

Topic 1, Exam Pool A
Note: This question is part of a series of question that present the same scenario. Each question in the series contains I unique solution that might meet the stated goals Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it As a result, these questions will not appear in the review screAen. Your company has several Microsoft SQL Saver instance. Each instance hosts many database. You observe I/O corruption on some of the instance.
You need to perform the following actions:
– identify databases where the PAGE verity option is not set.
– Configure full page protection for the identified databases.
Solution: You run the following Transact-SQL statement:


For each database that you identify, you run the following Transact-SQL statement:
![]()

Does the solution meet the goal?
- A . Yes
- B . No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. Your company has several Microsoft SOI Server instances. Each instance hosts many databases. You observe I/O corruption on some of the instances.
You need to perform the following actions:
– Identify databases where the PAGE VERIFY option is not set.
– Configure full page protection for the identified databases.
Solution: You run the following Transact-SQL statement:


For each database that you identify, you run the following Transact-SQL statement:


Does the solution meet the goal?
- A . Yes
- B . NO
B
Explanation:
We should check for CHECKSUM not TORN_PAGE_DETECTION References: https://docs.microsoft.com/en-us/sql/relational-databases/policy-based-management/set-the-pageverify-database-option-to-checksum?view=sql-server-2017
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it As a result these questions will not appear in the review screen. Your company has several Microsoft SQL Server instances, Each instance hosts many databases. You observe I/O corruption on some of the instances
You need to perform the following actions:
– Identify databases where the PAGE VERIFY option is not set
– Configure full page protection for the identified databases.
Solution: You run the following Transact-SQL statement:


For each database that you identify, you run the following Transact-SQL statement:

Does the solution meet the goal?
- A . Yes
- B . No
B
Explanation:
We should check for CHECKSUM not NONE or TORN_PAGE_DETECTION
References: https://docs.microsoft.com/en-us/sql/relational-databases/policy-based-management/set-the-pageverify-database-option-to-checksum?view=sql-server-2017
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it As a result these questions will not appear in the review screen.
You have a database named DB1 that is 640 GB and is updated frequently. You enabled log shipping for DB1 and configure backup and restore to occur every 30 minutes. You discover that the disks on the data server are almost full. You need to reduce the amount of disk space used by the log shipping process.
Solution: You configure log shipping to backup and restore by using shared folder.
Does this meet the goal?
- A . Yes
- B . No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it As a result these questions will not appear in the review screen.
You have a database named DB1 that is 640 GB and is updated frequently. You enabled log shipping for DB1 and configure backup and restore to occur every 30 minutes. You discover that the disks on the data server are almost full. You need to reduce the amount of disk space used by the log shipping process.
Solution: You enable compression for the transaction log backups:
Does this meet the goal?
- A . Yes
- B . No
A
Explanation:
SQL Server 2017 supports backup compression. When creating a log shipping configuration, you can control the backup compression behavior of log backups by choosing one of the following options: Use the default server setting, Compress backup, or Do not compress backup
Note: SQL Server 2008 Enterprise and later versions support backup compression.
References: https://docs.microsoft.com/en-us/sql/database-engine/log-shipping/configure-logshipping-sql-server?view=sql-server-2017
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it As a result these questions will not appear in the review screen.
You have a database named DB1 that is 640 GB and is updated frequently. You enabled log shipping for DB1 and configure backup and restore to occur every 30 minutes. You discover that the disks on the data server are almost full. You need to reduce the amount of disk space used by the log shipping process.
Solution: You increase the frequency of the transaction log backups to every 10 minutes.
Does this meet the goal?
- A . Yes
- B . No
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You need to configure a Microsoft SQL Server instance to ensure that a user named Mail1 can send mail by using Database Mail.
Solution: You add the DatabaseMailUserRole to Mail1 in the tempdb database.
Does the solution meet the goal?
- A . Yes
- B . No
B
Explanation:
Database Mail is guarded by the database role DatabaseMailUserRole in the msdb database, not the tempdb database, in order to prevent anyone from sending arbitrary emails. Database users or roles must be created in the msdb database and must also be a member of DatabaseMailUserRole in order to send emails with the exception of sysadmin who has all privileges.
Note: Database Mail was first introduced as a new feature in SQLServer 2005 and replaces the SQL Mail feature found in previous versions.
References: http://www.idevelopment.info/data/SQLServer/DBA_tips/Database_Administration/DBA_20.shtml
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You need to configure a Microsoft SQL Server instance to ensure that a user named Mail1 can send mail by using Database Mail.
Solution: You add the DatabaseMailUserRole to Mail1 in the msdb database.
Does the solution meet the goal?
- A . Yes
- B . No
A
Explanation:
Database Mail is guarded by the database role DatabaseMailUserRole in the msdb database in order to prevent anyone from sending arbitrary emails. Database users or roles must be created in the msdb database and must also be a member of DatabaseMailUserRole in order to send emails with the exception of sysadmin who has all privileges.
Note: Database Mail was first introduced as a new feature in SQL Server 2005 and replaces the SQL Mail feature found in previous versions.
References: http://www.idevelopment.info/data/SQLServer/DBA_tips/Database_Administration/DBA_20.shtml
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You need to configure a Microsoft SQL Server instance to ensure that a user named Mail1 can send mail by using Database Mail.
Solution: You add the DatabaseMailUserRole to Mail1 in the master database.
Does the solution meet the goal?
- A . Yes
- B . No
B
Explanation:
Database Mail is guarded by the database role DatabaseMailUserRole in the msdb database, not the master database, in order to prevent anyone from sending arbitrary emails. Database users or roles must be created in the msdb database and must also be a member of DatabaseMailUserRole in order to send emails with the exception of sysadmin who has all privileges.
Note: Database Mail was first introduced as a new feature in SQL Server 2005 and replaces the SQL Mail feature found in previous versions.
References: http://www.idevelopment.info/data/SQLServer/DBA_tips/Database_Administration/DBA_20.shtml
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company has a server that runs Microsoft SQL Server 2016 Web edition. The server has a default instance that hosts a database named DB1.
You need to ensure that you can perform auditing at the database level for DB1.
Solution: You migrate DB1 to the default instance on a server that runs Microsoft SQL Server 2016 Standard edition.
Does the solution meet the goal?
- A . Yes
- B . No
B
Explanation:
All editions of SQL Server support server level audits. All editions support database level audits beginning with SQL Server 2016 SP1. Prior to that, database level auditing was limited to Enterprise, Developer, and Evaluation editions.
References: https://docs.microsoft.com/en-us/sql/relational-databases/security/auditing/sql-serveraudit-database-engine
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company has a server that runs Microsoft SQL Server 2016 Web edition. The server has a default instance that hosts a database named DB1.
You need to ensure that you can perform auditing at the database level for DB1.
Solution: You migrate DB1 to a named instance on a server that runs Microsoft SQL Server 2016 Enterprise edition.
Does the solution meet the goal?
- A . Yes
- B . No
A
Explanation:
All editions of SQL Server support server level audits. All editions support database level audits beginning with SQL Server 2016 SP1. Prior to that, database level auditing was limited to Enterprise, Developer, and Evaluation editions.
References: https://docs.microsoft.com/en-us/sql/relational-databases/security/auditing/sql-serveraudit-database-engine
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company has a server that runs Microsoft SQL Server 2016 Web edition. The server has a default instance that hosts a database named DB1.
You need to ensure that you can perform auditing at the database level for DB1.
Solution: You migrate DB1 to a named instance on a server than runs Microsoft SQL Server 2016 Standard edition.
Does the solution meet the goal?
- A . Yes
- B . No
B
Explanation:
All editions of SQL Server support server level audits. All editions support database level audits beginning with SQL Server 2016 SP1. Prior to that, database level auditing was limited to Enterprise, Developer, and Evaluation editions.
References: https://docs.microsoft.com/en-us/sql/relational-databases/security/auditing/sql-serveraudit-database-engine
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company has an on-premises Microsoft SQL Server environment and Microsoft Azure SQL Database instances. The environment hosts several customer databases. One customer reports that their database is not responding as quickly as the service level
agreements dictate. You observe that the database is fragmented. You need to optimize query performance.
Solution: You reorganize all indexes.
Does the solution meet the goal?
- A . Yes
- B . No
A
Explanation:
You can remedy index fragmentation by either reorganizing an index or by rebuilding an index. References: https://msdn.microsoft.com/en-us/library/ms189858(v=sql.105).aspx
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company has an on-premises Microsoft SQL Server environment and Microsoft Azure SQL Database instances. The environment hosts several customer databases.
One customer reports that their database is not responding as quickly as the service level agreements dictate. You observe that the database is fragmented. You need to optimize query performance.
Solution: You rebuild all indexes.
Does the solution meet the goal?
- A . Yes
- B . No
A
Explanation:
You can remedy index fragmentation by either reorganizing an index or by rebuilding an index. References: https://msdn.microsoft.com/en-us/library/ms189858(v=sql.105).aspx
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
A company has an on-premises Microsoft SQL Server environment and Microsoft Azure SQL Database instances. The environment hosts several customer databases.
One customer reports that their database is not responding as quickly as the service level agreements dictate. You observe that the database is fragmented.
You need to optimize query performance.
Solution: You run the DBCC CHECKDB command.
Does the solution meet the goal?
- A . Yes
- B . No
B
Explanation:
DBCC CHECKDB only checks the logical and physical integrity of all the objects in the specified database. It does not update any indexes, and does not improve query performance.
References: https://docs.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcccheckdb-transact-sql
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are the database administrator for a company that hosts Microsoft SQL Server. You manage both on-premises and Microsoft Azure SQL Database environments.
One instance hosts a user database named HRDB. The database contains sensitive human resources data.
You need to grant an auditor permission to view the SQL Server audit logs while following the principle of least privilege.
Which permission should you grant?
- A . DDLAdmin
- B . db_datawriter
- C . dbcreator
- D . dbo
- E . View Database State
- F . View Server State
- G . View Definition
- H . sysadmin
F
Explanation:
Unless otherwise specified, viewing catalog views requires a principal to have one of the following:
References: https://technet.microsoft.com/en-us/library/cc280386(v=sql.110).aspx
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You manage a Microsoft SQL Server environment. You implement Transparent Data Encryption (TDE).
A user will assist in managing TDE.
You need to ensure that the user can view the TDE metadata while following the principle of lease privilege.
Which permission should you grant?
- A . DDLAdmin
- B . db_datawriter
- C . dbcreator
- D . dbo
- E . View Database State
- F . View Server State
- G . View Definition
- H . sysadmin
G
Explanation:
Viewing the metadata involved with TDE requires the VIEW DEFINITION permissionon the certificate.
References: https://docs.microsoft.com/en-us/sql/relationaldatabases/security/encryption/transparent-data-encryption-tde
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are the database administrator for a company that hosts Microsoft SQL Server. You manage both on-premises and Microsoft Azure SQL Database environments.
You have a user database named HRDB that contains sensitive human resources data. The HRDB backup files must be encrypted.
You need to grant the correct permission to the service account that backs up the HRDB database.
Which permission should you grant?
- A . DDLAdmin
- B . db_datawriter
- C . dbcreator
- D . dbo
- E . View Database State
- F . View Server State
- G . View Definition
- H . sysadmin
G
Explanation:
Restoring the encrypted backup: SQL Server restore does not require any encryption parameters to be specified during restores. It does require that the certificate or the asymmetric key used to encrypt the backup file be available on the instance that you are restoring to. The user account performing the restore must have VIEW DEFINITION permissions on the certificate or key.
References: https://docs.microsoft.com/en-us/sql/relational-databases/backup-restore/backupencryption
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are the database administrator for a company that hosts Microsoft SQL Server. You manage both on-premises and Microsoft Azure SQL Database environments.
You plan to delegate encryption operations to a user.
You need to grant the user permission to implement cell-level encryption while following the principle of least privilege.
Which permission should you grant?
- A . DDLAdmin
- B . db_datawriter
- C . dbcreator
- D . dbo
- E . View Database State
- F . View ServerState
- G . View Definition
- H . sysadmin
G
Explanation:
The following permissions are necessary to perform column-level encryption, or cell-level encryption.
References: https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/encrypta-column-of-data
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
A company has an on-premises Microsoft SQL Server environment and Microsoft Azure SQL Database instances. The environment hosts a customer database named DB1.
Customers connect to hosted database instances by using line-of-business applications. Developers connect by using SQL Server Management Studio (SSMS).
You need to grant the developers permission to alter views for DB1 while following the principle of least privilege.
Which permission should you grant?
- A . DDLAdmin
- B . db_datawriter
- C . dbcreator
- D . dbo
- E . View Database State
- F . View Server State
- G . View Definition
- H . sysadmin
A
Explanation:
To execute ALTER VIEW, at a minimum, ALTER permission on OBJECT is required. Members of the db_ddladmin fixed database role can run any Data Definition Language (DDL)
command in a database.
References: https://technet.microsoft.com/en-us/library/ms190667(v=sql.90).aspx
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are the database administrator for a company that hosts Microsoft SQL Server. You manage both on-premises and Microsoft Azure SQL Database environments.
Clients connect to databases by using line-of-business applications. Developers connect by using SQL Server Management Studio (SSMS).
You need to provide permissions to a service account that will be used to provision a new database for a client.
Which permission should you grant?
- A . DDLAdmin
- B . db_datawriter
- C . dbcreator
- D . dbo
- E . View Database State
- F . View Server State
- G . View Definition
- H . sysadmin
C
Explanation:
Members of the dbcreator fixed server role can create, alter, drop, and restore any database.
References: https://docs.microsoft.com/en-us/sql/relational-databases/security/authenticationaccess/server-level-roles
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are examining information about users, sessions, and processed in an on-premises Microsoft SQL Server Database Engine instance.
You need to return information about processes that are not idle, that belong to a specific user, or that belong to a specific session.
What should you use?
- A . Activity Monitor
- B . sp_who3
- C . SQL Server Management Studio (SSMS) Object Explorer
- D . SQL Server Data Collector
- E . SQL Server Data Tools (SSDT)
- F . SQL Server Configuration Manager
B
Explanation:
Use sp_who3 to first view the current system load and to identify a session of interest. You should execute the query several times to identify which session id is most consuming teh system resources.
Parameters sp_who3 null – who is active; sp_who3 1 or ‘memory’ – who is consuming the memory; sp_who3 2 or ‘cpu’ – who has cached plans that consumed the most cumulative CPU (top 10); sp_who3 3 or ‘count’ – who is connected and how many sessions it has; sp_who3 4 or ‘idle’ – who is idle that has open transactions; sp_who3 5 or ‘tempdb’ – who is running tasks that use tempdb (top 5); and, sp_who3 6 or ‘block’ – who is blocking.
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You observe that several indexes are fragmented.
You need to rebuild the indexes.
What should you use?
- A . Activity Monitor
- B . Sp_who3 stored procedure
- C . Object Explorer in the SQL Server Management Studio (SSMS)
- D . SQL Server Data Collector
- E . SQL Server Data Tools (SSDT)
- F . SQL Server Configuration Manager
C
Explanation:
How to: Rebuild an Index (SQL Server Management Studio) To rebuild an index
References: https://technet.microsoft.com/en-us/library/ms187874(v=sql.105).aspx
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is
independent of the other questions in this series. Information and details provided in a question apply only to that question.
You need to examine information about logins, CPU times, and Disk I/O on a particular database in Microsoft Azure.
What should you use?
- A . Activity Monitor
- B . Sp_who3
- C . SQL Server Management Studio (SSMS) Object Explorer
- D . SQL Server Data Collector
- E . SQL Server Data Tools (SSDT)
- F . SQL Server Configuration Manager
A
Explanation:
Activity Monitor displays information about SQL Server processes and how these processes affect the current instance of SQL Server. Activity Monitor is a tabbed document window with the following expandable and collapsible panes: Overview, Active User Tasks, Resource Waits, Data File I/O, and Recent Expensive Queries.
The Activity User Tasks Pane shows information for active user connections to the instance, including the following column:
* Login: The SQL Server login name under which the session is currently executing. The Recent Expensive Queries Pane shows information about the most expensive queries that have been run on the instance over the last 30 seconds, including the following column:
* CPU (ms/sec): The rate of CPU use by the query
References: https://technet.microsoft.com/en-us/library/cc879320(v=sql.105).aspx
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You collect performance metrics on multiple Microsoft SQL Server instances and store the data in a single repository.
You need to examine disk usage, query statistics, and server activity without building custom counters.
What should you use?
- A . Activity Monitor
- B . Sp_who3 stored procedure
- C . Object Explorer in the Microsoft SQL Server Management Studio (SSMS)
- D . SQL Server Data Collector
- E . SQL Server Data Tools (SSDT)
- F . SQL Server Configuration Manager
D
Explanation:
The data collector is a core component of the data collection platform for SQL Server 2017 and the tools that are provided by SQL Server. The data collector provides one central point for data collection across your database servers and applications. This collection point can obtain data from a variety of sources and is not limited to performance data
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are examining information about users, sessions, and processes in an on-premises Microsoft SQL Server 2016 Standard Edition server.
You need to identify waits for resources and return only the following information:
– a list of all databases on the SQL Server instance, along with information about the database files, their paths, and names
– a list of the queries recently executed that use most of memory, disk, and network resources
What should you use?
- A . Activity Monitor
- B . Sp_who3
- C . SQL Server Management Studio (SSMS) Object Explorer
- D . SQL Server Data Collector
- E . SQL Server Data Tools (SSDT)
- F . SQL Server Configuration Manager
E
Explanation:
SQL Server Data Tools (SSDT) is a Microsoft Visual Studio environment for creating business intelligence solutions. SSDT features the Report Designer authoring environment, where you can open, modify, preview, save, and deploy Reporting Services paginated report definitions, shared data sources, shared datasets, and report parts.
References: https://msdn.microsoft.com/en-us/library/hh272686(v=vs.103).aspx
Note: This question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You have an on-premises server that runs Microsoft SQL Server 2016 Standard Edition.
You need to identify missing indexes.
What should you use?
- A . Activity Monitor
- B . Sp_who3
- C . SQL Server Management Studio (SSMS) Object Explorer
- D . SQL Server Data Collector
- E . SQL Server Data Tools (SSDT)
- F . SQL Server Configuration Manager
D
Explanation:
Data Collector can gather performance information from multiple SQL Server instances and store it in a single repository. It has three built-in data collecting specifications (data collectors) designed to collect the most important performance metrics. The information collected by default is about disk usage, query statistics, and server activity. The Query Statistics data collection set collects information about query statistics, activity, execution plans and text on the SQL Server instance. Missing indexes can be found with the execution plans.
References: https://www.sqlshack.com/sql-server-performance-monitoring-data-collector/
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You are a database administrator for a company that has an on-premises Microsoft SQL Server environment and Microsoft Azure SQL Database instances. The environment hosts several customer databases, and each customer uses a dedicated instance.
The environments that you manage are shown in the following table.
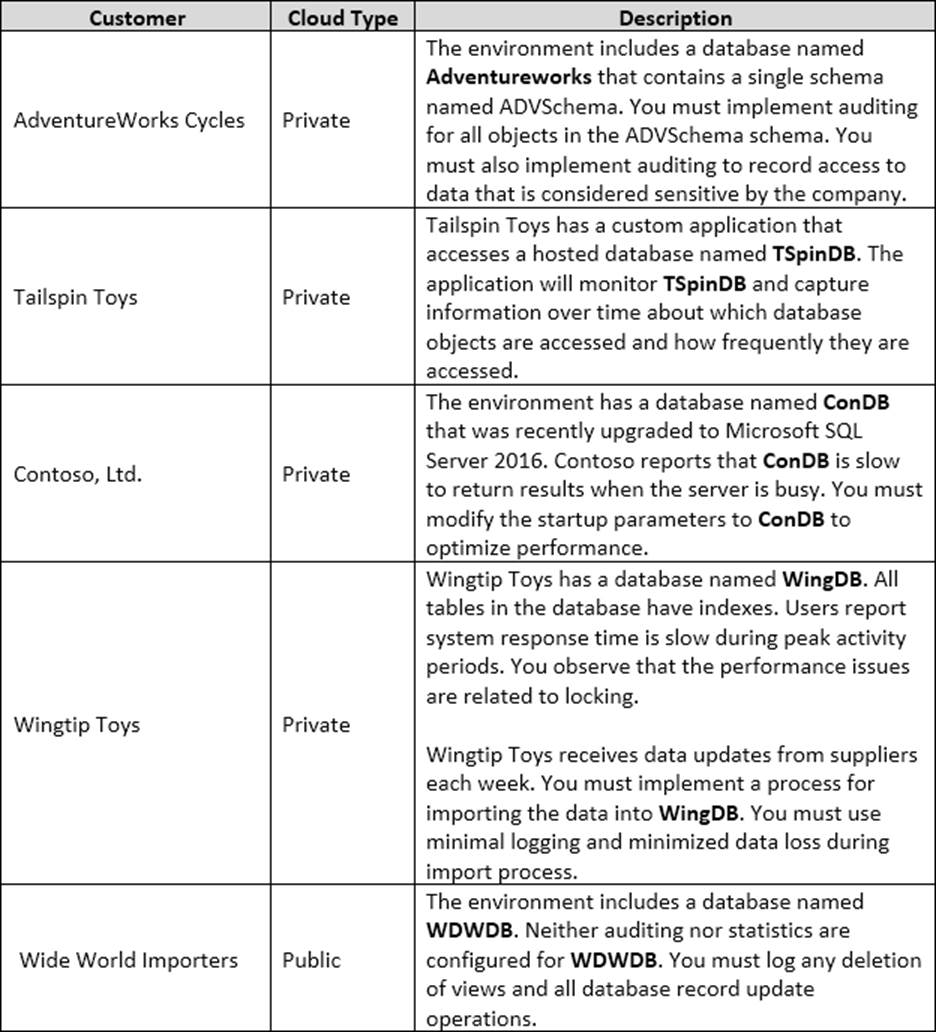

