Mulesoft MCIA-Level 1 MuleSoft Certified Integration Architect – Level 1 Online Training
Mulesoft MCIA-Level 1 Online Training
The questions for MCIA-Level 1 were last updated at Apr 01,2026.
- Exam Code: MCIA-Level 1
- Exam Name: MuleSoft Certified Integration Architect - Level 1
- Certification Provider: Mulesoft
- Latest update: Apr 01,2026
In Anypoint Platform, a company wants to configure multiple identity providers (IdPs) for multiple lines of business (LOBs). Multiple business groups, teams, and environments have been defined for these LOBs.
What Anypoint Platform feature can use multiple IdPs across the company’s business groups, teams, and environments?
- A . MuleSoft-hosted (CloudHub) dedicated load balancers
- B . Client (application) management
- C . Virtual private clouds
- D . Permissions
A
Explanation:
To use a dedicated load balancer in your environment, you must first create an Anypoint VPC. Because you can associate multiple environments with the same Anypoint VPC, you can use the same dedicated load balancer for your different environments.
Reference: https://docs.mulesoft.com/runtime-manager/cloudhub-dedicated-load-balancer
A global, high-volume shopping Mule application is being built and will be deployed to CloudHub. To improve performance, the Mule application uses a Cache scope that maintains cache state in a CloudHub object store. Web clients will access the Mule application over HTTP from all around the world, with peak volume coinciding with business hours in the web client’s geographic location.
To achieve optimal performance, what Anypoint Platform region should be chosen for the CloudHub object store?
- A . Choose the same region as to where the Mule application is deployed
- B . Choose the US-West region, the only supported region for CloudHub object stores
- C . Choose the geographically closest available region for each web client
- D . Choose a region that is the traffic-weighted geographic center of all web clients
A
Explanation:
CloudHub object store should be in same region where the Mule application is deployed.
This will give optimal performance.
Before learning about Cache scope and object store in Mule 4 we understand what is in general Caching is and other related things. WHAT DOES “CACHING” MEAN?
Caching is the process of storing frequently used data in memory, file system or database which saves processing time and load if it would have to be accessed from original source location every time.
In computing, a cache is a high-speed data storage layer which stores a subset of data, so that future requests for that data are served up faster than is possible by accessing the data’s primary storage location. Caching allows you to efficiently reuse previously retrieved or computed data.
How does Caching work?
The data in a cache is generally stored in fast access hardware such as RAM (Random-access memory) and may also be used in correlation with a software component. A cache’s primary purpose is to increase data retrieval performance by reducing the need to access the underlying slower storage layer.
Caching in MULE 4
In Mule 4 caching can be achieved in mule using cache scope and/or object-store. Cache scope internally uses Object Store to store the data.
What is Object Store
Object Store lets applications store data and states across batch processes, Mule components, and applications, from within an application. If used on cloud hub, the object store is shared between applications deployed on Cluster. Cache Scope is used in below-mentioned cases:
Need to store the whole response from the outbound processor
Data returned from the outbound processor does not change very frequently
As Cache scope internally handle the cache hit and cache miss scenarios it is more readable
Object Store is used in below-mentioned cases:
Need to store custom/intermediary data
To store watermarks
Sharing the data/stage across applications, schedulers, batch.
If CloudHub object store is in same region where the Mule application is deployed it will aid in fast access of data and give optimal performance.
Refer to the exhibit.
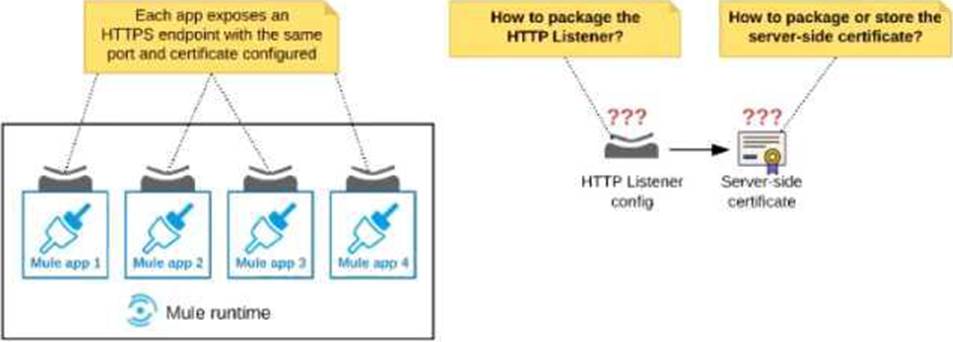
An organization deploys multiple Mule applications to the same customer -hosted Mule runtime. Many of these Mule applications must expose an HTTPS endpoint on the same port using a server-side certificate that rotates often.
