%.
A developer is building Munit test suit for a newly developed mule application that sends API request to an external rest API.
What is the effective approach for successfully executing the Munit tests of this new application while still achieving the required test coverage for the Munit tests?
- A . Invoke the external endpoint of the rest API from the mule floors
- B . Mark the rest API invocations in the Munits and then call the mocking service flow that simulates standard responses from the REST API
- C . Mock the rest API invocation in the Munits and return a mock response for those invocations
- D . Create a mocking service flow to simulate standard responses from the rest API and then configure the mule flows to call the marking service flow
An organization is choosing between API-led connectivity and other integration approaches.
According to MuleSoft, which business benefits is associated with an API-led connectivity approach using Anypoint Platform?
- A . improved security through adoption of monolithic architectures
- B . Increased developer productivity through sell-service of API assets
- C . Greater project predictability through tight coupling of systems
- D . Higher outcome repeatability through centralized development
A stock broking company makes use of CloudHub VPC to deploy Mule applications. Mule application needs to connect to a database application in the customers on-premises corporate data center and also to a Kafka cluster running in AWS VPC.
How is access enabled for the API to connect to the database application and Kafka cluster securely?
- A . Set up a transit gateway to the customers on-premises corporate datacenter to AWS VPC
- B . Setup AnyPoint VPN to the customer’s on-premise corporate data center and VPC peering with AWS VPC
- C . Setup VPC peering with AWS VPC and the customers devices corporate data center
- D . Setup VPC peering with the customers onto my service corporate data center and Anypoint VPN to AWS VPC
What Anypoint Connectors support transactions?
- A . Database, JMS, VM
- B . Database, 3MS, HTTP
- C . Database, JMS, VM, SFTP
- D . Database, VM, File
A
Explanation:
Below Anypoint Connectors support transactions JMS C Publish C Consume VM C Publish C Consume Database C All operations
An integration Mule application is deployed to a customer-hosted multi-node Mule 4 runtime duster. The Mule application uses a Listener operation of a JMS connector to receive incoming messages from a JMS queue.
How are the messages consumed by the Mule application?
- A . Depending on the JMS provider’s configuration, either all messages are consumed by ONLY the primary cluster node or else ALL messages are consumed by ALL cluster nodes
- B . Regardless of the Listener operation configuration, all messages are consumed by ALL cluster nodes
- C . Depending on the Listener operation configuration, either all messages are consumed by ONLY the primary cluster node or else EACH message is consumed by ANY ONE cluster node
- D . Regardless of the Listener operation configuration, all messages are consumed by ONLY the primary cluster node
C
Explanation:
Correct answer is Depending on the Listener operation configuration, either all messages are consumed by ONLY the primary cluster node or else EACH message is consumed by ANY ONE cluster node
For applications running in clusters, you have to keep in mind the concept of primary node and how the connector will behave. When running in a cluster, the JMS listener default behavior will be to receive messages only in the primary node, no matter what kind of destination you are consuming from. In case of consuming messages from a Queue, you’ll want to change this configuration to receive messages in all the nodes of the cluster, not just the primary.
This can be done with the primaryNodeOnly parameter:
<jms:listener config-ref="config" destination="${inputQueue}" primaryNodeOnly="false"/>
An insurance provider is implementing Anypoint platform to manage its application infrastructure and is using the customer hosted runtime for its business due to certain financial requirements it must meet. It has built a number of synchronous API’s and is currently hosting these on a mule runtime on one server
These applications make use of a number of components including heavy use of object stores and VM queues.
Business has grown rapidly in the last year and the insurance provider is starting to receive reports of reliability issues from its applications.
The DevOps team indicates that the API’s are currently handling too many requests and this is over loading the server. The team has also mentioned that there is a significant downtime when the server is down for maintenance.
As an integration architect, which option would you suggest to mitigate these issues?
- A . Add a load balancer and add additional servers in a server group configuration
- B . Add a load balancer and add additional servers in a cluster configuration
- C . Increase physical specifications of server CPU memory and network
- D . Change applications by use an event-driven model
An organization uses a set of customer-hosted Mule runtimes that are managed using the Mulesoft-hosted control plane.
What is a condition that can be alerted on from Anypoint Runtime Manager without any custom components or custom coding?
- A . When a Mule runtime on a given customer-hosted server is experiencing high memory consumption during certain periods
- B . When an SSL certificate used by one of the deployed Mule applications is about to expire
- C . When the Mute runtime license installed on a Mule runtime is about to expire
- D . When a Mule runtime’s customer-hosted server is about to run out of disk space
A
Explanation:
Correct answer is When a Mule runtime on a given customer-hosted server is experiencing high memory consumption during certain periods Using Anypoint Monitoring, you can configure two different types of alerts: Basic alerts for servers and Mule apps Limit per organization: Up to 50 basic alerts for users who do not have a Titanium subscription to Anypoint Platform You can set up basic alerts to trigger email notifications when a metric you are measuring passes a specified threshold. You can create basic alerts for the following metrics for servers or Mule apps:
For on-premises servers and CloudHub apps:
* CPU utilization
* Memory utilization
* Thread count Advanced alerts for graphs in custom dashboards in Anypoint Monitoring.
You must have a Titanium subscription to use this feature. Limit per organization: Up to 20 advanced alerts
What is an example of data confidentiality?
- A . Signing a file digitally and sending it using a file transfer mechanism
- B . Encrypting a file containing personally identifiable information (PV)
- C . Providing a server’s private key to a client for secure decryption of data during a two-way SSL handshake
- D . De-masking a person’s Social Security number while inserting it into a database
Refer to the exhibit.