You need to configure monitoring for Tailspin Toys. In the table below, identify the monitoring tool that you must use for each activity. NOTE: Make only one selection in each column.



Explanation:
Monitoring from application: Transact-SQL
Transact-SQL can be used to monitor a customized application.
Trend analysis: System Monitor
System Monitor can provide trend analysis.
From question:
Tailspin Toys has a custom application that accesses a hosted database named TSpinDB. The application
will monitor TSpinDB and capture information over time about which database objects are accessed and
how frequently they are accessed.
References: https://docs.microsoft.com/en-us/sql/relational-databases/performance/performancemonitoring-
and-tuning-tools
DRAG DROP
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You are a database administrator for a company that has an on-premises Microsoft SQL Server environment and Microsoft Azure SQL Database instances. The environment hosts several customer databases, and each customer uses a dedicated instance.
The environments that you manage are shown in the following table.
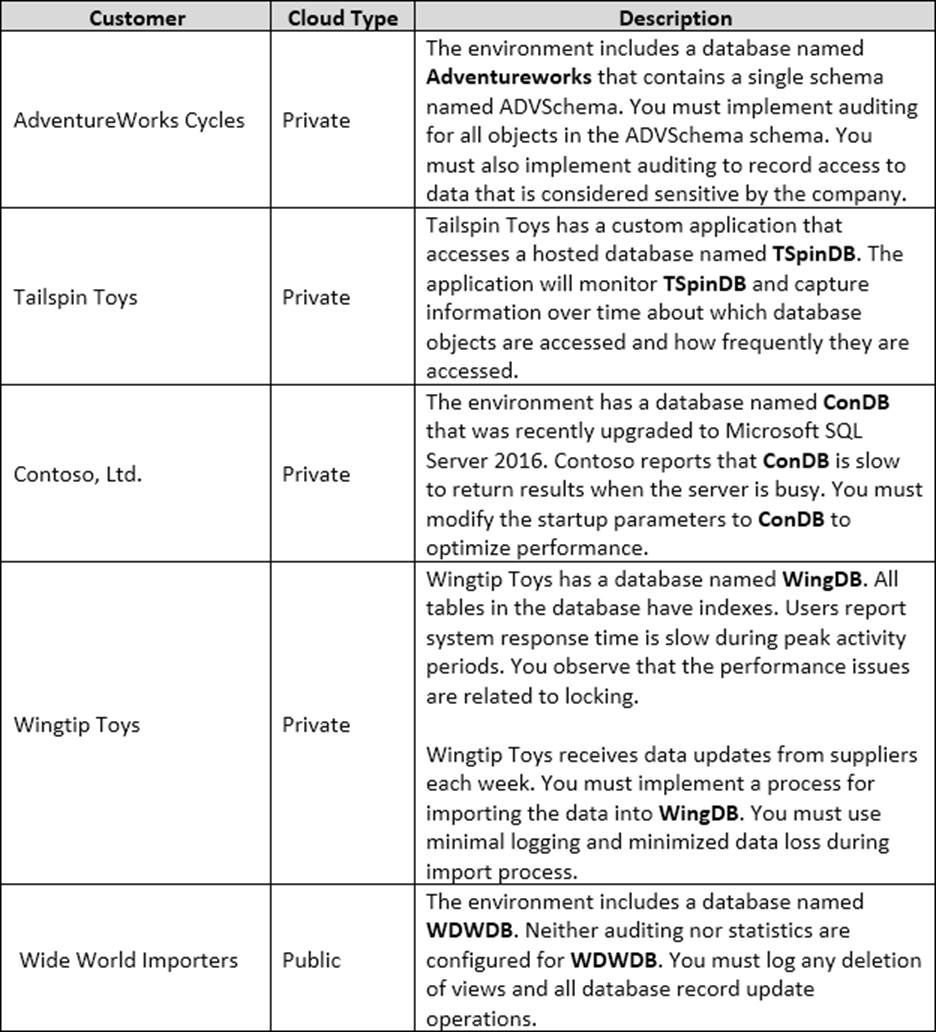
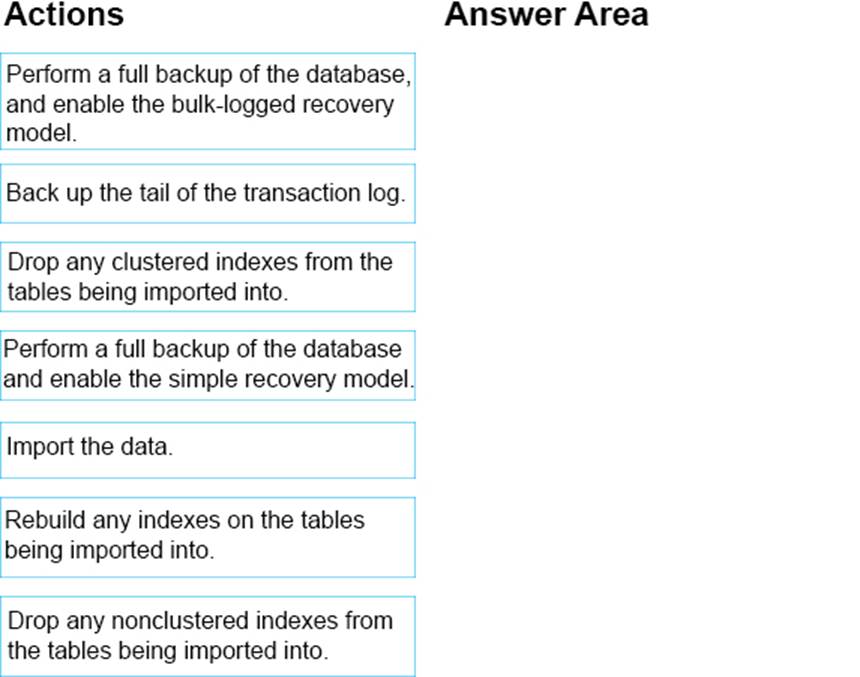
You need to implement a process for importing data into WingDB.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