What is the most effective way to package the HTTP Listener and package or store the server-side certificate when deploying these Mule applications, so the disruption caused by certificate rotation is minimized?
- A . Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint Package the server-side certificate in ALL Mule APPLICATIONS that need to expose an HTTPS endpoint
- B . Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint. Store the server-side certificate in a shared filesystem location in the Mule runtime’s classpath, OUTSIDE the Mule DOMAIN or any Mule APPLICATION
- C . Package an HTTPS Listener configuration In all Mule APPLICATIONS that need to expose an HTTPS endpoint Package the server-side certificate in a NEW Mule DOMAIN project
- D . Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing It from all Mule applications that need to expose an HTTPS endpoint. Package the server-side certificate in the SAME Mule DOMAIN project Go to Set
B
Explanation:
In this scenario, both A & C will work, but A is better as it does not require repackage to the domain project at all.
Correct answer is Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint. Store the server-side certificate in a shared filesystem location in the Mule runtime’s classpath, OUTSIDE the Mule DOMAIN or any Mule APPLICATION.
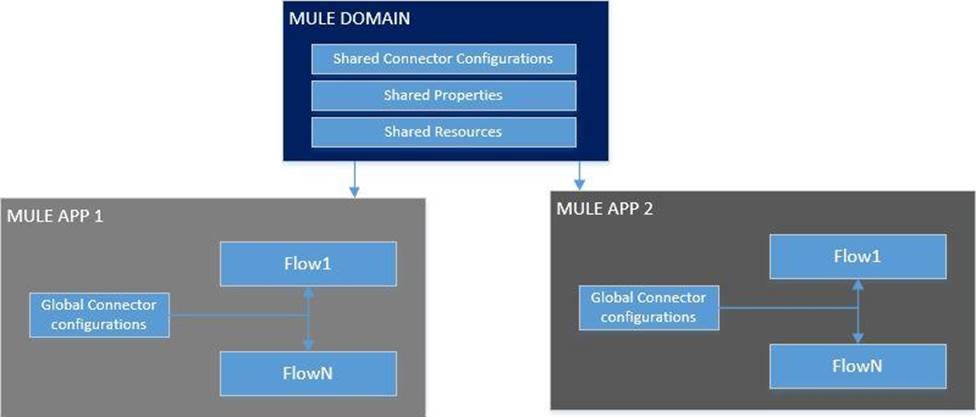
What is Mule Domain Project?
* A Mule Domain Project is implemented to configure the resources that are shared among different projects. These resources can be used by all the projects associated with this domain. Mule applications can be associated with only one domain, but a domain can be associated with multiple projects. Shared resources allow multiple development teams to work in parallel using the same set of reusable connectors. Defining these connectors as shared resources at the domain level allows the team to: – Expose multiple services within the domain through the same port. – Share the connection to persistent storage. – Share services between apps through a well-defined interface. – Ensure consistency between apps upon any changes because the configuration is only set in one place.
* Use domains Project to share the same host and port among multiple projects. You can declare the http connector within a domain project and associate the domain project with other projects. Doing this also allows to control thread settings, keystore configurations, time outs for all the requests made within multiple applications. You may think that one can also achieve this by duplicating the http connector configuration across all the applications. But, doing this may pose a nightmare if you have to make a change and redeploy all the applications.
* If you use connector configuration in the domain and let all the applications use the new domain instead of a default domain, you will maintain only one copy of the http connector configuration. Any changes will require only the domain to the redeployed instead of all the applications.
You can start using domains in only three steps:
1) Create a Mule Domain project
2) Create the global connector configurations which needs to be shared across the applications inside the Mule Domain project
3) Modify the value of domain in mule-deploy.properties file of the applications
Graphical user
interface
Description automatically generated
Use a certificate defined in already deployed Mule domain Configure the certificate in the domain so that the API proxy HTTPS Listener references it, and then deploy the secure API proxy to the target Runtime Fabric, or on-premises target. (CloudHub is not supported with this approach because it does not support Mule domains.)