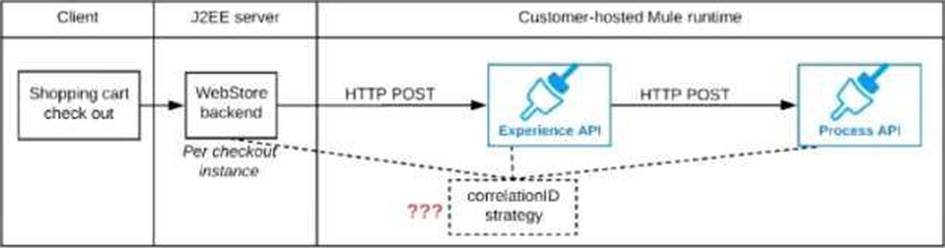

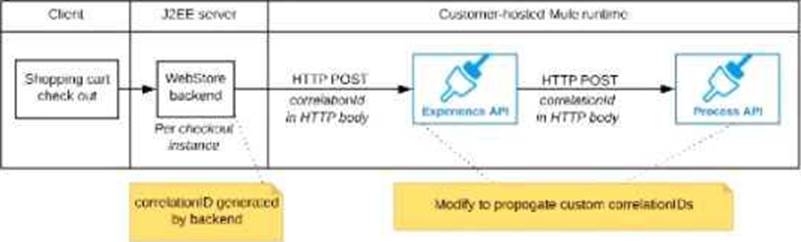
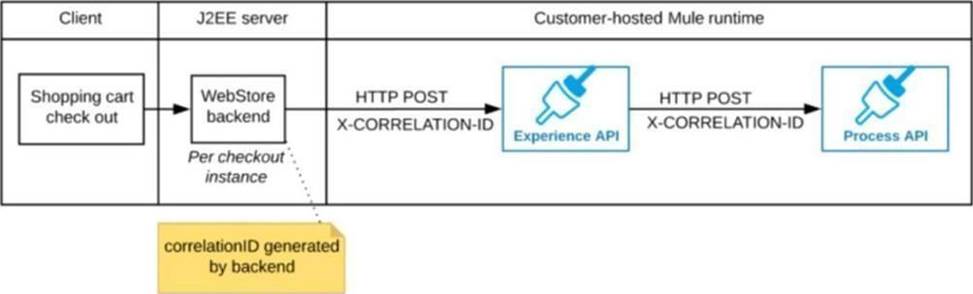
A shopping cart checkout process consists of a web store backend sending a sequence of API invocations to an Experience API, which in turn invokes a Process API. All API invocations are over HTTPS POST. The Java web store backend executes in a Java EE application server, while all API implementations are Mule applications executing in a customer -hosted Mule runtime.
End-to-end correlation of all HTTP requests and responses belonging to each individual checkout Instance is required. This is to be done through a common correlation ID, so that all log entries written by the web store backend, Experience API implementation, and Process API implementation include the same correlation ID for all requests and responses belonging to the same checkout instance.
What is the most efficient way (using the least amount of custom coding or configuration) for the web store backend and the implementations of the Experience API and Process API to participate in end-to-end correlation of the API invocations for each checkout instance?
A) The web store backend, being a Java EE application, automatically makes use of the thread-local correlation ID generated by the Java EE application server and automatically transmits that to the Experience API using HTTP-standard headers
No special code or configuration is included in the web store backend, Experience API, and Process API implementations to generate and manage the correlation ID
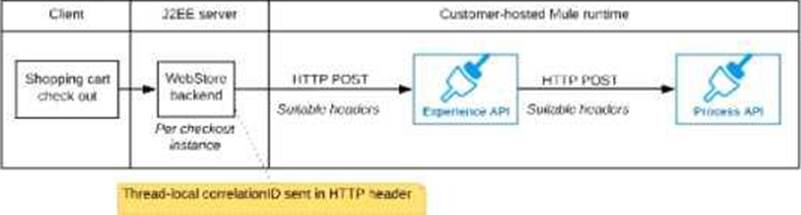

B) The web store backend generates a new correlation ID value at the start of checkout and sets it on the X-CORRELATlON-lt HTTP request header In each API invocation belonging to that checkout
No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID


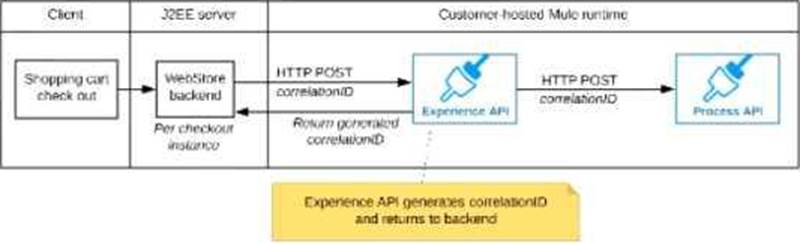
C) The Experience API implementation generates a correlation ID for each incoming HTTP request and passes it to the web store backend in the HTTP response, which includes it in all subsequent API invocations to the Experience API.
The Experience API implementation must be coded to also propagate the correlation ID to the Process API in a suitable HTTP request header
D) The web store backend sends a correlation ID value in the HTTP request body In the way required by the Experience API
The Experience API and Process API implementations must be coded to receive the custom correlation ID In the HTTP requests and propagate It in suitable HTTP request headers

- A . Option A
- B . Option B
- C . Option C
- D . Option D
B
Explanation:
Correct answer is "The web store backend generates a new correlation ID value at the start of checkout and sets it on the X¬CORRELATION-ID HTTP request header in each API invocation belonging to that checkout No special code or configuration is included in the Experience API and Process API implementations to generate and manage the correlation ID" Explanation: By design, Correlation Ids cannot be changed within a flow in Mule 4 applications and can be set only at source. This ID is part of the Event Context and is generated as soon as the message is received by the application. When a HTTP Request is received, the request is inspected for "X-Correlation-Id" header. If "X-Correlation-Id" header is present, HTTP connector uses this as the Correlation Id. If "X-Correlation-Id" header is NOT present, a Correlation Id is randomly generated. For Incoming HTTP Requests: In order to set a custom Correlation Id, the client invoking the HTTP request must set "X-Correlation-Id" header. This will ensure that the Mule Flow uses this Correlation Id. For Outgoing HTTP Requests: You can also propagate the existing Correlation Id to downstream APIs. By default, all outgoing HTTP Requests send "X-Correlation-Id" header. However, you can choose to set a different value to "X-Correlation-Id" header or set "Send Correlation Id" to NEVER.
Mulesoft
Reference: https://help.mulesoft.com/s/article/How-to-Set-Custom-Correlation-Id-for-Flows-with-HTTP-Endpoint-in-Mule-4

Graphical user interface, application, Word
Description automatically generated
An organization has deployed runtime fabric on an eight note cluster with performance profile. An API uses and non persistent object store for maintaining some of its state data.
What will be the impact to the stale data if server crashes?
- A . State data is preserved
- B . State data is rolled back to a previously saved version
- C . State data is lost
- D . State data is preserved as long as more than one more is unaffected by the crash
Refer to the exhibit.