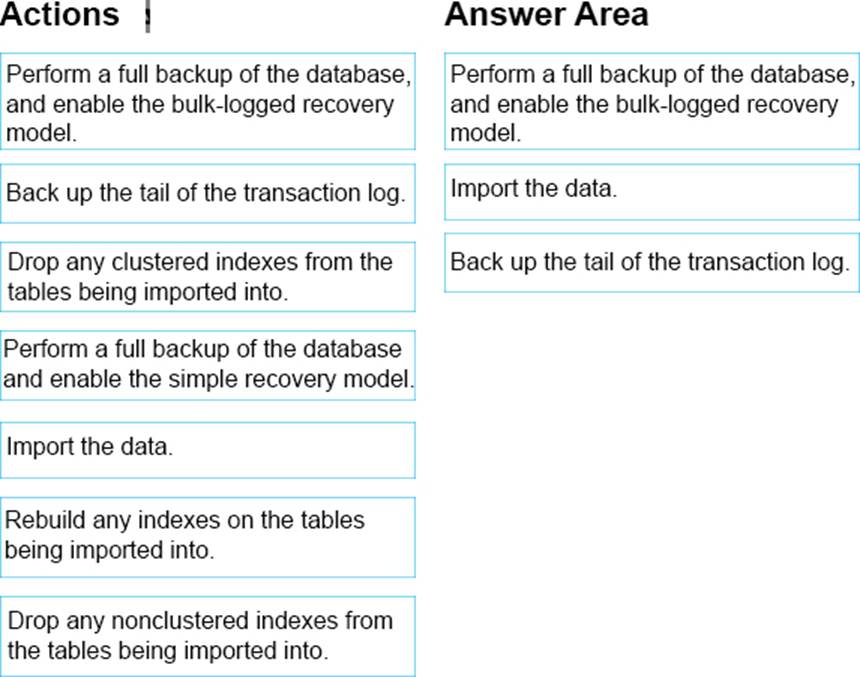
Explanation:
Step 1: Perform a full backup of the database and enable the bulk-logged recovery model.
Not: Simple recovery model. With the Simple recovery model we cannot minimize data loss.
Step 2: Import the data
Step 3: Backup the tail of the transaction log. For databases that use full and bulk-logged recovery, database backups are necessary but not sufficient. Transaction log backups are also required.
Note: Three recovery models exist: simple, full, and bulk-logged. Typically, a database uses the full recovery model or simple recovery model. A database can be switched to another recovery model at any time.
References: https://docs.microsoft.com/en-us/sql/relational-databases/backup-restore/recovery-modelssql-server
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You are a database administrator for a company that has an on-premises Microsoft SQL Server environment and Microsoft Azure SQL Database instances. The environment hosts several customer databases, and each customer uses a dedicated instance.
The environments that you manage are shown in the following table.
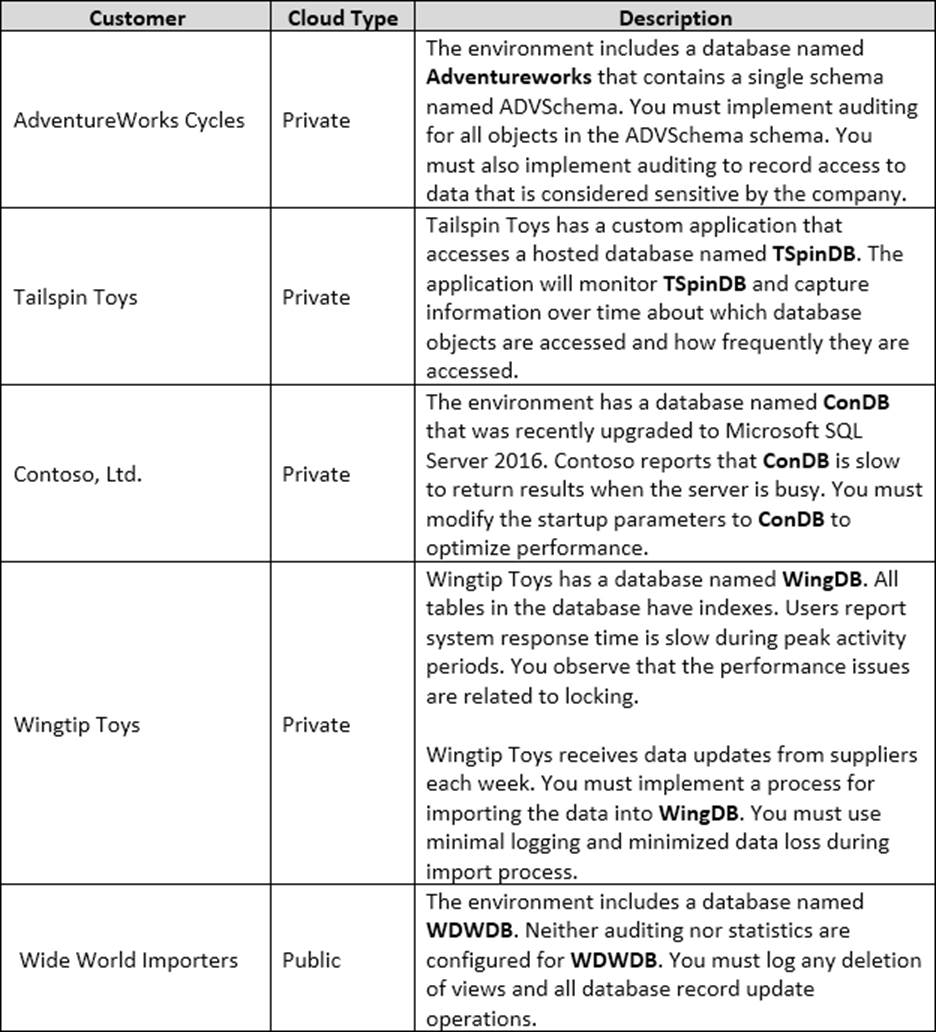
You need to configure auditing for the Adventure Works environment.
How should you complete the Transact-SQL statement? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
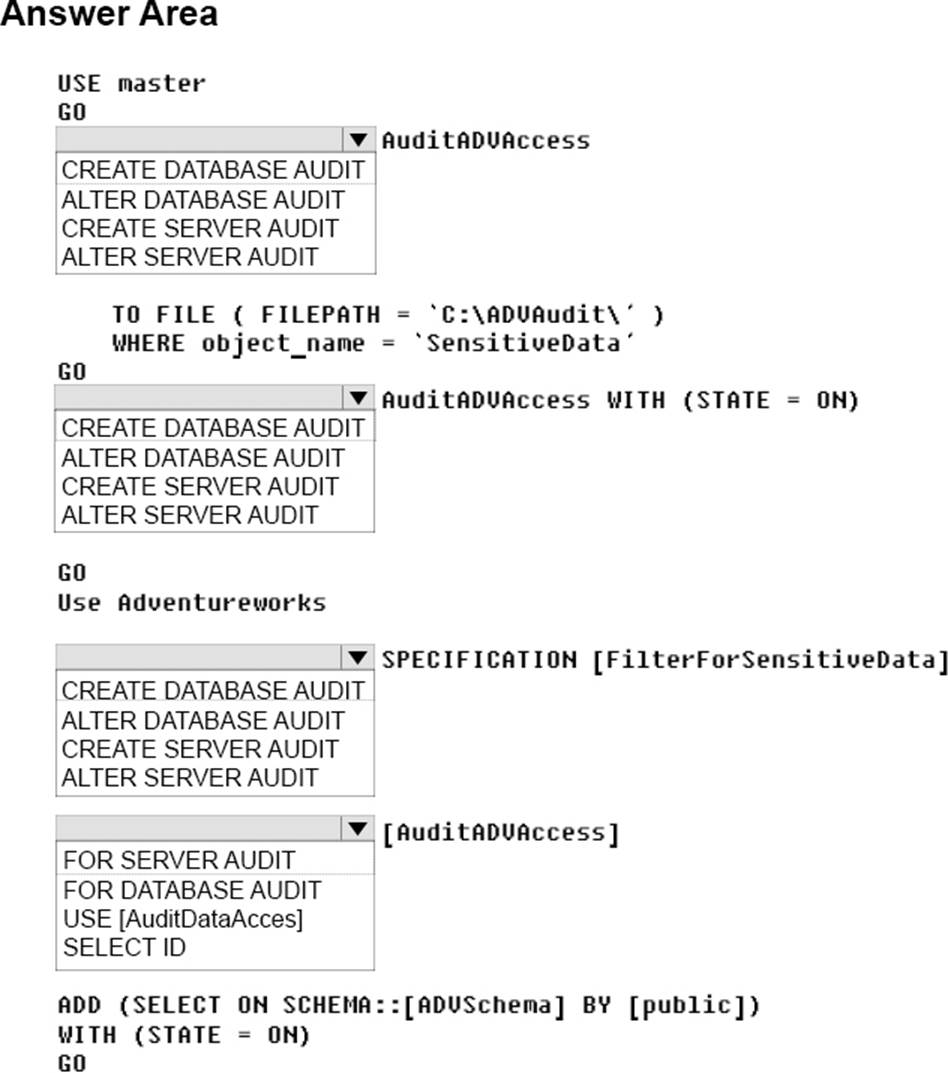

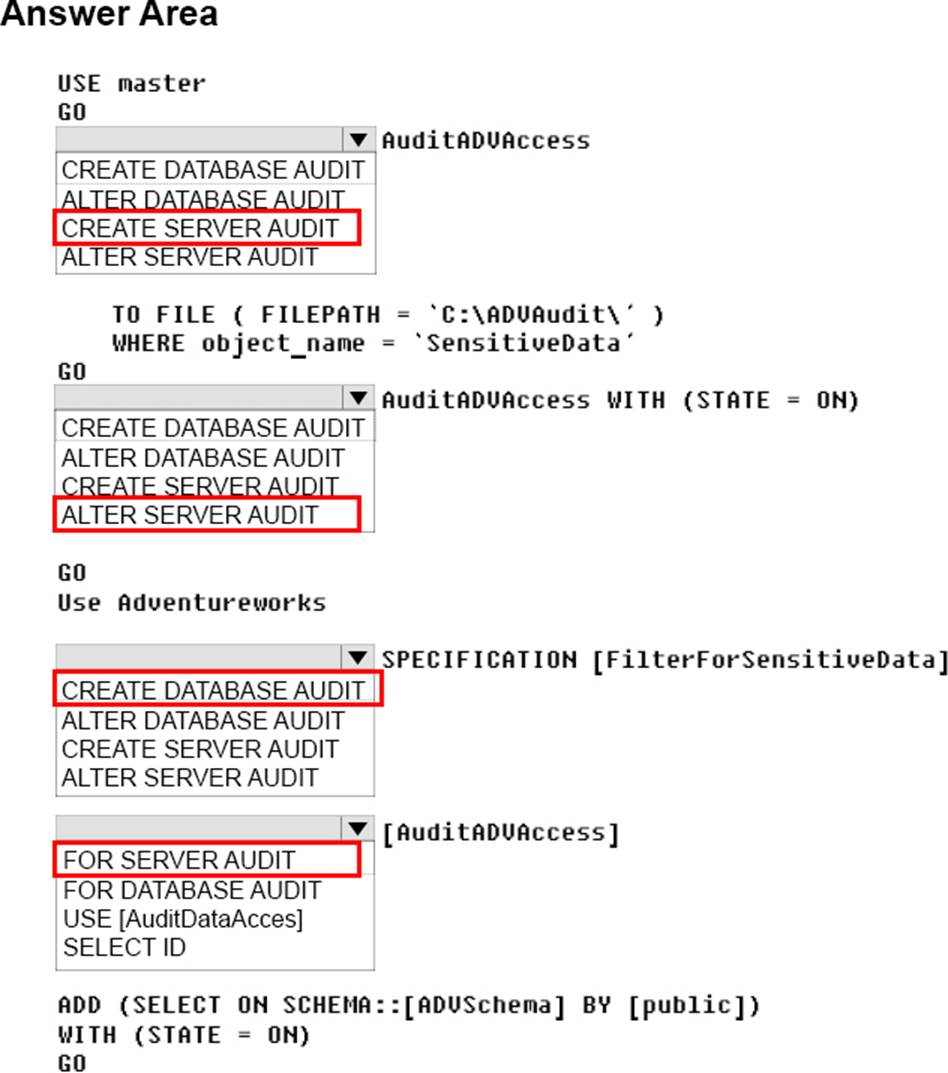
Explanation:
Box 1: CREATE SERVER AUDIT
Create the server audit.
You must implement auditing to record access to data that is considered sensitive by the company. Create database audit
Box 2: ALTER SERVER AUDIT
Enable the server audit.
Box 3: CREATE DATABASE AUDIT
Create the database audit specification.
Box 4: FOR SERVER AUDIIT
You must implement auditing for all objects in the ADVSchema.
References: https://docs.microsoft.com/en-us/sql/relational-databases/security/auditing/create-a-serveraudit-and-database-audit-specification
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You are a database administrator for a company that has an on-premises Microsoft SQL Server environment and Microsoft Azure SQL Database instances. The environment hosts several customer databases, and each customer uses a dedicated instance.
The environments that you manage are shown in the following table.
You need to configure the Contoso instance.
How should you complete the Transact-SQL statement? To answer, select the appropriate Transact-SQL segments in the answer area.



Explanation:
Box 1: show advanced options Advanced configuration options are displayed by first setting show advanced option to 1.
Box 2: max worker threads SQL Server uses the native thread services of the operating systems so that one or more threads support each network that SQL Server supports simultaneously, another thread handles database checkpoints, and a pool of threads handles all users. The default value for max worker threads is 0. This enables SQL Server to automatically configure the number of worker threads at startup. The default setting is best for most systems.
References: https://docs.microsoft.com/en-us/sql/database-engine/configure-windows/configurethe-max-worker-threads-server-configuration-option
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You are a database administrator for a company that has an on-premises Microsoft SQL Server environment and Microsoft Azure SQL Database instances. The environment hosts several customer databases, and each customer uses a dedicated instance.
The environments that you manage are shown in the following table.
You need to monitor WingDB and gather information for troubleshooting issues.
What should you use?
- A . sp_updatestats
- B . sp_lock
- C . sys.dm_os_waiting_tasks
- D . sys.dm_tran_active_snapshot_database_transactions
- E . Activity Monitor
B
Explanation:
The sp_lock system stored procedure is packaged with SQL Server and will give you insight into the locks that are happening on your system. This procedure returns much of its information from the syslock info in the master database, which is a system table that contains information on all granted, converting, and waiting lock requests.
Note: sp_lock will be removed in a future version of Microsoft SQL Server. Avoid using this feature in new development work, and plan to modify applications that currently use this feature. To obtain information about locks in the SQL Server Database Engine, use the sys.dm_tran_locks dynamic management view. sys.dm_tran_locks returns information about currently active lock manager resources in SQL Server 2008and later. Each row represents a currently active request to the lock manager for a lock that has been granted or is waiting to be granted.
References: https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sp-locktransact-sql
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You are a database administrator for a company that has an on-premises Microsoft SQL Server environment and Microsoft Azure SQL Database instances. The environment hosts several customer databases, and each customer uses a dedicated instance.
The environments that you manage are shown in the following table.
You need to configure auditing for WDWDB. In the table below, identify the event type that you must audit for each activity.



HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
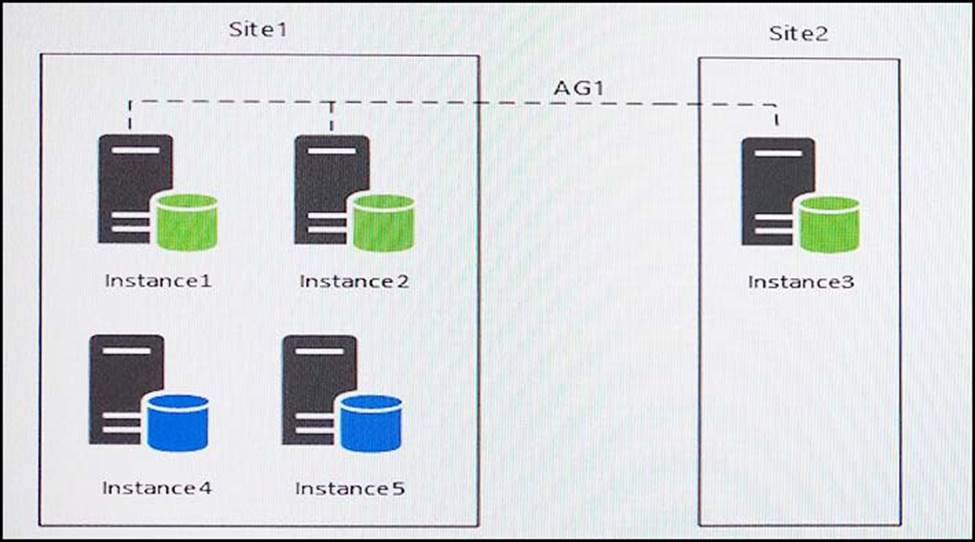
You have five servers that run Microsoft Windows 2012 R2. Each server hosts a Microsoft SQL Server instance. The topology for the environment is shown in the following diagram.
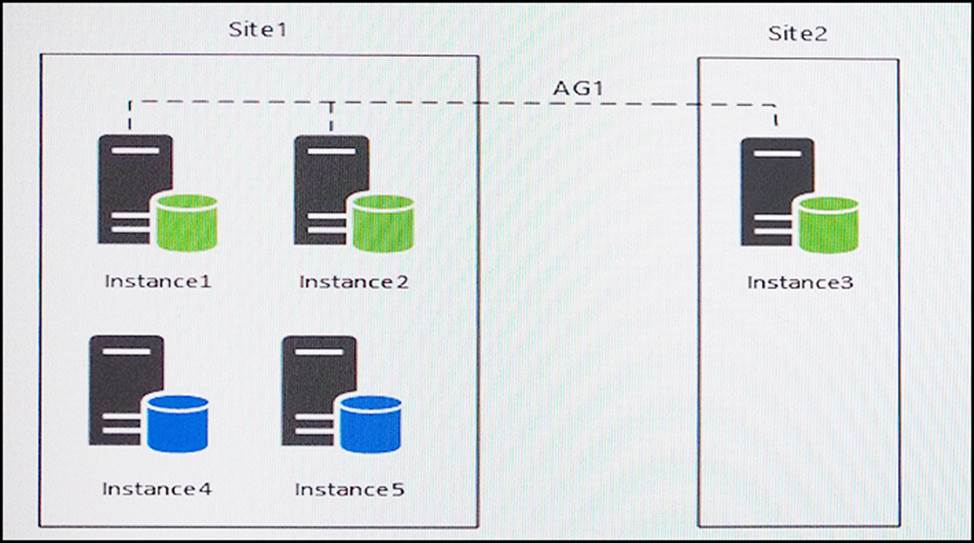

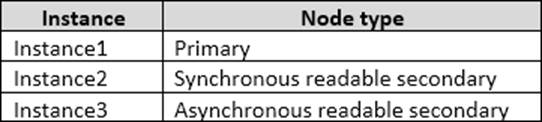
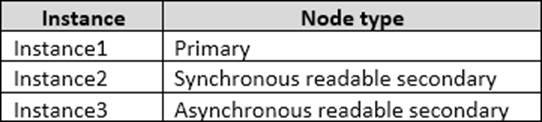
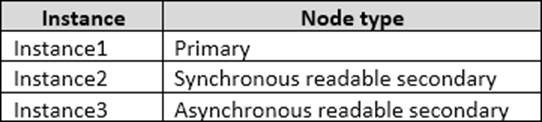
You have an Always On Availability group named AG1.
The details for AG1 are shown in the following table.