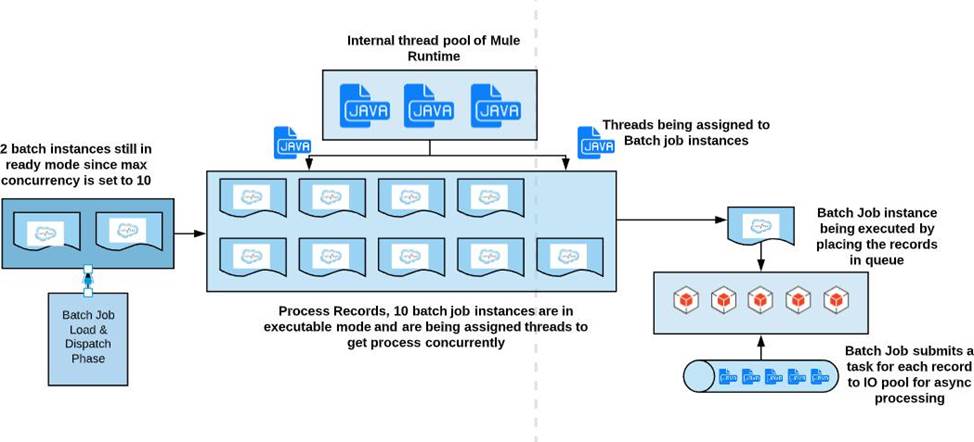
A Mule application contains a Batch Job with two Batch Steps (Batch_Step_l and Batch_Step_2). A payload with 1000 records is received by the Batch Job.
How many threads are used by the Batch Job to process records, and how does each Batch Step process records within the Batch Job?
- A . Each Batch Job uses SEVERAL THREADS for the Batch Steps Each Batch Step instance receives ONE record at a time as the payload, and RECORDS are processed IN PARALLEL within and between the two Batch Steps
- B . Each Batch Job uses a SINGLE THREAD for all Batch steps Each Batch step instance receives ONE record at a time as the payload, and RECORDS are processed IN ORDER, first through Batch_Step_l and then through Batch_Step_2
- C . Each Batch Job uses a SINGLE THREAD to process a configured block size of record Each Batch Step instance receives A BLOCK OF records as the payload, and BLOCKS of records are processed IN ORDER
- D . Each Batch Job uses SEVERAL THREADS for the Batch Steps Each Batch Step instance receives ONE record at a time as the payload, and BATCH STEP INSTANCES execute IN PARALLEL to process records and Batch Steps in ANY order as fast as possible
A
Explanation:
* Each Batch Job uses SEVERAL THREADS for the Batch Steps
* Each Batch Step instance receives ONE record at a time as the payload. It’s not received in a block, as it does not wait for multiple records to be completed before moving to next batch step. (So Option D is out of choice)
* RECORDS are processed IN PARALLEL within and between the two Batch Steps.
* RECORDS are not processed in order. Let’s say if second record completes
batch_step_1 before record 1, then it moves to batch_step_2 before record 1. (So option C and D are out of choice)
* A batch job is the scope element in an application in which Mule processes a message payload as a batch of records. The term batch job is inclusive of all three phases of
processing: Load and Dispatch, Process, and On Complete.
* A batch job instance is an occurrence in a Mule application whenever a Mule flow executes a batch job. Mule creates the batch job instance in the Load and Dispatch phase. Every batch job instance is identified internally using a unique String known as batch job instance id.
An Integration Mule application is being designed to synchronize customer data between two systems. One system is an IBM Mainframe and the other system is a Salesforce Marketing Cloud (CRM) instance. Both systems have been deployed in their typical configurations, and are to be invoked using the native protocols provided by Salesforce and IBM.
What interface technologies are the most straightforward and appropriate to use in this Mute application to interact with these systems, assuming that Anypoint Connectors exist that implement these interface technologies?
- A . IBM: DB access CRM: gRPC
- B . IBM: REST CRM:REST
- C . IBM: Active MQ CRM: REST
- D . IBM: CICS CRM: SOAP
D
Explanation:
Correct answer is IBM: CICS CRM: SOAP
* Within Anypoint Exchange, MuleSoft offers the IBM CICS connector. Anypoint Connector for IBM CICS Transaction Gateway (IBM CTG Connector) provides integration with back-end CICS apps using the CICS Transaction Gateway.