What is the type data format shown in the exhibit?
- A . JSON
- B . XML
- C . YAML
- D . CSV
According to MuleSoft’s recommended REST conventions, which HTTP method should an API use to specify how AP clients can request data from a specified resource?
- A . POST
- B . PUT
- C . PATCH
- D . GET
An organization is designing an integration Mule application to process orders by submitting them to a back-end system for offline processing. Each order will be received by the Mule application through an HTTPS POST and must be acknowledged immediately. Once acknowledged, the order will be submitted to a back-end system. Orders that cannot be successfully submitted due to rejections from the back-end system will need to be processed manually (outside the back-end system).
The Mule application will be deployed to a customer-hosted runtime and is able to use an existing ActiveMQ broker if needed. The ActiveMQ broker is located inside the organization’s firewall. The back-end system has a track record of unreliability due to both minor network connectivity issues and longer outages.
What idiomatic (used for their intended purposes) combination of Mule application components and ActiveMQ queues are required to ensure automatic submission of orders to the back-end system while supporting but minimizing manual order processing?
- A . An Until Successful scope to call the back-end system One or more ActiveMQ long-retry queues
One or more ActiveMQ dead-letter queues for manual processing - B . One or more On Error scopes to assist calling the back-end system An Until Successful scope containing VM components for long retries A persistent dead-letter VM queue configured in CloudHub
- C . One or more On Error scopes to assist calling the back-end system One or more ActiveMQ long-retry queues
A persistent dead-letter object store configured in the CloudHub Object Store service - D . A Batch Job scope to call the back-end system
An Until Successful scope containing Object Store components for long retries A dead-letter object store configured in the Mule application
A system API EmployeeSAPI is used to fetch employee’s data from an underlying SQL database.
The architect must design a caching strategy to query the database only when there is an update to the employees stable or else return a cached response in order to minimize the number of redundant transactions being handled by the database.
What must the architect do to achieve the caching objective?
- A . Use an On Table Row on employees table and call invalidate cache Use an object store caching strategy and expiration interval to empty
- B . Use a Scheduler with a fixed frequency every hour triggering an invalidate cache flow Use an object store caching strategy and expiration interval to empty
- C . Use a Scheduler with a fixed frequency every hour triggering an invalidate cache flow Use an object store caching strategy and set expiration interval to 1-hour
- D . Use an on table rule on employees table call invalidate cache and said new employees data to cache
Use an object store caching strategy and set expiration interval to 1-hour
Which Exchange asset type represents a complete API specification in RAML or OAS format?
- A . Connectors
- B . REST APIs
- C . API Spec Fragments
- D . SOAP APIs
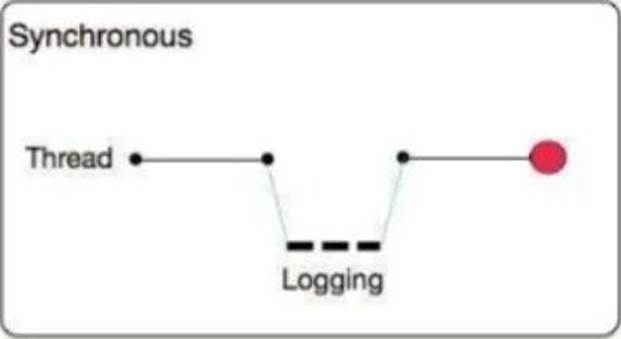
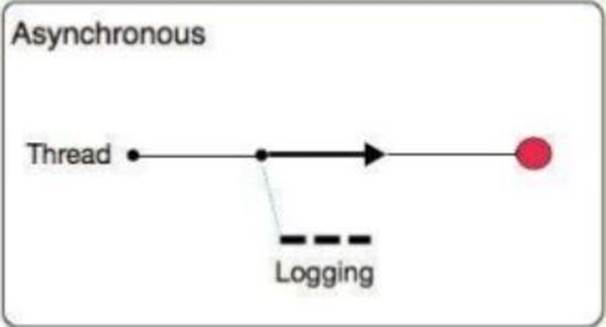
What is a key difference between synchronous and asynchronous logging from Mule applications?
- A . Synchronous logging writes log messages in a single logging thread but does not block the Mule event being processed by the next event processor
- B . Asynchronous logging can improve Mule event processing throughput while also reducing the processing time for each Mule event
- C . Asynchronous logging produces more reliable audit trails with more accurate timestamps
- D . Synchronous logging within an ongoing transaction writes log messages in the same thread that processes the current Mule event
B
Explanation:
Types of logging:
A) Synchronous: The execution of thread that is processing messages is interrupted to wait for the log message to be fully handled before it can continue.
The execution of the thread that is processing your message is interrupted to wait for the log message to be fully output before it can continue
Performance degrades because of synchronous logging
Used when the log is used as an audit trail or when logging ERROR/CRITICAL messages If the logger fails to write to disk, the exception would raise on the same thread that’s currently processing the Mule event. If logging is critical for you, then you can rollback the transaction.

Chart, diagram
Description automatically generated

Chart, diagram,
box and whisker chart
Description automatically generated
B) Asynchronous:
The logging operation occurs in a separate thread, so the actual processing of your message won’t be delayed to wait for the logging to complete
Substantial improvement in throughput and latency of message processing
Mule runtime engine (Mule) 4 uses Log4j 2 asynchronous logging by default
The disadvantage of asynchronous logging is error handling.
If the logger fails to write to disk, the thread doing the processing won’t be aware of any issues writing to the disk, so you won’t be able to rollback anything. Because the actual writing of the log gets differed, there’s a chance that log messages might never make it to disk and get lost, if Mule were to crash before the buffers are flushed.
——————————————————————————————————————
So Correct answer is: Asynchronous logging can improve Mule event processing throughput while also reducing the processing time for each Mule event
An organization is designing Mule application which connects to a legacy backend. It has been reported that backend services are not highly available and experience downtime quite often.
As an integration architect which of the below approach you would propose to achieve high reliability goals?
- A . Alerts can be configured in Mule runtime so that backend team can be communicated when services are down
- B . Until Successful scope can be implemented while calling backend API’s
- C . On Error Continue scope to be used to call in case of error again
- D . Create a batch job with all requests being sent to backend using that job as per the availability of backend API’s
B
Explanation:
Correct answer is Untill Successful scope can be implemented while calling backend API’s The Until Successful scope repeatedly triggers the scope’s components (including flow references) until they all succeed or until a maximum number of retries is exceeded The scope provides option to control the max number of retries and the interval between retries The scope can execute any sequence of processors that may fail for whatever reason and may succeed upon retry
According to MuleSoft’s IT delivery and operating model, which approach can an organization adopt in order to reduce the frequency of IT project delivery failures?