Instance1 experiences heavy read-write traffic. The instance hosts a database named OperationsMain that is four terabytes (TB) in size. The database has multiple data files and filegroups. One of the filegroups is read_only and is half of the total database size.
Instance4 and Instance5 are not part of AG1. Instance4 is engaged in heavy read-write I/O.
Instance5 hosts a database named StagedExternal. A nightly BULK INSERT process loads data into an empty table that has a rowstore clustered index and two nonclustered rowstore indexes.
You must minimize the growth of the StagedExternal database log file during the BULK INSERT operations and perform point-in-time recovery after the BULK INSERT transaction. Changes made must not interrupt the log backup chain.
You plan to add a new instance named Instance6 to a datacenter that is geographically distant from Site1 and Site2. You must minimize latency between the nodes in AG1.
All databases use the full recovery model. All backups are written to the network location \SQLBackup. A separate process copies backups to an offsite location. You should minimize both the time required to restore the databases and the space required to store backups.
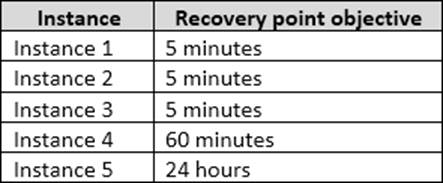
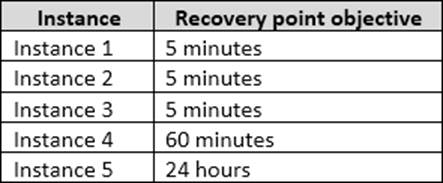
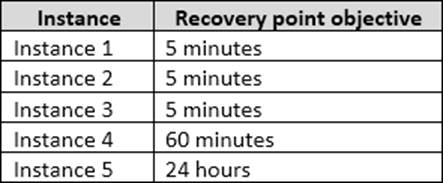
The recovery point objective (RPO) for each instance is shown in the following table.
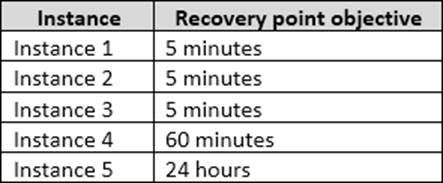

Full backups of OperationsMain take longer than six hours to complete. All SQL Server backups use the keyword COMPRESSION.
You plan to deploy the following solutions to the environment. The solutions will access a database named DB1 that is part of AG1.
-Reporting system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader role. The user has EXECUTE permissions on the database. Queries make no changes to the data. The queries must be load balanced over variable read-only replicas.
-Operations system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader and db_datawriter roles. The user has EXECUTE permissions on the database. Queries from the operations system will perform both DDL and DML operations.
The wait statistics monitoring requirements for the instances are described in the following table.


You need to create the connection strings for the operations and reporting systems.
In the table below, identify the option that must be specified in each connection string. NOTE: Make only one selection in each column.



Explanation:
Reporting system: Connect to any current read-only replica instance We configure Read-OnlyAccess on an Availability Replica. We select Read-intent only. Only read-only connections are allowed to secondary databases of this replica. The secondary database(s) are all available for read access.
From Scenario: Reporting system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader role. The user has EXECUTE permissions on the database. Queries make no changes to the data. The queries must be load balanced over variable read-only replicas.
Operating system: Connect to the current primary replica SQL instance By default, both read-write and read-intent access are allowed to the primary replica and no connections are allowed to secondary replicas of an Always On availability group.
From scenario: Operations system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader and db_datawriter roles. The user has EXECUTE permissions on the database. Queries from the operations system will perform both DDL and DML operations.
References: https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/configureread-only-access-on-an-availability-replica-sql-server
DRAG DROP
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have five servers that run Microsoft Windows 2012 R2. Each server hosts a Microsoft SQL Server instance. The topology for the environment is shown in the following diagram.

You have an Always On Availability group named AG1.
The details for AG1 are shown in the following table.
Instance1 experiences heavy read-write traffic. The instance hosts a database named OperationsMain that is four terabytes (TB) in size. The database has multiple data files and filegroups. One of the filegroups is read_only and is half of the total database size.
Instance4 and Instance5 are not part of AG1. Instance4 is engaged in heavy read-write I/O.
Instance5 hosts a database named StagedExternal. A nightly BULK INSERT process loads data into an empty table that has a rowstore clustered index and two nonclustered rowstore indexes.
You must minimize the growth of the StagedExternal database log file during the BULK INSERT operations and perform point-in-time recovery after the BULK INSERT transaction. Changes made must not interrupt the log backup chain.
You plan to add a new instance named Instance6 to a datacenter that is geographically distant from Site1 and Site2. You must minimize latency between the nodes in AG1.
All databases use the full recovery model. All backups are written to the network location \SQLBackup. A separate process copies backups to an offsite location. You should minimize both the time required to restore the databases and the space required to store backups.
The recovery point objective (RPO) for each instance is shown in the following table.
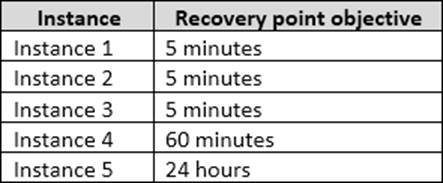
Full backups of OperationsMain take longer than six hours to complete. All SQL Server backups use the keyword COMPRESSION.
You plan to deploy the following solutions to the environment. The solutions will access a database named DB1 that is part of AG1.
-Reporting system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader role. The user has EXECUTE permissions on the database. Queries make no changes to the data. The queries must be load balanced over variable read-only replicas.
-Operations system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader and db_datawriter roles. The user has EXECUTE permissions on the database. Queries from the operations system will perform both DDL and DML operations.
The wait statistics monitoring requirements for the instances are described in the following table.

You need to propose a new process for the StagedExternal database.
Which five actions should you recommended be performed in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
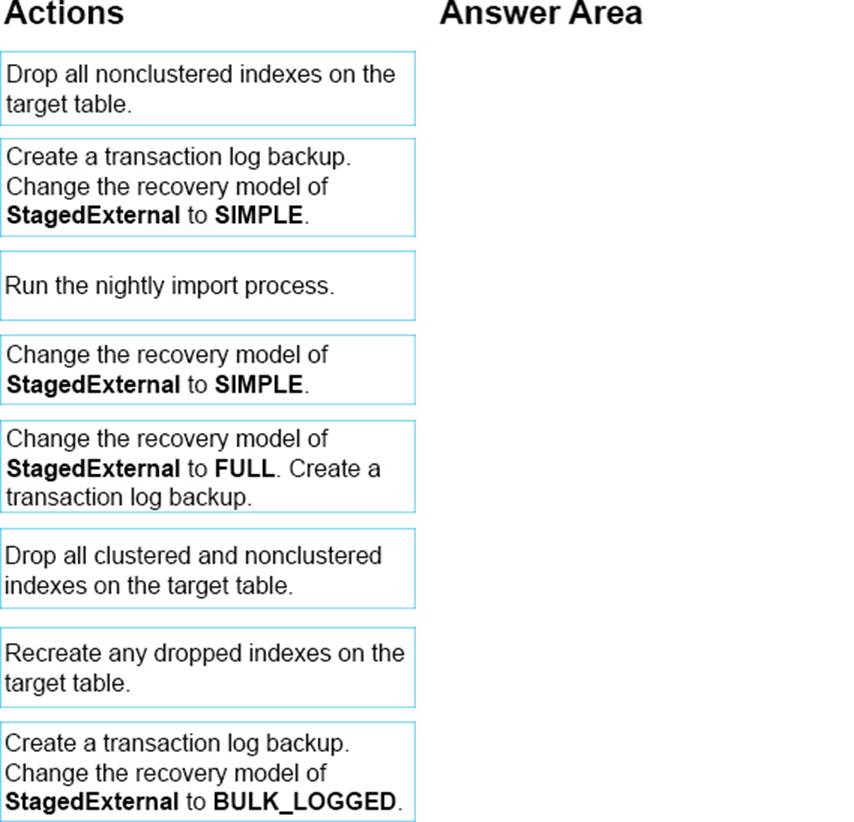

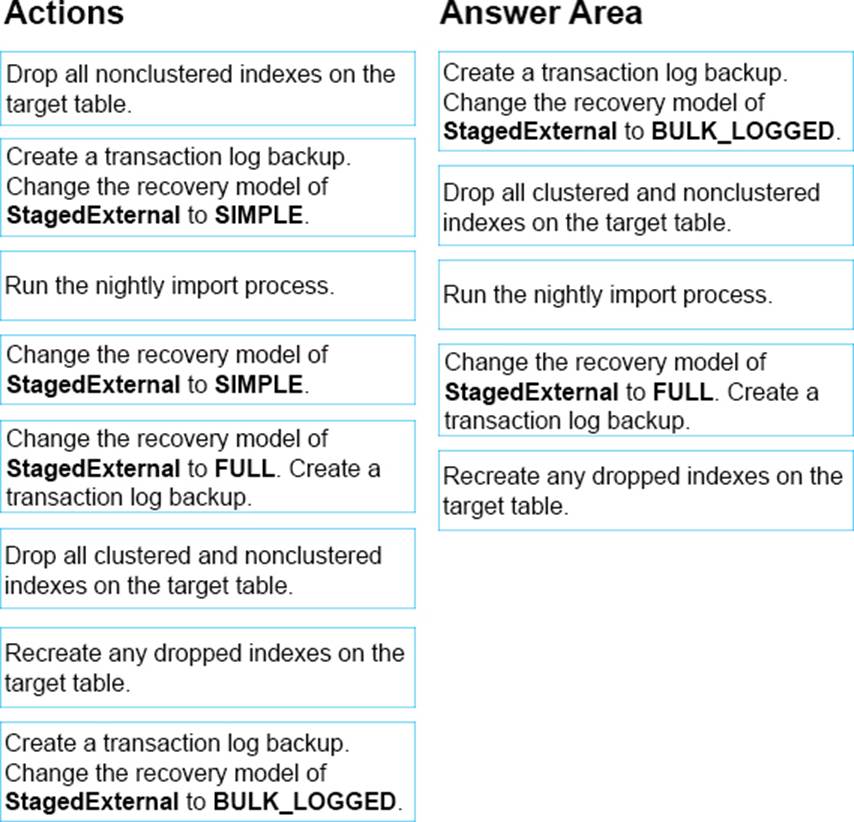
Explanation:
From scenario: Instance5 hosts a database named StagedExternal. A nightly BULK INSERT process loads data into an empty table that has a rowstore clustered index and two nonclustered rowstore indexes. You must minimize the growth of the StagedExternaldatabase log file during the BULK INSERT operations and perform point-in-time recovery after the BULK INSERT transaction. Changes made must not interrupt the log backup chain.
All databases use the full recovery model.
References: https://technet.microsoft.com/en-us/library/ms190421(v=sql.105).aspx
DRAG DROP
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have five servers that run Microsoft Windows 2012 R2. Each server hosts a Microsoft SQL Server instance. The topology for the environment is shown in the following diagram.
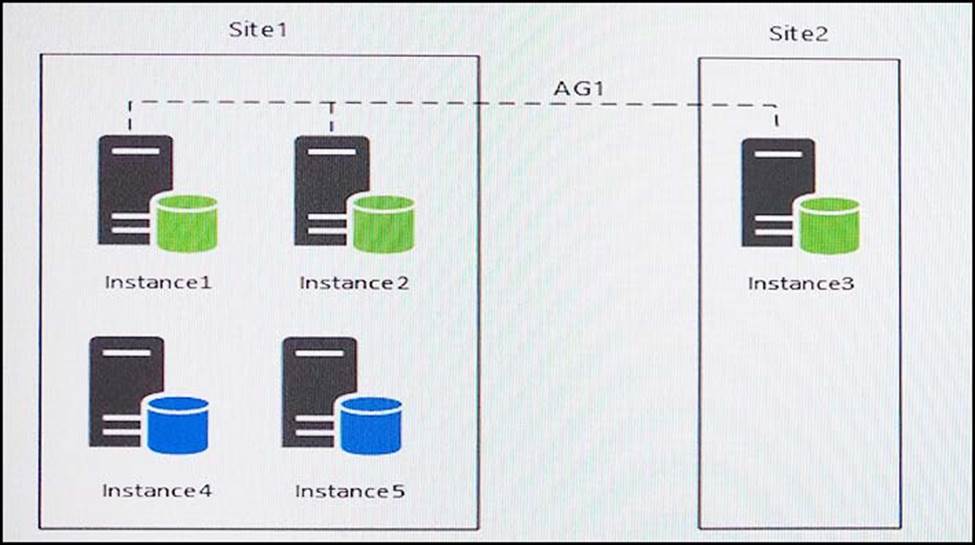

You have an Always On Availability group named AG1.
The details for AG1 are shown in the following table.
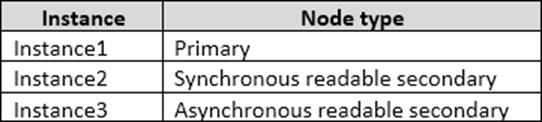
Instance1 experiences heavy read-write traffic. The instance hosts a database named OperationsMain that is four terabytes (TB) in size. The database has multiple data files and filegroups. One of the filegroups is read_only and is half of the total database size.
Instance4 and Instance5 are not part of AG1. Instance4 is engaged in heavy read-write I/O.
Instance5 hosts a database named StagedExternal. A nightly BULK INSERT process loads data into an empty table that has a rowstore clustered index and two nonclustered rowstore indexes.
You must minimize the growth of the StagedExternal database log file during the BULK INSERT operations and perform point-in-time recovery after the BULK INSERT transaction. Changes made must not interrupt the log backup chain.
You plan to add a new instance named Instance6 to a datacenter that is geographically distant from Site1 and Site2. You must minimize latency between the nodes in AG1.
All databases use the full recovery model. All backups are written to the network location \SQLBackup. A separate process copies backups to an offsite location. You should minimize both the time required to restore the databases and the space required to store backups.
The recovery point objective (RPO) for each instance is shown in the following table.
Full backups of OperationsMain take longer than six hours to complete. All SQL Server backups use the keyword COMPRESSION.
You plan to deploy the following solutions to the environment. The solutions will access a database named DB1 that is part of AG1.
Reporting system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader role. The user has EXECUTE permissions on the database. Queries make no changes to the data. The queries must be load balanced over variable read-only replicas. Operations system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader and db_datawriter roles. The user has EXECUTE permissions on the database. Queries from the operations system will perform both DDL and DML operations.
The wait statistics monitoring requirements for the instances are described in the following table.

You need to analyze the wait type and statistics for specific instanced in the environment.
Which object should you use to gather information about each instance? To answer, drag the appropriate objects to the correct instances. Each object may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.