* Anypoint Connector for Salesforce Marketing Cloud (Marketing Cloud Connector) enables you to connect to the Marketing Cloud API web services (now known as the Marketing
Cloud API), which is also known as the Salesforce Marketing Cloud. This connector exposes convenient operations via SOAP for exploiting the capabilities of Salesforce Marketing Cloud.
A company is modernizing its legal systems lo accelerate access lo applications and data while supporting the adoption of new technologies. The key to achieving this business goal is unlocking the companies’ key systems and dala including microservices miming under Docker and kubernetes containers using apis.
Considering the current aggressive backlog and project delivery requirements the company wants to take a strategic approach in the first phase of its transformation projects by quickly deploying API’s in mule runtime that are able lo scale, connect to on premises systems and migrate as needed.
Which runtime deployment option supports company’s goals?
- A . Customer hosted self provisioned runtimes
- B . Cloudhub runtimes
- C . Runtime fabric on self managed Kubernetes
- D . Runtime fabric on Vmware metal
An integration team follows MuleSoft’s recommended approach to full lifecycle API development.
Which activity should this team perform during the API implementation phase?
- A . Validate the API specification
- B . Use the API specification to build the MuleSoft application
- C . Design the API specification
- D . Use the API specification to monitor the MuleSoft application
An organization is not meeting its growth and innovation objectives because IT cannot deliver projects last enough to keep up with the pace of change required by the business.
According to MuleSoft’s IT delivery and operating model, which step should the organization lake to solve this problem?
- A . Modify IT governance and security controls so that line of business developers can have direct access to the organization’s systems of record
- B . Switch from a design-first to a code-first approach for IT development
- C . Adopt a new approach that decouples core IT projects from the innovation that happens within each line of business
- D . Hire more |T developers, architects, and project managers to increase IT delivery
Mule application is deployed to Customer Hosted Runtime. Asynchronous logging was implemented to improved throughput of the system. But it was observed over the period of time that few of the important exception log messages which were used to rollback transactions are not working as expected causing huge loss to the Organization. Organization wants to avoid these losses. Application also has constraints due to which they cant compromise on throughput much.
What is the possible option in this case?
- A . Logging needs to be changed from asynchronous to synchronous
- B . External log appender needs to be used in this case
- C . Persistent memory storage should be used in such scenarios
- D . Mixed configuration of asynchronous or synchronous loggers should be used to log exceptions via synchronous way
D
Explanation:
Correct approach is to use Mixed configuration of asynchronous or synchronous loggers shoud be used to log exceptions via synchronous way Asynchronous logging poses a performance-reliability trade-off. You may lose some messages if Mule crashes before the logging buffers flush to the disk. In this case, consider that you can have a mixed configuration of asynchronous or synchronous loggers in your app. Best practice is to use asynchronous logging over synchronous with a minimum logging level of WARN for a production application. In some cases, enable INFO logging level when you need to confirm events such as successful policy installation or to perform troubleshooting. Configure your logging strategy by editing your application’s src/main/resources/log4j2.xml file
In a Mule Application, a flow contains two (2) JMS consume operations that are used to connect to a JMS broker and consume messages from two (2) JMS destination. The Mule application then joins the two JMS messages together.
The JMS broker does not implement high availability (HA) and periodically experiences scheduled outages of upto 10 mins for routine maintenance.
What is the most idiomatic (used for its intented purpose) way to build the mule flow so it can best recover from the expected outages?
- A . Configure a reconnection strategy for the JMS connector
- B . Enclose the two (2) JMS operation in an Until Successful scope
- C . Consider a transaction for the JMS connector
- D . Enclose the two (2) JMS operations in a Try scope with an Error Continue error handler
A
Explanation:
When an operation in a Mule application fails to connect to an external server, the default behavior is for the operation to fail immediately and return a connectivity error. You can modify this default behavior by configuring a reconnection strategy for the operation. You can configure a reconnection strategy for an operation either by modifying the operation properties or by modifying the configuration of the global element for the operation. The following are the available reconnection strategies and their behaviors: None Is the default behavior, which immediately returns a connectivity error if the attempt to connect is unsuccessful Standard (reconnect) Sets the number of reconnection attempts and the interval at which to execute them before returning a connectivity error Forever (reconnect-forever) Attempts to reconnect continually at a given interval
Latest MCIA-Level 1 Dumps Valid Version with 79 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