- A . Decouple central IT projects from the innovation that happens within each line of business
- B . Adopt an enterprise data model
- C . Prevent technology sprawl by reducing production of API assets
- D . Stop scope creep by centralizing requirements-gathering
Which component of Anypoint platform belongs to the platform control plane?
- A . Runtime Fabric
- B . Runtime Replica
- C . Anypoint Connectors
- D . API Manager
When the mule application using VM is deployed to a customer-hosted cluster or multiple cloudhub workers, how are messages consumed by the Mule engine?
- A . in non-deterministic way
- B . by starting an XA transaction for each new message
- C . in a deterministic way
- D . the primary only in order to avoid duplicate processing
Refer to the exhibit.
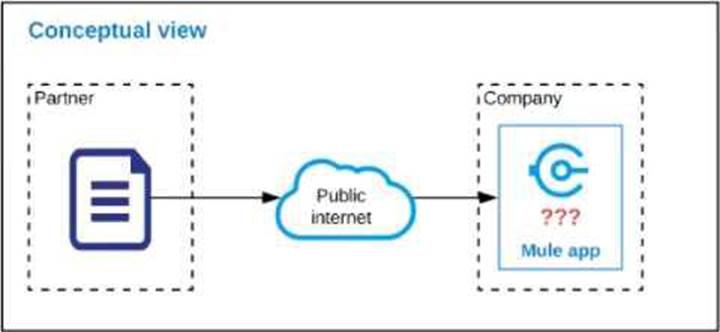

An organization is designing a Mule application to receive data from one external business partner. The two companies currently have no shared IT infrastructure and do not want to establish one. Instead, all communication should be over the public internet (with no VPN).
What Anypoint Connector can be used in the organization’s Mule application to securely receive data from this external business partner?
- A . File connector
- B . VM connector
- C . SFTP connector
- D . Object Store connector
C
Explanation:
* Object Store and VM Store is used for sharing data inter or intra mule applications in same setup. Can’t be used with external Business Partner
* Also File connector will not be useful as the two companies currently have no shared IT infrastructure. It’s specific for local use.
* Correct answer is SFTP connector. The SFTP Connector implements a secure file transport channel so that your Mule application can exchange files with external resources.
SFTP uses the SSH security protocol to transfer messages. You can implement the SFTP endpoint as an inbound endpoint with a one-way exchange pattern, or as an outbound endpoint configured for either a one-way or request-response exchange pattern.
A Mule application is synchronizing customer data between two different database systems.
What is the main benefit of using XA transaction over local transactions to synchronize these two database system?
- A . Reduce latency
- B . Increase throughput
- C . Simplifies communincation
- D . Ensure consistency
D
Explanation:
* XA transaction add tremendous latency so "Reduce Latency" is incorrect option XA transactions define "All or No" commit protocol.
* Each local XA resource manager supports the A.C.I.D properties (Atomicity, Consistency, Isolation, and Durability).
———————————————————————————————————————
So correct choice is "Ensure consistency"
Reference: https://docs.mulesoft.com/mule-runtime/4.3/xa-transactions
A company is planning to migrate its deployment environment from on-premises cluster to a Runtime Fabric (RTF) cluster. It also has a requirement to enable Mule applications deployed to a Mule runtime instance to store and share data across application replicas and restarts.
How can these requirements be met?
- A . Anypoint object store V2 to share data between replicas in the RTF cluster
- B . Install the object store pod on one of the cluster nodes
- C . Configure Persistence Gateway in any of the servers using Mule Object Store
- D . Configure Persistent Gateway at the RTF
A Mule application uses the Database connector.
What condition can the Mule application automatically adjust to or recover from without needing to restart or redeploy the Mule application?
- A . One of the stored procedures being called by the Mule application has been renamed
- B . The database server was unavailable for four hours due to a major outage but is now fully operational again
- C . The credentials for accessing the database have been updated and the previous credentials are no longer valid
- D . The database server has been updated and hence the database driver library/JAR needs a minor version upgrade
B
Explanation:
* Any change in the application will require a restart except when the issue outside the app. For below situations, you would need to redeploy the code after doing necessary changes — One of the stored procedures being called by the Mule application has been renamed. In this case, in the Mule application you will have to do changes to accommodate the new stored procedure name.
— Required redesign of Mule applications to follow microservice architecture principles. As code is changed, deployment is must
— If the credentials changed and you need to update the connector or the properties. — The credentials for accessing the database have been updated and the previous credentials are no longer valid. In this situation you need to restart or redeploy depending on how credentials are configured in Mule application.
* So Correct answer is The database server was unavailable for four hours due to a major outage but is now fully operational again as this is the only external issue to application.
An organization has several APIs that accept JSON data over HTTP POST. The APIs are all publicly available and are associated with several mobile applications and web applications. The organization does NOT want to use any authentication or compliance policies for these APIs, but at the same time, is worried that some bad actor could send payloads that could somehow compromise the applications or servers running the API implementations.
What out-of-the-box Anypoint Platform policy can address exposure to this threat?
- A . Apply a Header injection and removal policy that detects the malicious data before it is used
- B . Apply an IP blacklist policy to all APIs; the blacklist will Include all bad actors
- C . Shut out bad actors by using HTTPS mutual authentication for all API invocations
- D . Apply a JSON threat protection policy to all APIs to detect potential threat vectors
D
Explanation:
We need to note few things about the scenario which will help us in reaching the correct solution.
Point 1: The APIs are all publicly available and are associated with several mobile applications and web applications. This means Apply an IP blacklist policy is not viable option. as blacklisting IPs is limited to partial web traffic. It can’t be useful for traffic from mobile application
Point 2: The organization does NOT want to use any authentication or compliance policies for these APIs. This means we can not apply HTTPS mutual authentication scheme. Header injection or removal will not help the purpose.