Explanation:
Instance 1: sys.dm_exec_query_stats From Scenario: Instance1 requirement: Aggregate statistics since last server restart. sys.dm_exec_query_stats returns aggregate performance statistics for cachedquery plans in SQL Server.
Instance 4: sys.dm_os_wait_stats sys.dm_os_wait_statsreturns information about all the waits encountered by threads that executed. From Scenario: Instance4 requirement: Identify the most prominent wait types.
![]()

Instance 5:sys.dm_exec_session_wait_stats From Scenario: Instance5 requirement: Identify all wait types for queries currently running on the server. sys.dm_exec_session_wait_stats returns information about all the waits encountered by threads that executed for each session.
DRAG DROP
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have five servers that run Microsoft Windows 2012 R2. Each server hosts a Microsoft SQL Server instance. The topology for the environment is shown in the following diagram.
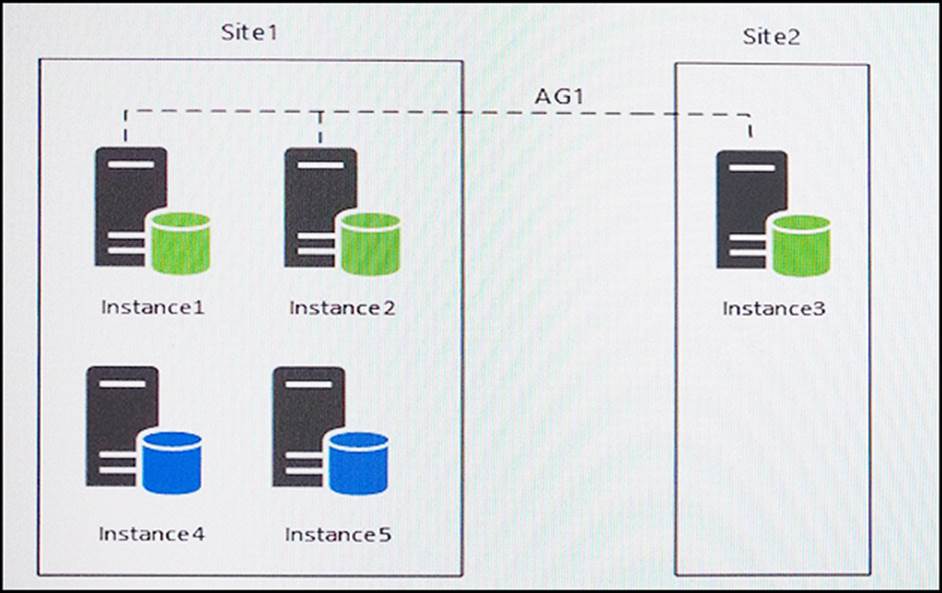

You have an Always On Availability group named AG1.
The details for AG1 are shown in the following table.
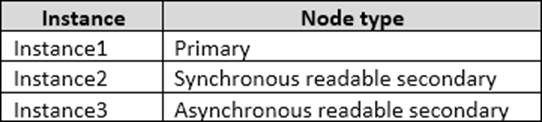
Instance1 experiences heavy read-write traffic. The instance hosts a database named OperationsMain that is four terabytes (TB) in size. The database has multiple data files and filegroups. One of the filegroups is read_only and is half of the total database size.
Instance4 and Instance5 are not part of AG1. Instance4 is engaged in heavy read-write I/O.
Instance5 hosts a database named StagedExternal. A nightly BULK INSERT process loads data into an empty table that has a rowstore clustered index and two nonclustered rowstore indexes.
You must minimize the growth of the StagedExternal database log file during the BULK INSERT operations and perform point-in-time recovery after the BULK INSERT transaction. Changes made must not interrupt the log backup chain.
You plan to add a new instance named Instance6 to a datacenter that is geographically distant from Site1 and Site2. You must minimize latency between the nodes in AG1.
All databases use the full recovery model. All backups are written to the network location \SQLBackup. A separate process copies backups to an offsite location. You should minimize both the time required to restore the databases and the space required to store backups.
The recovery point objective (RPO) for each instance is shown in the following table.
Full backups of OperationsMain take longer than six hours to complete. All SQL Server backups
use the keyword COMPRESSION.
You plan to deploy the following solutions to the environment. The solutions will access a database named DB1 that is part of AG1.
-Reporting system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader role. The user has EXECUTE permissions on the database. Queries make no changes to the data. The queries must be load balanced over variable read-only replicas.
-Operations system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader and db_datawriter roles. The user has EXECUTE permissions on the database. Queries from the operations system will perform both DDL and DML operations.
The wait statistics monitoring requirements for the instances are described in the following table.

You need to configure a new replica of AG1 on Instance6.
How should you complete the Transact-SQL statement? To answer, drag the appropriate Transact-SQL statements to the correct locations. Each Transact-SQL segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
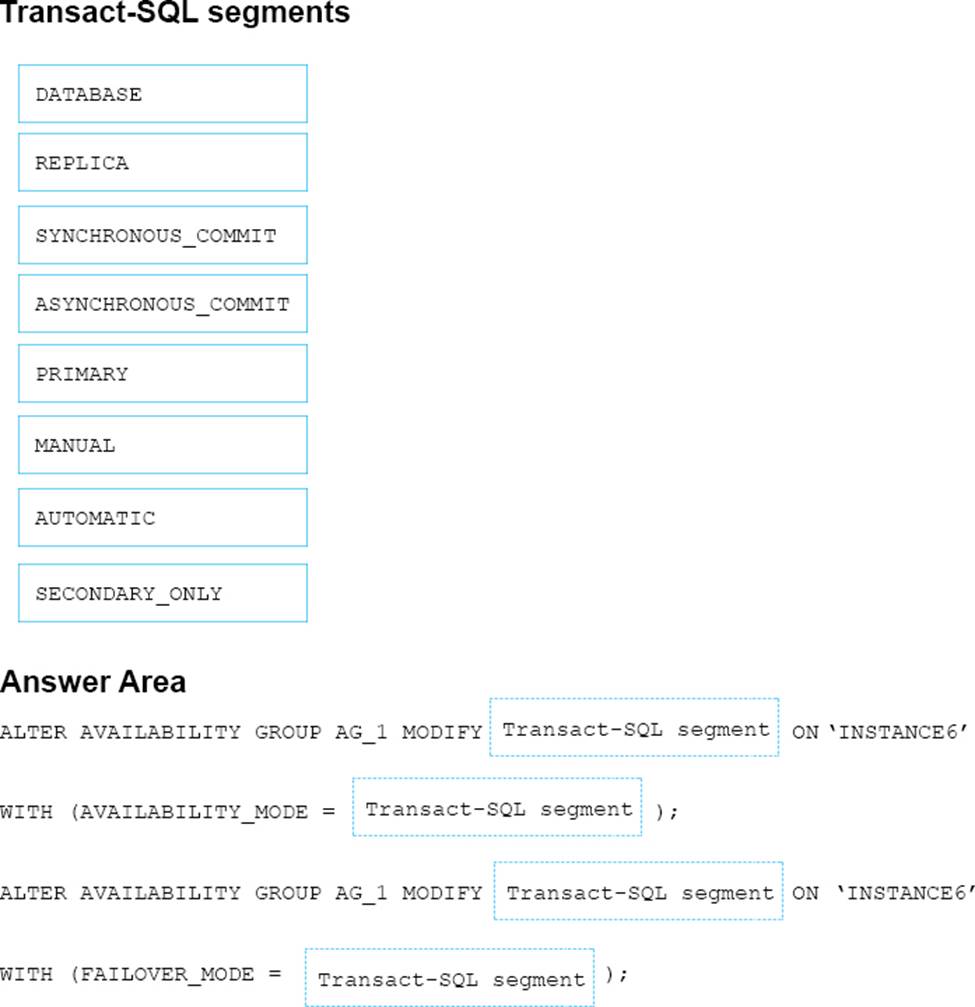

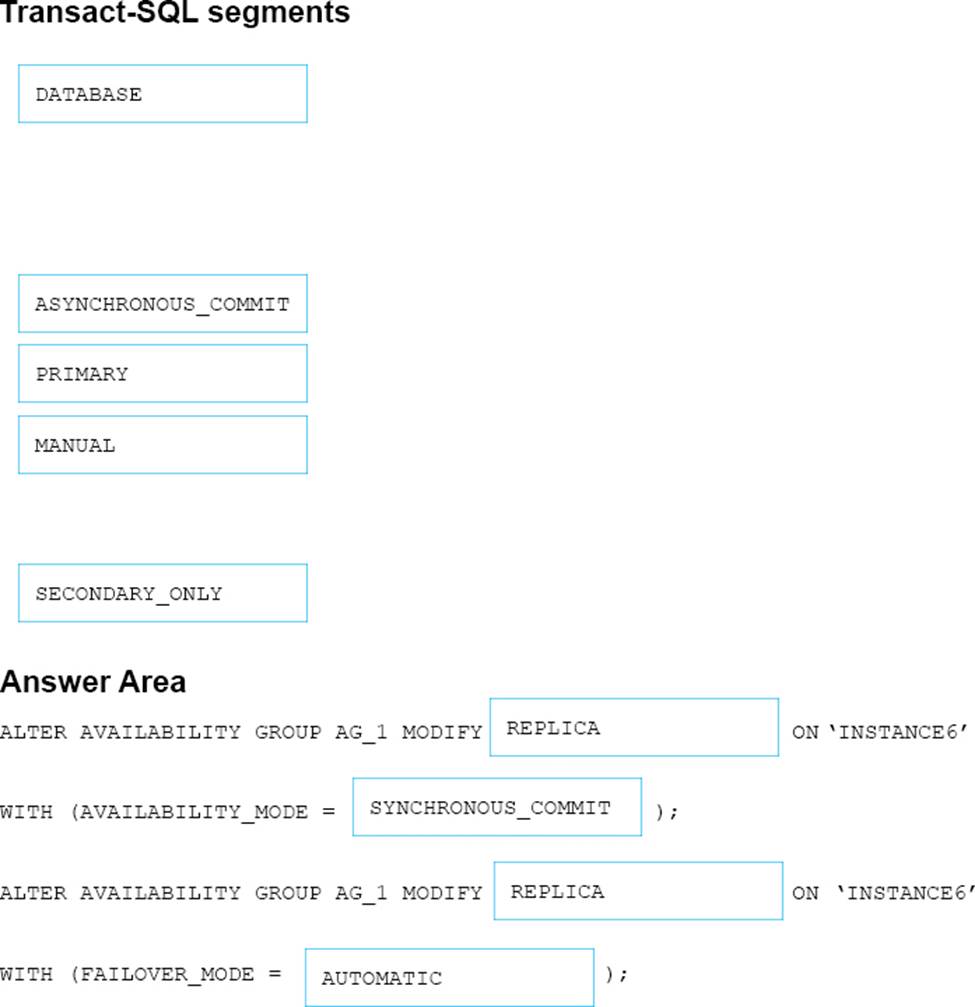
Explanation:
Scenario: You plan to add a new instance named Instance6 to a datacenter that is geographically distant from Site1 and Site2. You must minimize latency between the nodes in AG1.
Box 1: REPLICA
MODIFY REPLICA ON modifies any of the replicas ofthe availability group.
Box 2: SYNCHRONOUS_COMMIT
You must minimize latency between the nodes in AG1
AVAILABILITY_MODE = {SYNCHRONOUS_COMMIT | ASYNCHRONOUS_COMMIT}
Specifies whether the primary replica has to wait for the secondary availability group to acknowledge the hardening (writing) of the log records to disk before the primary replica can commit the transaction on a given primary database.
FAILOVER AUTOMATIC (box 4) requires SYNCHRONOUS_COMMIT
Box 3: REPLICA
MODIFY REPLICA ON modifies any of the replicas of the availability group.
Box 4: AUTOMATIC
You must minimize latency between the nodes in AG1
FAILOVER_MODE = {AUTOMATIC | MANUAL}
Specifies the failover mode of the availability replica that you are defining.
FAILOVER_MODE is required in the ADD REPLICA ON clause and optional in the MODIFY REPLICA ON clause.
AUTOMATIC enables automatic failover. AUTOMATIC is supported only if you also specify AVAILABILITY_MODE = SYNCHRONOUS_COMMIT.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-availability-group-transact-sql
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have five servers that run Microsoft Windows 2012 R2. Each server hosts a Microsoft SQL Server instance. The topology for the environment is shown in the following diagram.
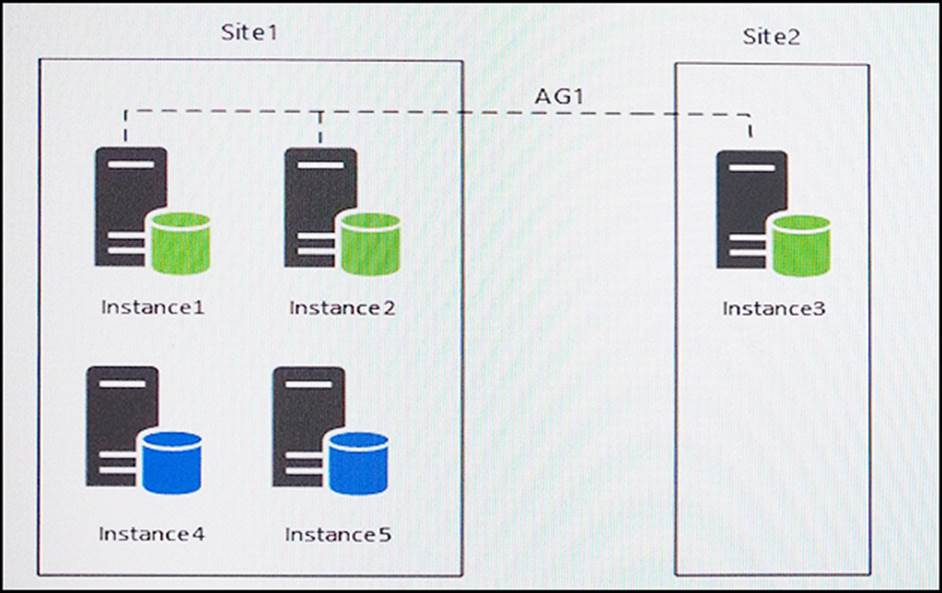
You have an Always On Availability group named AG1.
The details for AG1 are shown in the following table.
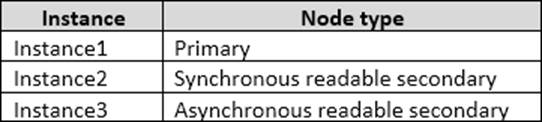
Instance1 experiences heavy read-write traffic. The instance hosts a database named OperationsMain that is four terabytes (TB) in size. The database has multiple data files and filegroups. One of the filegroups is read_only and is half of the total database size.
Instance4 and Instance5 are not part of AG1. Instance4 is engaged in heavy read-write I/O.
Instance5 hosts a database named StagedExternal. A nightly BULK INSERT process loads data into an empty table that has a rowstore clustered index and two nonclustered rowstore indexes.
You must minimize the growth of the StagedExternal database log file during the BULK INSERT operations and perform point-in-time recovery after the BULK INSERT transaction. Changes made must not interrupt the log backup chain.
You plan to add a new instance named Instance6 to a datacenter that is geographically distant from Site1 and Site2. You must minimize latency between the nodes in AG1.
All databases use the full recovery model. All backups are written to the network location \SQLBackup. A separate process copies backups to an offsite location. You should minimize both the time required to restore the databases and the space required to store backups.
The recovery point objective (RPO) for each instance is shown in the following table.
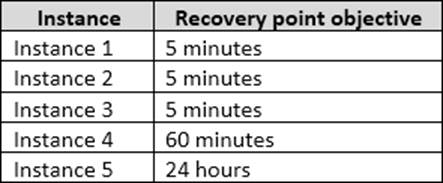
Full backups of OperationsMain take longer than six hours to complete. All SQL Server backups use the keyword COMPRESSION.
You plan to deploy the following solutions to the environment. The solutions will access a database named DB1 that is part of AG1.
-Reporting system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader role. The user has EXECUTE permissions on the database. Queries make no changes to the data. The queries must be load balanced over variable read-only replicas.
-Operations system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader and db_datawriter roles. The user has EXECUTE permissions on the database. Queries from the operations system will perform both DDL and DML operations.
The wait statistics monitoring requirements for the instances are described in the following table.