By its nature, JSON is vulnerable to JavaScript injection. When you parse the JSON object, the malicious code inflicts its damages. An inordinate increase in the size and depth of the JSON payload can indicate injection. Applying the JSON threat protection policy can limit the size of your JSON payload and thwart recursive additions to the JSON hierarchy. Hence correct answer is Apply a JSON threat protection policy to all APIs to detect potential threat vectors
What API policy would LEAST likely be applied to a Process API?
- A . Custom circuit breaker
- B . Client ID enforcement
- C . Rate limiting
- D . JSON threat protection
D
Explanation:
Key to this question lies in the fact that Process API are not meant to be accessed directly by clients. Lets analyze options one by one. Client ID enforcement: This is applied at process API level generally to ensure that identity of API clients is always known and available for API-based analytics Rate Limiting: This policy is applied on Process Level API to secure API’s against degradation of service that can happen in case load received is more than it can handle Custom circuit breaker: This is also quite useful feature on process level API’s as it saves the API client the wasted time and effort of invoking a failing API. JSON threat protection: This policy is not required at Process API and rather implemented as Experience API’s. This policy is used to safeguard application from malicious attacks by injecting malicious code in JSON object. As ideally Process API’s are never called from external world, this policy is never used on Process API’s Hence correct answer is JSON threat protection MuleSoft Documentation
Reference: https://docs.mulesoft.com/api-manager/2.x/policy-mule3-json-threat
An IT integration tram followed an API-led connectivity approach to implement an order-fulfillment business process. It created an order processing AP that coordinates stateful interactions with a variety of microservices that validate, create, and fulfill new product orders
Which interaction composition pattern did the integration architect who designed this order processing AP| use?
- A . Orchestration
- B . Streaming
- C . Aggregation
- D . Multicasting
According to MuteSoft, which principle is common to both Service Oriented Architecture (SOA) and API-led connectivity approaches?
- A . Service centralization
- B . Service statefulness
- C . Service reusability
- D . Service interdependence
What is an advantage that Anypoint Platform offers by providing universal API management and Integration-Platform-as-a-Service (iPaaS) capabilities in a unified platform?
- A . Ability to use a single iPaaS to manage and integrate all API gateways
- B . Ability to use a single connector to manage and integrate all APis
- C . Ability to use a single control plane for both full-lifecycle AP] management and integration
- D . Ability to use a single iPaaS to manage all API developer portals
C
Explanation:
Anypoint Platform offers universal API management and Integration-Platform-as-a-Service (iPaaS) capabilities in a unified platform, meaning that it provides a single control plane to manage both full-lifecycle API management and integration. This allows organizations to easily manage their APIs and integrations, as well as deploy APIs and integrations quickly and efficiently. According to the MuleSoft Certified Integration Architect – Level 1 Course Book, “Anypoint Platform provides a unified platform for managing, deploying, and monitoring both API and integration solutions, allowing organizations to quickly and easily build and manage their APIs and integrations.”
What Is a recommended practice when designing an integration Mule 4 application that reads a large XML payload as a stream?
- A . The payload should be dealt with as a repeatable XML stream, which must only be traversed (iterated-over) once and CANNOT be accessed randomly from DataWeave expressions and scripts
- B . The payload should be dealt with as an XML stream, without converting it to a single Java object (POJO)
- C . The payload size should NOT exceed the maximum available heap memory of the Mute runtime on which the Mule application executes
- D . The payload must be cached using a Cache scope If It Is to be sent to multiple backend systems
C
Explanation:
If the size of the stream exceeds the maximum, a STREAM_MAXIMUM_SIZE_EXCEEDED error is raised.
An organization has various integrations implemented as Mule applications. Some of these Mule applications are deployed to custom hosted Mule runtimes (on-premises) while others execute in the MuleSoft-hosted runtime plane (CloudHub). To perform the Integra functionality, these Mule applications connect to various backend systems, with multiple applications typically needing to access the backend systems.
How can the organization most effectively avoid creating duplicates in each Mule application of the credentials required to access the backend systems?
- A . Create a Mule domain project that maintains the credentials as Mule domain-shared resources Deploy the Mule applications to the Mule domain, so the credentials are available to the Mule applications
- B . Store the credentials in properties files in a shared folder within the organization’s data center Have the Mule applications load properties files from this shared location at startup
- C . Segregate the credentials for each backend system into environment-specific properties files Package these properties files in each Mule application, from where they are loaded at startup
- D . Configure or create a credentials service that returns the credentials for each backend system, and that is accessible from customer-hosted and MuleSoft-hosted Mule runtimes Have the Mule applications toad the properties at startup by invoking that credentials service
D
Explanation:
* "Create a Mule domain project that maintains the credentials as Mule domain-shared resources" is wrong as domain project is not supported in Cloudhub
* We should Avoid Creating duplicates in each Mule application but below two options cause duplication of credentials – Store the credentials in properties files in a shared folder within the organization’s data center. Have the Mule applications load properties files from this shared location at startup – Segregate the credentials for each backend system into environment-specific properties files. Package these properties files in each Mule application, from where they are loaded at startup So these are also wrong choices
* Credentials service is the best approach in this scenario. Mule domain projects are not supported on CloudHub.
Also its is not recommended to have multiple copies of configuration values as this makes difficult to maintain Use the Mule Credentials Vault to encrypt data in a. properties file. (In the context of this document, we refer to the. properties file simply as the properties file.)
The properties file in Mule stores data as key-value pairs which may contain information such as usernames, first and last names, and credit card numbers. A Mule application may access this data as it processes messages, for example, to acquire login credentials for an external Web service. However, though this sensitive, private data must be stored in a properties file for Mule to access, it must also be protected against unauthorized C and potentially malicious C use by anyone with access to the Mule application
Which Mulesoft feature helps users to delegate their access without sharing sensitive credentials or giving full control of accounts to 3rd parties?
- A . Secure Scheme
- B . client id enforcement policy
- C . Connected apps
- D . Certificates
C
Explanation:
Connected Apps
The Connected Apps feature provides a framework that enables an external application to integrate with Anypoint Platform using APIs through OAuth 2.0 and OpenID Connect. Connected apps help users delegate their access without sharing sensitive credentials or giving full control of their accounts to third parties. Actions taken by connected apps are audited, and users can also revoke access at any time. Note that some products do not currently include client IDs in this release of the Connected Apps feature. The Connected Apps feature enables you to use secure authentication protocols and control an app’s access to user data. Additionally, end users can authorize the app to access their Anypoint Platform data.
Mule Ref Doc: https://docs.mulesoft.com/access-management/connected-apps-overview
A Mule application is synchronizing customer data between two different database systems.
What is the main benefit of using eXtended Architecture (XA) transactions over local transactions to synchronize these two different database systems?
- A . An XA transaction synchronizes the database systems with the least amount of Mule configuration or coding
- B . An XA transaction handles the largest number of requests in the shortest time
- C . An XA transaction automatically rolls back operations against both database systems if any operation falls
- D . An XA transaction writes to both database systems as fast as possible
B
Explanation:
Reference: https://docs.oracle.com/middleware/1213/wls/PERFM/llrtune.htm#PERFM997
A company wants its users to log in to Anypoint Platform using the company’s own internal user credentials. To achieve this, the company needs to integrate an external identity provider (IdP) with the company’s Anypoint Platform master organization, but SAML 2.0 CANNOT be used.
Besides SAML 2.0, what single-sign-on standard can the company use to integrate the IdP with their Anypoint Platform master organization?
- A . SAML 1.0
- B . OAuth 2.0
- C . Basic Authentication
- D . OpenID Connect
D
Explanation:
As the Anypoint Platform organization administrator, you can configure identity management in Anypoint Platform to set up users for single sign-on (SSO).
Configure identity management using one of the following single sign-on standards:
1) OpenID Connect: End user identity verification by an authorization server including SSO
2) SAML 2.0: Web-based authorization including cross-domain SSO
A REST API is being designed to implement a Mule application.
What standard interface definition language can be used to define REST APIs?
- A . Web Service Definition Language (WSDL)
- B . OpenAPI Specification (OAS)
- C . YAML
- D . AsyncAPI Specification
An organization has just developed a Mule application that implements a REST API. The mule application will be deployed to a cluster of customer hosted Mule runtimes.
What additional infrastructure component must the customer provide in order to distribute inbound API requests across the Mule runtimes of the cluster?
- A . A message broker
- B . An HTTP Load Balancer
- C . A database
- D . An Object Store
B
Explanation:
Correct answer is An HTTP Load Balancer.
Key thing to note here is that we are deploying application to customer hosted Mule runtime. This means we will need load balancer to route the requests to different instances of the cluster.
Rest all options are distractors and their requirement depends on project use case.
Which productivity advantage does Anypoint Platform have to both implement and manage an AP?
- A . Automatic API proxy generation
- B . Automatic API specification generation
- C . Automatic API semantic versioning
- D . Automatic API governance
An organization is evaluating using the CloudHub shared Load Balancer (SLB) vs creating a CloudHub dedicated load balancer (DLB). They are evaluating how this choice affects the various types of certificates used by CloudHub deplpoyed Mule applications, including MuleSoft-provided, customer-provided, or Mule application-provided certificates.
What type of restrictions exist on the types of certificates that can be exposed by the CloudHub Shared Load Balancer (SLB) to external web clients over the public internet?
- A . Only MuleSoft-provided certificates are exposed.
- B . Only customer-provided wildcard certificates are exposed.
- C . Only customer-provided self-signed certificates are exposed.
- D . Only underlying Mule application certificates are exposed (pass-through)
A
Explanation:
https://docs.mulesoft.com/runtime-manager/dedicated-load-balancer-tutorial
What metrics about API invocations are available for visualization in custom charts using Anypoint Analytics?
- A . Request size, request HTTP verbs, response time
- B . Request size, number of requests, JDBC Select operation result set size
- C . Request size, number of requests, response size, response time
- D . Request size, number of requests, JDBC Select operation response time
C
Explanation:
Correct answer is Request size, number of requests, response size, response time Analytics API Analytics can provide insight into how your APIs are being used and how they are performing. From API Manager, you can access the Analytics dashboard, create a custom dashboard, create and manage charts, and create reports. From API Manager, you can get following types of analytics: – API viewing analytics – API events analytics – Charted metrics in API Manager
It can be accessed using: http://anypoint.mulesoft.com/analytics
API Analytics provides a summary in chart form of requests, top apps, and latency for a particular duration.
The custom dashboard in Anypoint Analytics contains a set of charts for a single API or for all APIs Each chart displays various API characteristics
C Requests size: Line chart representing size of requests in KBs
C Requests: Line chart representing number of requests over a period
C Response size: Line chart representing size of response in KBs
C Response time: Line chart representing response time in ms
* To check this, You can go to API Manager > Analytics > Custom Dashboard > Edit Dashboard > Create Chart > Metric

Graphical user
interface, chart
Description automatically generated
Reference: https://docs.mulesoft.com/monitoring/api-analytics-dashboard
Additional Information:
The default dashboard contains a set of charts
C Requests by date: Line chart representing number of requests
C Requests by location: Map chart showing the number of requests for each country of origin
C Requests by application: Bar chart showing the number of requests from each of the top five registered applications
C Requests by platform: Ring chart showing the number of requests broken down by platform
According to the National Institute of Standards and Technology (NIST), which cloud computing deployment model describes a composition of two or more distinct clouds that support data and application portability?
- A . Private cloud
- B . Hybrid cloud 4
- C . Public cloud
- D . Community cloud
Which Exchange asset type represents configuration modules that extend the functionality of an API and enforce capabilities such as security?
- A . Rulesets
- B . Policies
- C . RESTAPIs
- D . Connectors
What is maximum vCores can be allocated to application deployed to CloudHub?
- A . 1 vCores
- B . 2 vCores
- C . 4 vCores
- D . 16 vCores
Mule applications need to be deployed to CloudHub so they can access on-premises database systems. These systems store sensitive and hence tightly protected data, so are not accessible over the internet.
What network architecture supports this requirement?
- A . An Anypoint VPC connected to the on-premises network using an IPsec tunnel or AWS DirectConnect, plus matching firewall rules in the VPC and on-premises network
- B . Static IP addresses for the Mule applications deployed to the CloudHub Shared Worker Cloud, plus matching firewall rules and IP whitelisting in the on-premises network
- C . An Anypoint VPC with one Dedicated Load Balancer fronting each on-premises database system, plus matching IP whitelisting in the load balancer and firewall rules in the VPC and on-premises network
- D . Relocation of the database systems to a DMZ in the on-premises network, with Mule applications deployed to the CloudHub Shared Worker Cloud connecting only to the DMZ
A
Explanation:
* "Relocation of the database systems to a DMZ in the on-premises network, with Mule applications deployed to the CloudHub Shared Worker Cloud connecting only to the DMZ" is not a feasible option
* "Static IP addresses for the Mule applications deployed to the CloudHub Shared Worker Cloud, plus matching firewall rules and IP whitelisting in the on-premises network" – It is risk for sensitive data. – Even if you whitelist the database IP on your app, your app wont be able to connect to the database so this is also not a feasible option
* "An Anypoint VPC with one Dedicated Load Balancer fronting each on-premises database system, plus matching IP whitelisting in the load balancer and firewall rules in the
VPC and on-premises network" Adding one VPC with a DLB for each backend system also
makes no sense, is way too much work.