You need to create a backup plan for Instance4.
Which backup plan should you create?
- A . Weekly full backups, nightly differential. No transaction log backups are necessary.
- B . Weekly full backups, nightly differential backups, transaction log backups every 5 minutes.
- C . Weekly full backups, nightly differential backups, transaction log backups every 12 hours.
- D . Full backups every 60 minutes, transaction log backups every 30 minutes.
B
Explanation:
From scenario: Instance4 and Instance5 are not part of AG1. Instance4 is engaged in heavy read-write I/O. The recovery point objective of Instancse4 is 60 minutes. RecoveryPoint Objectives are commonly described as the amount of data that was lost during the outage and recovery period. You should minimize both the time required to restore the databases and the space required to store backups.
References: http://sqlmag.com/blog/sql-server-recovery-time-objectives-and-recovery-pointobjectives
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have five servers that run Microsoft Windows 2012 R2. Each server hosts a Microsoft SQL Server instance. The topology for the environment is shown in the following diagram.
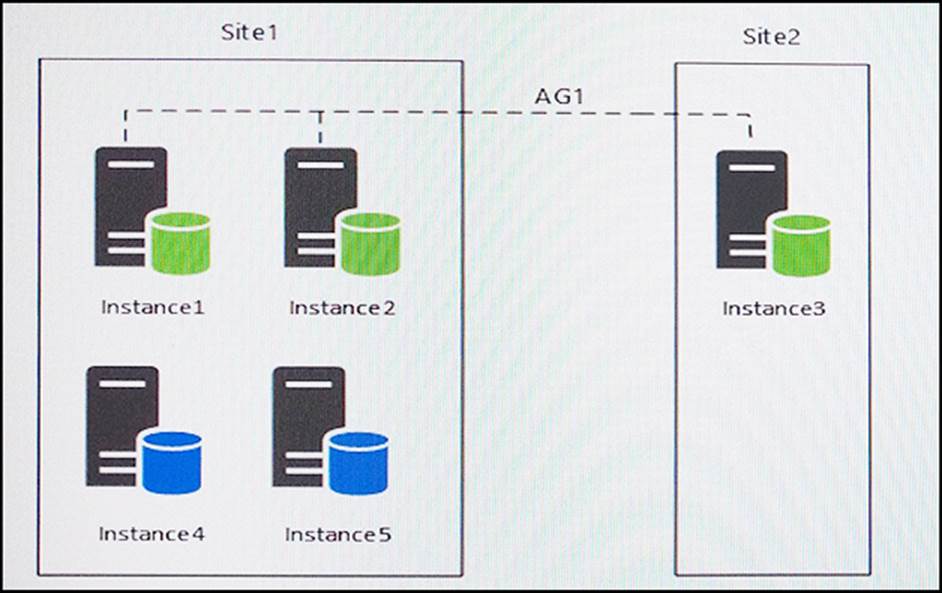
You have an Always On Availability group named AG1.
The details for AG1 are shown in the following table.
Instance1 experiences heavy read-write traffic. The instance hosts a database named OperationsMain that is four terabytes (TB) in size. The database has multiple data files and filegroups. One of the filegroups is read_only and is half of the total database size.
Instance4 and Instance5 are not part of AG1. Instance4 is engaged in heavy read-write I/O.
Instance5 hosts a database named StagedExternal. A nightly BULK INSERT process loads data into an empty table that has a rowstore clustered index and two nonclustered rowstore indexes.
You must minimize the growth of the StagedExternal database log file during the BULK INSERT operations and perform point-in-time recovery after the BULK INSERT transaction. Changes made must not interrupt the log backup chain.
You plan to add a new instance named Instance6 to a datacenter that is geographically distant from Site1 and Site2. You must minimize latency between the nodes in AG1.
All databases use the full recovery model. All backups are written to the network location \SQLBackup. A separate process copies backups to an offsite location. You should minimize both the time required to restore the databases and the space required to store backups.
The recovery point objective (RPO) for each instance is shown in the following table.
Full backups of OperationsMain take longer than six hours to complete. All SQL Server backups use the keyword COMPRESSION.
You plan to deploy the following solutions to the environment. The solutions will access a database named DB1 that is part of AG1.
-Reporting system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader role. The user has EXECUTE permissions on the database. Queries make no changes to the data. The queries must be load balanced over variable read-only replicas.
-Operations system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader and db_datawriter roles. The user has EXECUTE permissions on the database. Queries from the operations system will perform both DDL and DML operations.
The wait statistics monitoring requirements for the instances are described in the following table.

You need to reduce the amount of time it takes to backup OperationsMain.
What should you do?
- A . Modify the backup script to use the keyword SKIP in the FILE_SNAPSHOT statement.
- B . Modify the backup script to use the keyword SKIP in the WITH statement
- C . Modify the backup script to use the keyword NO_COMPRESSION in the WITH statement.
- D . Modify the full database backups script to stripe the backup across multiple backup files.
D
Explanation:
One of the filegroup is read_only should be as it only need to be backup up once. Partial backups are useful whenever you want to exclude read-only filegroups. A partial backup resembles a full database backup, but a partial backup does not contain all the filegroups. Instead, for a read-write database, a partial backup contains the data in the primary filegroup, every read-write filegroup, and, optionally, one or more read-only files. A partial backup of a read-only database contains only the primary filegroup.
From scenario: Instance1 experiences heavy read-write traffic. The instance hosts a database named OperationsMainthat is four terabytes (TB) in size. The database has multiple data files and filegroups. One of the filegroups is read_only and is half of the total database size.
References: https://docs.microsoft.com/en-us/sql/relational-databases/backup-restore/partialbackups-sql-server
DRAG DROP
You have a database.
The existing backups for the database and their corresponding files are listed in the following table.
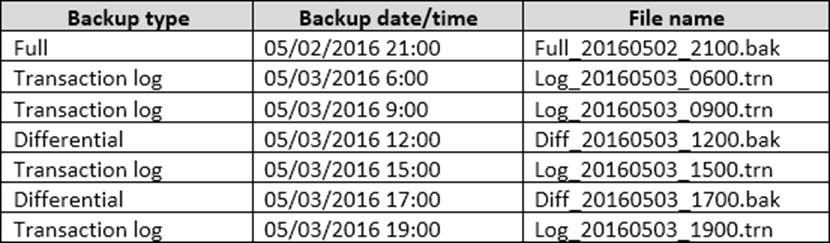

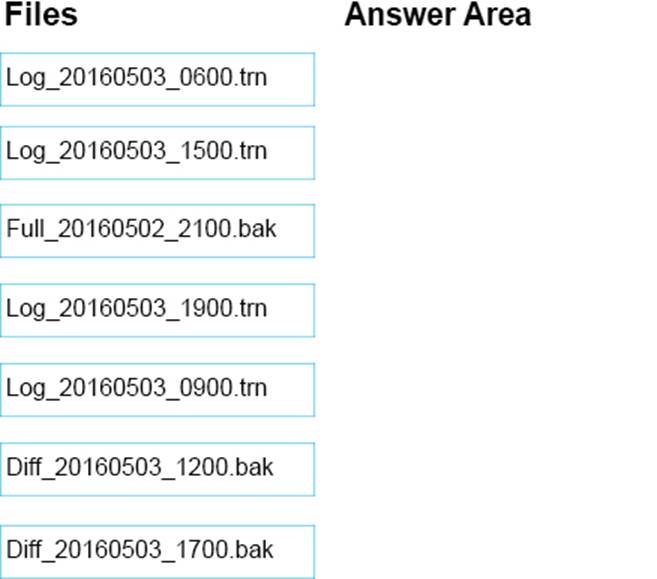
You purchase a new server. You must restore the database to the new server.
You need to restore the data to the most recent time possible.
Which three files should you restore in sequence? To answer, move the appropriate files from the list of files to the answer area and arrange them in the correct order.

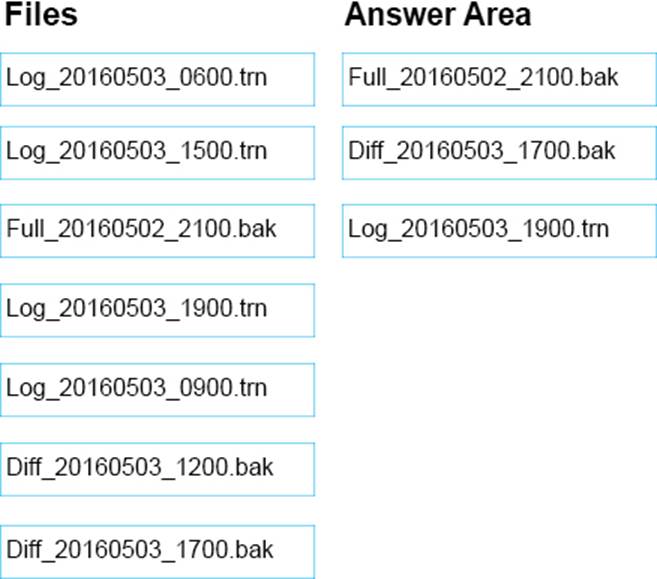
Explanation:
Step 1: Full. Start with the full backup.
Step 2: Diff_20160503_1700.bak
Followed by the most recent differential backup.
Step 3: Log_20160503_1900.bak
And finally the most recent log backup (the only log backup done after the most recent differential backup).
References: https://docs.microsoft.com/en-us/sql/relational-databases/backup-restore/differentialbackups-sql-server
A Microsoft SQL Server database named DB1 has two filegroups named FG1 and FG2. You implement a backup strategy that creates backups for the filegroups.
DB1 experiences a failure. You must restore FG1 and then FG2.
You need to ensure that the database remains in the RECOVERING state until the restoration of FG2 completes. After the restoration of FG2 completes, the database must be online.
What should you specify when you run the recovery command?
- A . the WITH NORECOVERY clause for FG1 and the WITH RECOVERY clause for FG2
- B . the WITH RECOVERY clause for FG1 and the WITH RECOVERY clause for FG2
- C . the WITH RECOVERY clause for both FG1 and FG2
- D . the WITH NORECOVERY clause for both FG1 and FG2
DRAG DROP
You have a test server that contains a database named DB1. Backups of the database are written to a single backup device. The backup device has a full, differential, and transaction log backup.
You discover that the database is damaged. You restore the database to the point at which the differential backup was taken.
You need to rebuild the database with data stored in the latest transaction logs.
How should you complete the Transact-SQL statement? To answer. drag the appropriate Transact-SQL segments to the correct locations. Each Transact-SQL segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
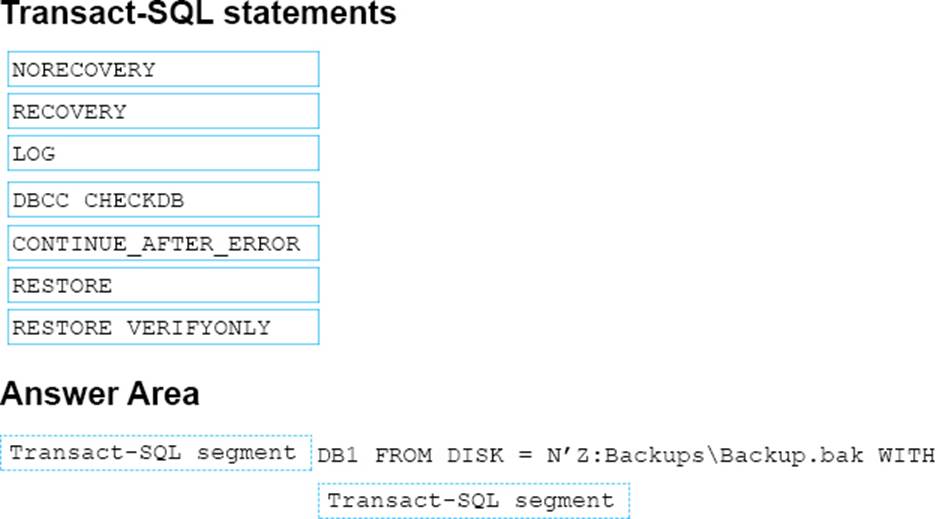

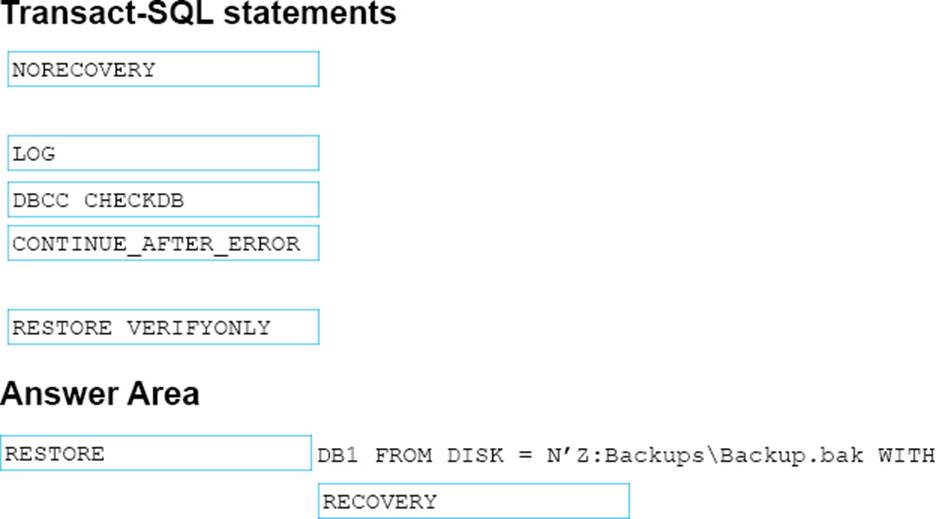
Explanation:
Box 1: RESTORE
Box 2: RECOVERY
The RESTORE … WITH RECOVERY option puts the database into a useable state, so users can access a restored database.
References: https://www.mssqltips.com/sqlservertutorial/112/recovering-a-database-that-is-in-therestoring-state/
You have a database named DB1 that is configured to use the full recovery model. You have a full daily backup job that runs at 02:00. The job backs up data from DB1 to the file B:DB1.bak.
You need to restore the DB1 database to the point in time of May 25, 2016 at 02:23 and ensure
that the database is functional and starts to accept connections.
Which Transact-SQL statement should you run?


- A . Option A
- B . Option B
- C . Option C
- D . Option D
HOTSPOT
You manage a Microsoft-SQL Server database named sales Orders.
You need to verify the integrity of the database and attempt to repair any errors that are found. Repair must not cause any data to be lost in the database.
How should you complete the DBCC command? To answer, select the appropriate options in the answer area.
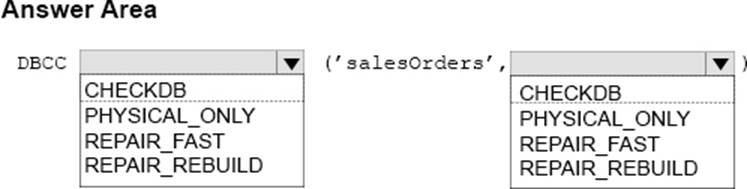

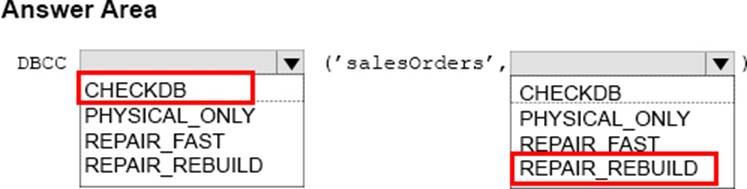
Explanation:
Box 1: CHECKDB
DBCC CHECKDB checks the logical and physical integrity of all the objects in the specified database.
Partial syntax:
DBCC CHECKDB
[ ( database_name | database_id | 0
[ , NOINDEX
| , { REPAIR_ALLOW_DATA_LOSS | REPAIR_FAST | REPAIR_REBUILD } ]
….
Box 2: REPAIR_REBUILD
DBCC CHECKDB …REPAIR_ALLOW_DATA_LOSS | REPAIR_FAST |REPAIR_REBUILD specifies that DBCC CHECKDB repair the found errors.
REPAIR_REBUILD performs repairs that have no possibility of data loss. This can include quick repairs, such as repairing missing rows in non-clustered indexes, and more time-consuming repairs, such as rebuilding an index.
References: https://docs.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcc-checkdb-transact-sql
HOTSPOT
You manage a Microsoft SQL Server environment. You have a database named salesOrders that includes a table named Table1. Table1 becomes corrupt. You repair the table.
You need to verify that all the data in Table1 complies with the schema.
How should you complete the Transact-SQL code statement? To answer, select the appropriate Transact-SQL code segments in the dialog box in the answer area.
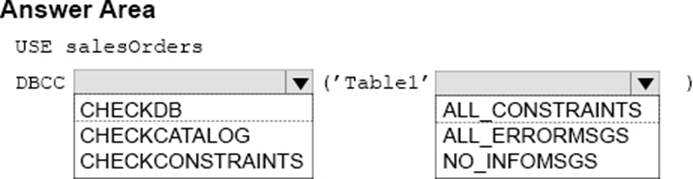

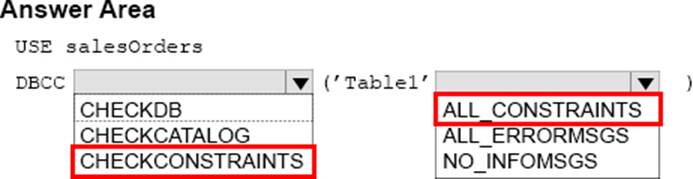
Explanation:
Box 1: CHECKCONSTRAINTS
DBCC CHECKCONSTRAINTS checks the integrity of a specified constraint or all constraints on a specified table in the current database.
Box 2: ALL_CONSTRAINTS
ALL_CONSTRAINTS checks all enabled and disabled constraints on the table if the table name is specified or if all tables are checked;otherwise, checks only the enabled constraint.
Note: Syntax: DBCC CHECKCONSTRAINTS
[
(
table_name | table_id | constraint_name | constraint_id
)
]
[ WITH
[ { ALL_CONSTRAINTS | ALL_ERRORMSGS } ]
[ , ] [NO_INFOMSGS ]
]
References: https://docs.microsoft.com/en-us/sql/t-sql/database-console-commands/dbcc-checkconstraints-transact-sql
DRAG DROP
You are configuring a new Microsoft SQL Server Always On Availability Group. You plan to configure a shared network location at \DATA-CI1SQL.
You need to create an availability group listener named AGL1 on port 1433.
In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.