Why would you add a LB for one system.
* Correct Answer "An Anypoint VPC connected to the on-premises network using an IPsec tunnel or AWS DirectConnect, plus matching firewall rules in the VPC and on-premises network"
IPsec Tunnel You can use an IPsec tunnel with network-to-network configuration to connect your on-premises data centers to your Anypoint VPC. An IPsec VPN tunnel is generally the recommended solution for VPC to on-premises connectivity, as it provides a standardized, secure way to connect. This method also integrates well with existing IT infrastructure such as routers and appliances.
Reference: https://docs.mulesoft.com/runtime-manager/vpc-connectivity-methods-concept

Diagram
Description automatically generated
A team would like to create a project skeleton that developers can use as a starting point when creating API Implementations with Anypoint Studio. This skeleton should help drive consistent use of best practices within the team.
What type of Anypoint Exchange artifact(s) should be added to Anypoint Exchange to publish the project skeleton?
- A . A custom asset with the default API implementation
- B . A RAML archetype and reusable trait definitions to be reused across API implementations
- C . An example of an API implementation following best practices
- D . a Mule application template with the key components and minimal integration logic
D
Explanation:
* Sharing Mule applications as templates is a great way to share your work with other people who are in your organization in Anypoint Platform. When they need to build a similar application they can create the mule application using the template project from Anypoint studio.
* Anypoint Templates are designed to make it easier and faster to go from a blank canvas to a production application. They’re bit for bit Mule applications requiring only Anypoint Studio to build and design, and are deployable both on-premises and in the cloud.
* Anypoint Templates are based on five common data Integration patterns and can be customized and extended to fit your integration needs. So even if your use case involves different endpoints or connectors than those included in the template, they still offer a great starting point.
Some of the best practices while creating the template project: – Define the common error handler as part of template project, either using pom dependency or mule config file – Define common logger/audit framework as part of the template project – Define the env specific properties and secure properties file as per the requirement – Define global.xml for global configuration – Define the config file for connector configuration like Http,Salesforce,File,FTP etc – Create separate folders to create DWL,Properties,SSL certificates etc – Add the dependency and configure the pom.xml as per the business need – Configure the mule-artifact.json as per the business need
A Mule application contains a Batch Job scope with several Batch Step scopes. The Batch Job scope is configured with a batch block size of 25.
A payload with 4,000 records is received by the Batch Job scope.
When there are no errors, how does the Batch Job scope process records within and between the Batch Step scopes?
- A . The Batch Job scope processes multiple record blocks in parallel, and a block of 25 records can jump ahead to the next Batch Step scope over an earlier block of records Each Batch Step scope is invoked with one record in the payload of the received Mule event
For each Batch Step scope, all 25 records within a block are processed in parallel
All the records in a block must be completed before the block of 25 records is available to the next Batch Step scope - B . The Batch Job scope processes each record block sequentially, one at a time Each Batch Step scope is invoked with one record in the payload of the received Mule event
For each Batch Step scope, all 25 records within a block are processed sequentially, one at a time
All 4000 records must be completed before the blocks of records are available to the next Batch Step scope - C . The Batch Job scope processes multiple record blocks in parallel, and a block of 25 records can jump ahead to the next Batch Step scope over an earlier block of records Each Batch Step scope is invoked with one record in the payload of the received Mule event
For each Batch Step scope, all 25 records within a block are processed sequentially, one record at a time
All the records in a block must be completed before the block of 25 records is available to the next Batch Step scope - D . The Batch Job scope processes multiple record blocks in parallel
Each Batch Step scope is invoked with a batch of 25 records in the payload of the received Mule event
For each Batch Step scope, all 4000 records are processed in parallel
Individual records can jump ahead to the next Batch Step scope before the rest of the records finish processing in the current Batch Step scope
A
Explanation:
Reference: https://docs.mulesoft.com/mule-runtime/4.4/batch-processing-concept
A company is using Mulesoft to develop API’s and deploy them to Cloudhub and on premises targets. Recently it has decided to enable Runtime Fabric deployment option as well and infrastructure is set up for this option.
What can be used to deploy Runtime Fabric?
- A . AnypointCLI
- B . Anypoint platform REST API’s
- C . Directly uploading ajar file from the Runtime manager
- D . Mule maven plug-in
Mule application muleA deployed in cloudhub uses Object Store v2 to share data across instances. As a part of new requirement, application muleB which is deployed in same region wants to access this Object Store.
Which of the following option you would suggest which will have minimum latency in this scenario?
- A . Object Store REST API
- B . Object Store connector
- C . Both of the above option will have same latency
- D . Object Store of one mule application cannot be accessed by other mule application.
A
Explanation:
V2 Rest API is recommended for on premise applications to access Object Store. It also comes with overhead of encryption and security of using rest api. With Object Store v2, the API call is localized to the same data center as the Runtime Manager app.
But in this case requirement is to access the OS of other mule application and not the same mule application.
You can configure a Mule app to use the Object Store REST API to store and retrieve values from an object store in another Mule app.
However, Object Store v2 is not designed for app-to-app communication.
A Mule application is being designed for deployment to a single CloudHub worker. The Mule application will have a flow that connects to a SaaS system to perform some operations each time the flow is invoked.
The SaaS system connector has operations that can be configured to request a short-lived token (fifteen minutes) that can be reused for subsequent connections within the fifteen minute time window. After the token expires, a new token must be requested and stored.
What is the most performant and idiomatic (used for its intended purpose) Anypoint Platform component or service to use to support persisting and reusing tokens in the Mule application to help speed up reconnecting the Mule application to the SaaS application?