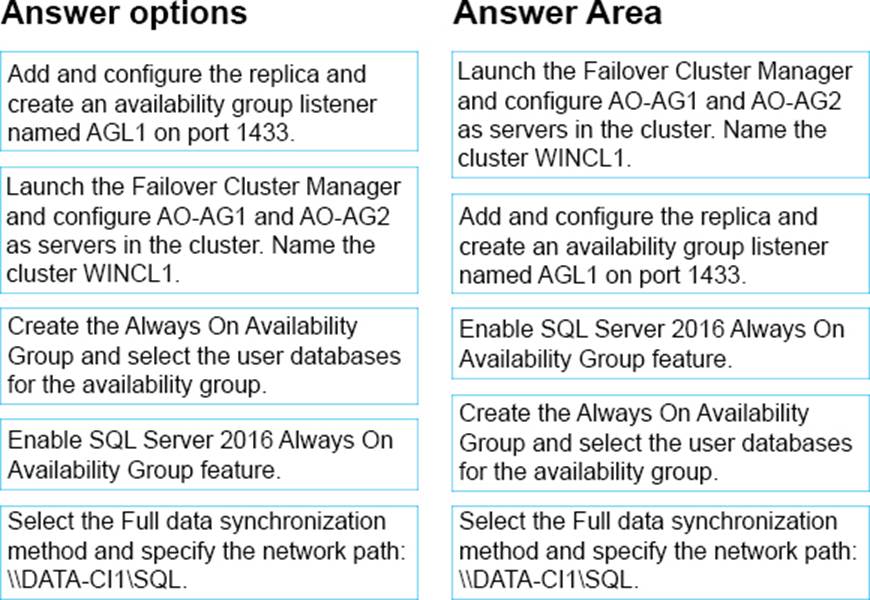
Explanation:
Step 1: Launch the Failover Cluster Manager and..
To support theAlways On availability groups feature, ensure that every computer that is to participate in one or more availability groups meets requirements including:
* Ensure that each computer is a node in a WSFC (Windows Server Failover Clustering).
Step 2: Add andconfigure the replica and…
All the server instances that host availability replicas for an availability group must use the same SQL Server collation.
Step 3: Enable the SQL Server 2016 Always On Availability Group feature.
Enable the Always On availability groups feature on each server instance that will host an availability replica for any availability group. On a given computer, you can enable as many server instances for Always On availability groups as your SQL Server installation supports.
Step 4: Create the Always On Availability Group and..
Using Transact-SQL to create or configure an availability group listener
Step 5: Select the Full data synchronization method and…
References: https://technet.microsoft.com/en-us/library/jj899851(v=sc.12).aspx https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/create-orconfigure-an-availability-group-listener-sql-server
HOTSPOT
You are configuring log shipping for a Microsoft SQL Server database named salesOrders.
You run the following Transact-SQL script:


You need to determine the changes that the script has on the environment.
How does the script affect the environment? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.



Explanation:
Box 1: is
The dedicated backup file share is \localhostBackup
Box 2: does not run
The only thing with a name related to ADATM-SQL11 is the schedule name.
Box 3: 72 hours
4320 minutes equals 72 hours.
Note: @backup_retention_period= ] backup_retention_period
Isthe length of time, in minutes, to retain the log backup file in the backup directory on the primary server. backup_retention_period is int, with no default, and cannot be NULL.
Box 4: 15 minutes.
[ @freq_subday_type = ] freq_subday_type
Specifies the units for freq_subday_interval. freq_subday_typeis int, with a default of 0, and can be one of these values.
Here it is 4, which means minutes.
[ @freq_subday_interval = ] freq_subday_interval
The number of freq_subday_type periods to occur between eachexecution of a job. freq_subday_intervalis int, with a default of 0.
Note: Interval should be longer than 10 seconds. freq_subday_interval is ignored in those cases where freq_subday_type is equal to 1.
Here it is 15.
References:
https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sp-add-schedule-transact-sql
https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sp-add-log-shipping-primary-database-transact-sql
HOTSPOT
You are planning the deployment of two new Always On Failover Cluster Instances (FCIs) of Microsoft SQL Server to a single Windows Server Cluster with three nodes.
The planned configuration for the cluster is shown in the Server Layout exhibit. (Click the Exhibit button.)
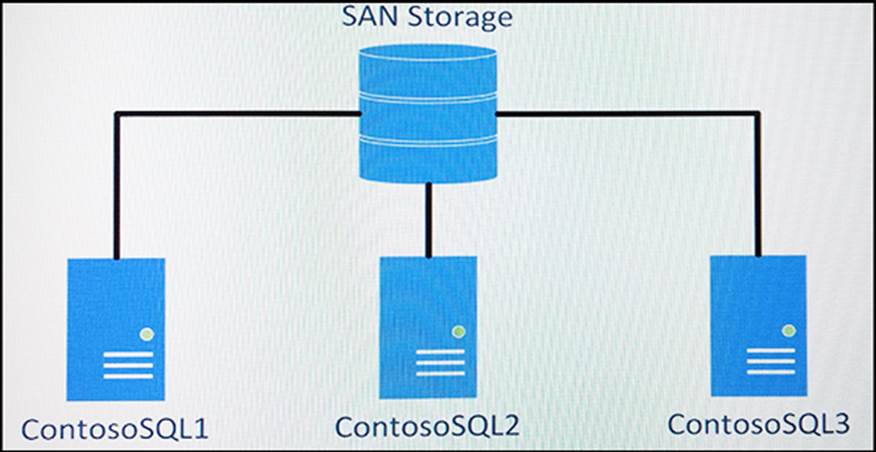

The SAN team has configured storage for the cluster and sent the configuration to you in the email shown in the SAN Team Email exhibit. (Click the Exhibit button.)


Each node of the cluster has identical local storage available as shown in the Local Storage exhibit. (Click the Exhibit button.)
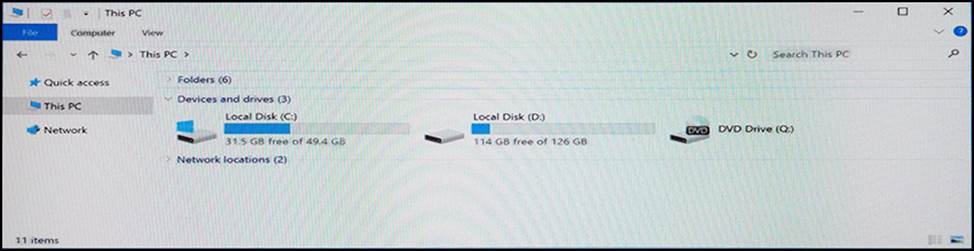

All local storage is on SSD. You need to plan specific configurations for the new cluster. For each of the following statement, select Yes if the statement is true. Otherwise, select No.



Explanation:
Box 1: Yes
tempdb on local storage. FCIs now support placement of tempdb on local non-shared storage, such as a local solid-state-drive, potentially offloading a significant amount of I/O from a shared SAN.
Prior to SQL Server 2012, FCIs required tempdb to be located on a symmetrical shared storage volume that failed over with other system databases.
Box 2: No
The VNN is set on the group level, not on the instance level.
Database client applications can connect directly to a SQL Server instance network name, or they may connect to a virtual network name (VNN) that is bound to an availability group listener. The VNN abstracts the WSFC cluster and availability group topology, logically redirecting connection requests to the appropriate SQL Server instance and database replica.
The logical topology of a representative AlwaysOn solution is illustrated in this diagram:
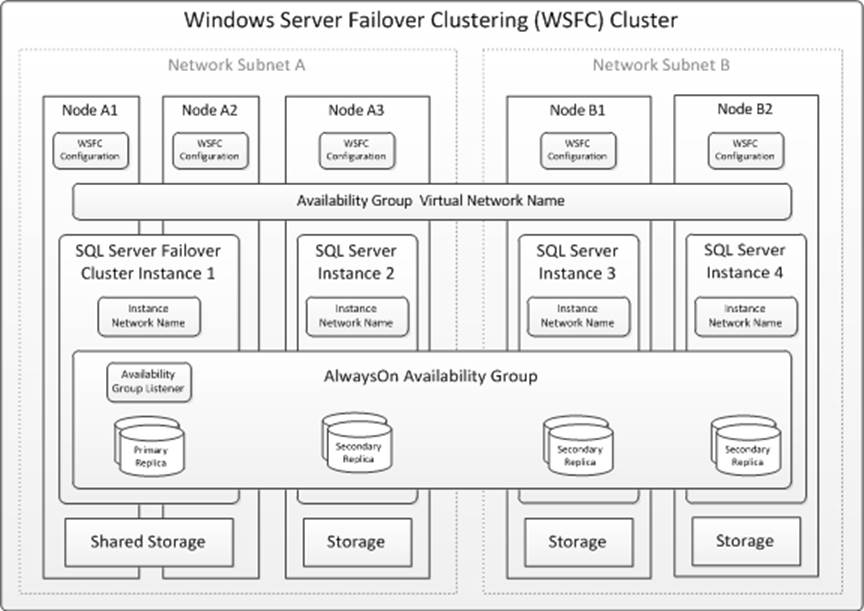

Box 3: No
You don’t configure the SAN from a SQL Server, instead you can use a Microsoft Server server.
References: http://download.microsoft.com/download/d/2/0/d20e1c5f-72ea-4505-9f26-fef9550efd44/microsoft%20sql%20server%20alwayson%20solutions%20guide%20for%20high%20availability%20and%20disaster%20recovery.docx
HOTSPOT
You are planning to deploy log shipping for Microsoft SQL Server and store all backups on a dedicated fileshare.
You need to configure the servers to perform each log shipping step.
Which server instance should you configure to perform each action? To answer, select the appropriate server instances in the dialog box in the answer area.



Explanation:
Note: Before you configure log shipping, you must create a share to make the transaction log backups available to the secondary server.
SQL Server Log shipping allows you to automatically send transaction log backups from a primary database on a primary server instance to one or more secondary databases on separate secondary server instances. The transaction log backups are applied to each of the secondary databases individually. An optional third server instance, known as the monitor server, records the history and status of backup and restore operations and, optionally, raises alerts if these operations fail to occur as scheduled.
Box 1: Primary server instance.
The primary server instance runs the backup job to back up the transaction log on the primary database.
backup job: A SQL Server Agent job that performs the backup operation, logs history to the local server and the monitor server, and deletes old backup files and history information. When log shipping is enabled, the job category "Log Shipping Backup" is created on the primary server instance.
Box 2: Secondary server instance
Each of the three secondary server instances runs its own copy job to copy the primary log-backup file to its own local destination folder.
copy job: A SQL Server Agent job that copies the backup files from the primary server to a configurable destination on the secondary server and logs history on the secondary server and the monitor server. When log shipping is enabled on a database, the job category "Log Shipping Copy" is created on each secondary server in a log shipping configuration.
Box 3: Secondary server instance.
Each secondary server instance runs its own restore job to restore the log backup from the local destination folder onto the local secondary database.
restore job: A SQL Server Agent job that restores the copied backup files to the secondary databases. It logs history on the local server and the monitor server, and deletes old files and old history information. When log shipping is enabled on a database, the job category "Log Shipping Restore" is created on the secondary server instance.
References: https://docs.microsoft.com/en-us/sql/database-engine/log-shipping/about-log-shipping-sql-server
HOTSPOT
You manage a Microsoft SQL Server instance. You have a user named User1. You need to grant the minimum permissions necessary to allow User1 to review audit logs.
For each action, which option should you use? To answer, select the appropriate options in the answer area.



Explanation:
Box 1: securityadmin
To access log files for instances of SQL Server that are online, this requires membership in the securityadmin fixed server role.
Box 2: sys.server_audit_specifications
sys.server_audit_specifications contains information about the server audit specifications in a SQL Server audit on a server instance.
DRAG DROP
You administer a Microsoft SQL Server database named Contoso.
You create a stored procedure named Sales.ReviewInvoice by running the following Transact-SQL statement:


You need to create a Windows-authenticated login named ContosoSearch and ensure that ContosoSearch can run the Sales.ReviewInvoices stored procedure.
Which three Transact-SQL segments should you use to develop the solution? To answer, move the appropriate Transact-SQL segments from the list of Transact-SQL segments to the answer area and arrange them in the correct order.

You have a database that stores information for a shipping company.
You create a table named Customers by running the following Transact-SQL statement. (Line numbers are included for reference only.)


You need to ensure that salespeople can view data only for the customers that are assigned to them.
Which Transact-SQL segment should you insert at line 07?
- A . RETURNS varchar(20)WITH Schemabinding
- B . RETURNS dbo.CustomersORDER BY @salesPerson
- C . RETURNS tableORDER BY @salesPerson
- D . RETURNS tableWITH Schemabinding
D
Explanation:
The return value can either be a scalar (single) value or a table. SELECT 1 just selects a 1 for every row, of course.
What it’s used for in this case is testing whether any rows exist that match the criteria: if a row exists that matches the WHERE clause, then it returns 1, otherwise it returns nothing. Specify the WITH SCHEMABINDING clause when you are creating the function. This ensures that the objects referenced in the function definition cannot be modified unless the function is also modified.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-function-transact-sql
You manage a Microsoft SQL Server environment.
You plan to encrypt data when you create backups.
You need to configure the encryption options for backups.
What should you configure?
- A . a certificate
- B . an MD5 hash
- C . a DES key
- D . an AES 256-bit key
D
Explanation:
To encrypt during backup, you must specify an encryption algorithm, and an encryptor to secure the encryption key. The following are the supported encryption options: Encryption Algorithm: The supported encryption algorithms are: AES 128, AES 192, AES 256, and Triple DES Encryptor: A certificate or asymmetric Key
References: https://docs.microsoft.com/en-us/sql/relational-databases/backup-restore/backupencryption
You have a database named DB1 that stores more than 700 gigabyte (GB) of data and serves millions of requests per hour.
Queries on DB1 are taking longer than normal to complete.
You run the following Transact-SQL statement:
SELECT * FROM sys.database_query_store_options
You determine that the Query Store is in Read-Only mode.
You need to maximize the time that the Query Store is in Read-Write mode.
Which Transact-SQL statement should you run?
- A . ALTER DATABASE DB1SET QUERY_STORE (QUERY_CAPTURE_MODE = ALL)
- B . ALTER DATABASE DB1SET QUERY_STORE (MAX_STORAGE_SIZE_MB = 50)
- C . ALTER DATABASE DB1SET QUERY_STORE (CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 14));
- D . ALTER DATABASE DB1SET QUERY_STORE (QUERY_CAPTURE_MODE = NONE)
C
Explanation:
Stale Query Threshold (Days): Time-based cleanup policy that controls the retention period of persisted runtime statistics and inactive queries. By default, Query Store is configured to keep the data for 30 days which may be unnecessarily long for your scenario. Avoid keeping historical data that you do not plan to use. This will reduce changes to read-only status. The size of Query Store data as well as the time to detect and mitigate the issue will be more predictable. Use Management Studio or the following script to configure time-based cleanup policy:
ALTER DATABASE [QueryStoreDB] SET QUERY_STORE (CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 14));
References: https://docs.microsoft.com/en-us/sql/relational-databases/performance/best-practicewith-the-query-store
HOTSPOT
You deploy a Microsoft SQL Server instance to support a global sales application. The instance includes the following tables: TableA and TableB.
TableA is a partitioned table that uses an incrementing integer number for partitioning. The table has millions of rows in each partition. Most changes to the data in TableA affect recently added
data. The UPDATE STATISTICS for TableA takes longer to complete than the allotted maintenance window.
Thousands of operations are performed against TableB each minute. You observe a large number of Auto Update Statistics events for TableB.
You need to address the performance issues with each table.
In the table below, identify the action that will resolve the issues for each table. NOTE: Make only one selection in each column.