- A . Nonpersistent object store
- B . Persistent object store
- C . Variable
- D . Database
D
Explanation:
Reference: https://docs.mulesoft.com/mule-runtime/4.4/reconnection-strategy-about
A corporation has deployed multiple mule applications implementing various public and private API’s to different cloudhub workers. These API’s arc Critical applications that must be highly available and in line with the reliability SLA as defined by stakeholders.
How can API availability (liveliness or readiness) be monitored so that Ops team receives outage notifications?
- A . Enable monitoring of individual applications from Anypoint monitoring
- B . Configure alerts with failure conditions in runtime manager
- C . Configure alerts failure conditions in API manager
- D . Use any point functional monitoring test API’s functional behavior
A Mule application name Pub uses a persistence object store. The Pub Mule application is deployed to Cloudhub and it configured to use Object Store v2.
Another Mule application name sub is being developed to retrieve values from the Pub Mule application persistence object Store and will also be deployed to cloudhub.
What is the most direct way for the Sub Mule application to retrieve values from the Pub Mule application persistence object store with the least latency?
- A . Use an object store connector configured to access the Pub Mule application persistence object store
- B . Use a VM connector configured to directly access the persistence queue of the Pub Mule application persistence object store.
- C . Use an Anypoint MQ connector configured to directly access the Pub Mule application persistence object store
- D . Use the Object store v2 REST API configured to access the Pub Mule application persistence object store.
D
Explanation:
•Explanation
* The Object Store V2 API enables API access to Anypoint Platform Object Store v2.
* You can configure a Mule app to use the Object Store REST API to store and retrieve values from an object store in another Mule app. However, Object Store v2 is not designed for app-to-app communication.
To share data between two Mule4 apps, use a queue in Anypoint MQ.
* The Object Store v2 APIs enable you to use REST to perform the following:
– Retrieve a list of object stores and keys associated with an application.
– Store and retrieve key-value pairs in an object store.
– Delete key-value pairs from an object store.
– Retrieve Object Store usage statistics for your organization.
– Object Store provides these APIs:
Object Store API
Object Store Stats API
Reference: https://docs.mulesoft.com/object-store/osv2-apis
Additional Info:
When to use Object Store and when to use VM
Diagram
Description automatically generated
According to MuleSoft, which system integration term describes the method, format, and protocol used for communication between two system?
- A . Component
- B . interaction
- C . Message
- D . Interface
A team has completed the build and test activities for a Mule application that implements a System API for its application network.
Which Anypoint Platform component should the team now use to both deploy and monitor the System AP implementation?
- A . API Manager
- B . Design Center
- C . Anypoint Exchange
- D . Runtime Manager
Organization wants to achieve high availability goal for Mule applications in customer hosted runtime plane. Due to the complexity involved, data cannot be shared among of different instances of same Mule application.
What option best suits to this requirement considering high availability is very much critical to the organization?
- A . The cluster can be configured
- B . Use third party product to implement load balancer
- C . High availability can be achieved only in CloudHub
- D . Use persistent object store
B
Explanation:
High availability is about up-time of your application
A) High availability can be achieved only in CloudHub isn’t correct statement. It can be achieved in customer hosted runtime planes as well
B) An object store is a facility for storing objects in or across Mule applications. Mule runtime engine (Mule) uses object stores to persist data for eventual retrieval. It can be used for disaster recovery but not for High Availability. Using object store can’t guarantee
that all instances won’t go down at once. So not an appropriate choice.
Reference: https://docs.mulesoft.com/mule-runtime/4.3/mule-object-stores
C) High availability can be achieved by below two models for on-premise MuleSoft implementations.
1) Mule Clustering C Where multiple Mule servers are available within the same cluster environment and the routing of requests will be done by the load balancer. A cluster is a set of up to eight servers that act as a single deployment target and high-availability processing unit. Application instances in a cluster are aware of each other, share common information, and synchronize statuses. If one server fails, another server takes over processing applications. A cluster can run multiple applications. ( refer left half of the diagram)
In given scenario, it’s mentioned that ‘data cannot be shared among of different instances’.
So this is not a correct choice.
Reference: https://docs.mulesoft.com/runtime-manager/cluster-about
2) Load balanced standalone Mule instances C The high availability can be achieved even without cluster, with the usage of third party load balancer pointing requests to different Mule servers. This approach does not share or synchronize data between Mule runtimes. Also high availability achieved as load balanced algorithms can be implemented using external load balancer. (refer right half of the diagram)
Graphical user interface, diagram, application
Description automatically generated
An organization has deployed both Mule and non-Mule API implementations to integrate its customer and order management systems. All the APIs are available to REST clients on the public internet.
The organization wants to monitor these APIs by running health checks: for example, to determine if an API can properly accept and process requests. The organization does not have subscriptions to any external monitoring tools and also does not want to extend its IT footprint.
What Anypoint Platform feature provides the most idiomatic (used for its intended purpose) way to monitor the availability of both the Mule and the non-Mule API implementations?
- A . API Functional Monitoring
- B . Runtime Manager
- C . API Manager
- D . Anypoint Visualizer
D
Explanation:
Reference: https://docs.mulesoft.com/visualizer/
What best describes the Fully Qualified Domain Names (FQDNs), also known as DNS entries, created when a Mule application is deployed to the CloudHub Shared Worker Cloud?
- A . A fixed number of FQDNs are created, IRRESPECTIVE of the environment and VPC design
- B . The FQDNs are determined by the application name chosen, IRRESPECTIVE of the region
- C . The FQDNs are determined by the application name, but can be modified by an administrator after deployment
- D . The FQDNs are determined by both the application name and the region
D
Explanation:
Every Mule application deployed to CloudHub receives a DNS entry pointing to the CloudHub. The DNS entry is a CNAME for the CloudHub Shared Load Balancer in the region to which the Mule application is deployed. When we deploy the application on CloudHub, we get a generic url to access the endpoints. Generic URL looks as below: <application-name>.<region>.cloudhub.io <application-name> is the deployed application name which is unique across all the MuleSoft clients. <region> is the region name in which an application is deployed.
The public CloudHub (shared) load balancer already redirects these requests, where myApp is the name of the Mule application deployment to CloudHub: HTTP requests to http://myApp.<region>.cloudhub.io redirects to http://mule-worker-myApp.<region>.cloudhub.io:8081
HTTPS traffic to https://myApp.<region>.cloudhub.io redirects to https://mule-worker-myApp.<region>.cloudhub.io:8082