Explanation:
Table A: Auto_update statistics off
Table A does not change much. There is no need to update the statistics on this table.
Table B: SET AUTO_UPDATE_STATISTICS_ASYNC ON
You can set the database to update statistics asynchronously:
ALTER DATABASE YourDBName
SET AUTO_UPDATE_STATISTICS_ASYNC ON
If you enable this option then the Query Optimizer will run the query first and update the outdated statistics afterwards. When you set this option to OFF, the Query Optimizer will update the outdated statistics before compiling the query. This option can be useful in OLTP environments
References: https://www.mssqltips.com/sqlservertip/2766/sql-server-auto-update-and-auto-create-statistics-options/
DRAG DROP
You administer a database that is used for reporting purposes. The database has a large fact table that contains three hundred million rows. The table includes a clustered columnstore index and a nonclustered index on the Product ID column. New rows are inserted into the table every day.
Performance of queries that filter the Product ID column have degraded significantly.
You need to improve the performance of the queries.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

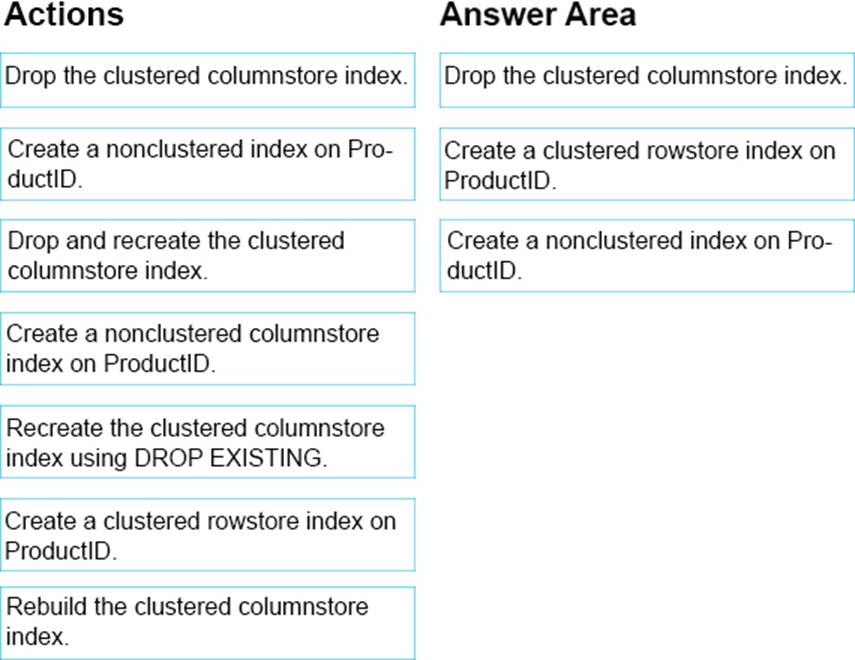
Explanation:
Step 1: Drop the clustered columnstore index
Step 2: Create a clustered rowstore index on ProductID.
Rowstore indexes perform best on queries that seek into the data, searching for a particular value, or for queries on a small range of values. Use rowstore indexes with transactional workloads since they tend to require mostly table seeks instead of table scans.
Step 3: Create a nonclustered index on ProductID
HOTSPOT
You are the database administrator of a Microsoft SQL Server instance. Developers are writing stored procedures to send emails using sp_send_dbmail. Database Mail is enabled.
You need to configure each account’s profile security and meet the following requirements:
– Account SMTP1_Account must only be usable by logins that have been given explicit permissions to use the SMTP1_profile.
– Account SMTP2_Account must only be usable by logins who are a member of the [DatabaseMailUserRole] role in msdb.
In the table below. identify the profile type that must be used for each account.
NOTE: Make only one selection in each column.



Explanation:
SMTP1_Account1: Private Profile
When no profile_name is specified, sp_send_dbmail uses the default private profile for the current user. If the user does not have a default private profile, sp_send_dbmail uses the default public profile for the msdb database.
SMTP1_Account2: Default Profile
Execute permissions forsp_send_dbmail default to all members of the DatabaseMailUser database role in the msdb database.
References: https://docs.microsoft.com/en-us/sql/relational-databases/system-stored-procedures/sp-send-dbmail-transact-sql
HOTSPOT
You have a Microsoft SQL Server instance that hosts a database named DB1 that contains 800 gigabyte (GB) of data. The database is used 24 hours each day. You implement indexes and set the value of the Auto Update Statistics option set to True.
Users report that queries take a long time to complete.
You need to identify statistics that have not been updated for a week for tables where more than 1,000 rows changed.
How should you complete the Transact-SQL statement? To answer, configure the appropriate Transact-SQL segments in the answer area.
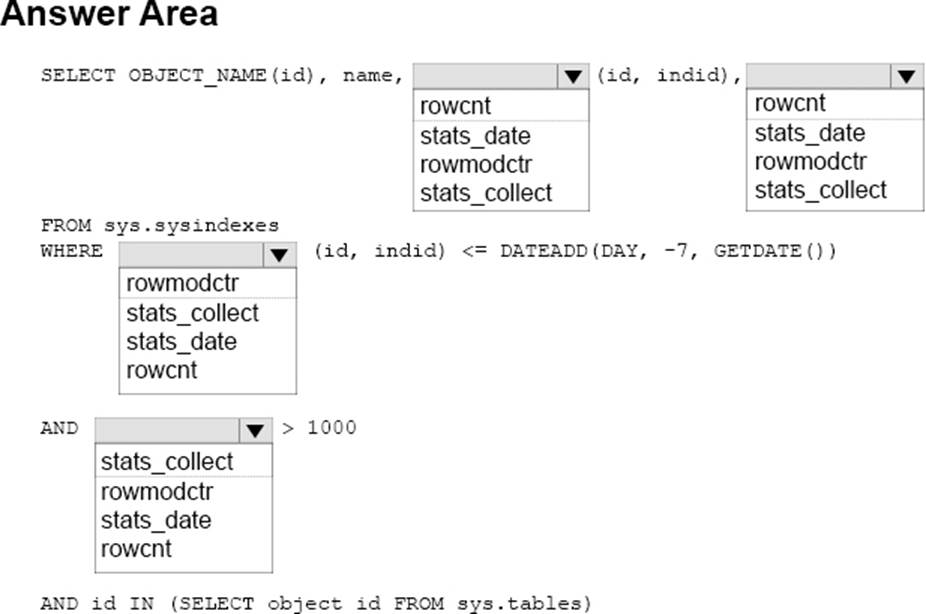

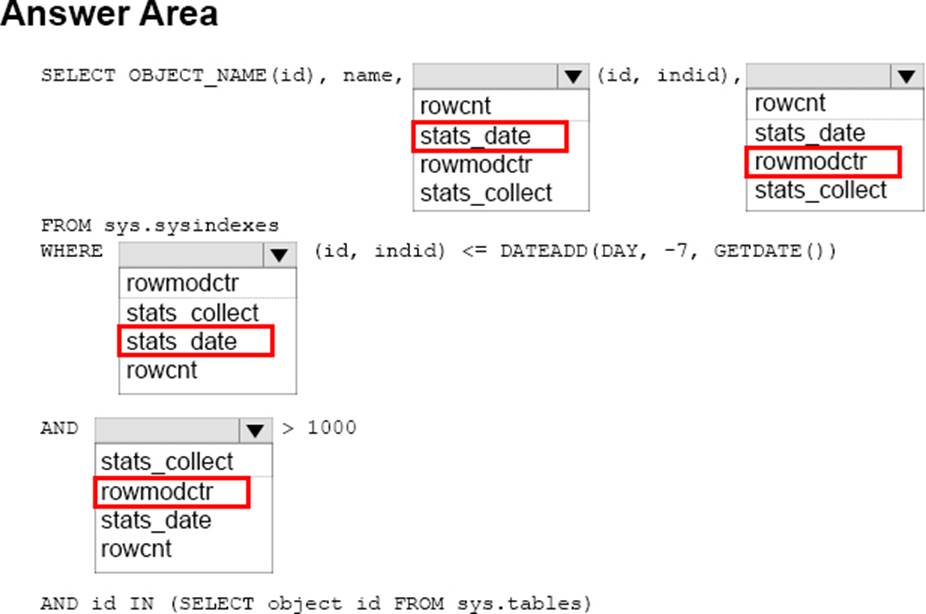
Explanation:
Box 1: stats_date
See example below.
Box 2: rowmodctr
See examplebelow.
Box 3: stats_date
You need to identify statistics that have not been updated for a week.
Box 4: rowmodctr
You need to identify that more than 1,000 rows changed.
Rowmodctr counts the total number of inserted, deleted, or updated rows since the last time statistics were updated for the table.
Example: We will query every statistics object which was not updated in the last day and has rows modified since the last update. We will use the rowmodctr field of sys.sysindexes because it shows how many rows were inserted, updated or deleted since the last update occurred. Please note that it is not always 100% accurate in SQL Server 2005 and later, but it can be used to check if any rows were modified.
–Get the list of outdated statistics
SELECTOBJECT_NAME(id),name,STATS_DATE(id, indid),rowmodctr
FROM sys.sysindexes
WHERE STATS_DATE (id, indid)<=DATEADD(DAY,-1,GETDATE())
AND rowmodctr>0
AND id IN (SELECT object_id FROM sys.tables)
GO
After collecting this information, we can decide which statistics require an update.
References: https://docs.microsoft.com/en-us/sql/relational-databases/system-compatibility-views/sys-sysindexes-transact-sql
https://www.mssqltips.com/sqlservertip/2628/how-to-find-outdated-statistics-in-sql-server-2008/
DRAG DROP
You are the database administrator for a Microsoft SQL Server instance. You develop an Extended Events package to look for events related to application performance.
You need to change the event session to include SQL Server errors that are greater than error severity 15.
Which five Transact-SQL segments should you use to develop the solution? To answer, move the appropriate Transact-SQL segments from the list of Transact-SQL segments to the answer area and arrange them in the correct order.
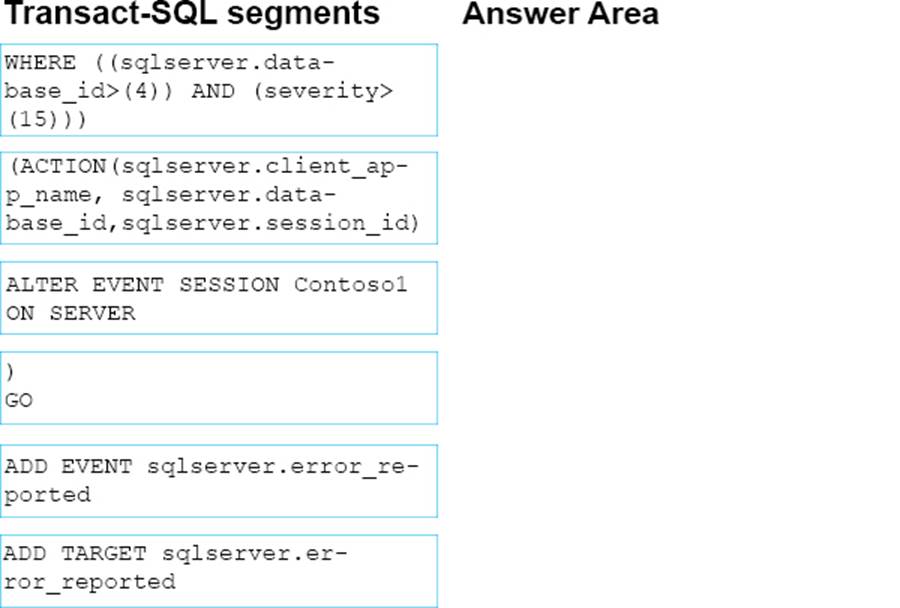


Explanation:
Step 1: ALTER EVENT SESSION Contoso1 ON SERVER
Step 2: ADD EVENT …
Step 3: (ACTION …
Step 4: WHERE…
Step 5: ) GO
Example: To start an Extended Events sessions in order to trap SQL Server errors with severity greater than 10,just run the following script:
CREATE EVENT SESSION [error_trap] ON SERVER
ADD EVENT sqlserver.error_reported
(
ACTION (package0.collect_system_time,package0.last_error,sqlserver.client_app_name,sqlserver.client_hostname,sqlserver.database_id,sqlserver.database_name,sqlserver.nt_username, sqlserver.plan_handle,sqlserver.query_hash,sqlserver.session_id,sqlserver.sql_text,sqlserver.tsql_frame,sqlserver.tsql_stack,sqlserver.username)
WHERE ([severity]>10)
)
ADD TARGET package0.event_file
(
SET filename=N’D:Program FilesMicrosoft SQL ServerMSSQL11.MSSQLSERVERMSSQLXEventserror_trap.xel’
)
WITH
(
STARTUP_STATE=OFF
)
GO
References: http://sqlblog.com/blogs/davide_mauri/archive/2013/03/17/trapping-sql-server-errors-with-extended-events.aspx
HOTSPOT
You manage a Microsoft SQL Server environment. A server fails and writes the following event to the application event log: MSG_AUDIT_FORCED_SHUTDOWN
You configure the SQL Server startup parameters as shown in the following graphic:
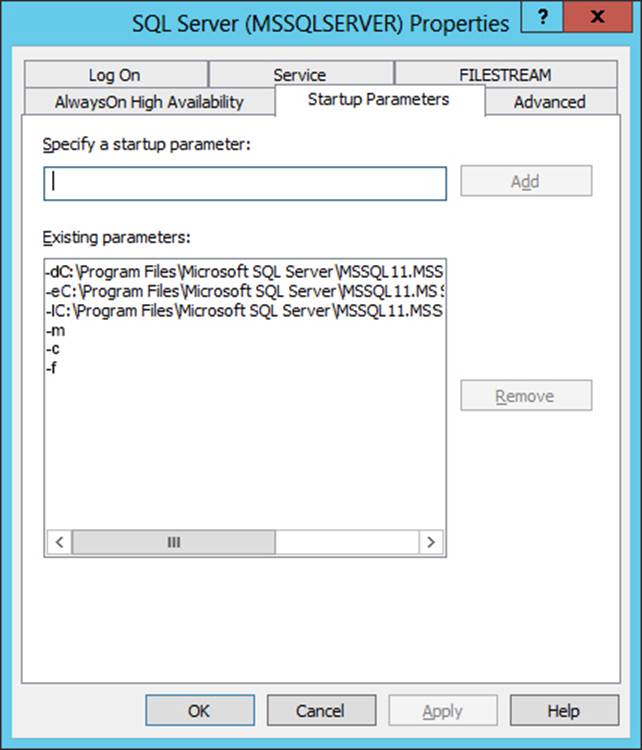

Use the drop-down menus to select the answer choice that answers each question. NOTE: Each correct selection is worth one point.

Explanation:
Box 1: single-user
The startup option -m starts an instance of SQL Server in single-user mode.
Box 2: sysadmin
Starting SQL Server in single-user mode enables anymember of the computer’s local Administrators group to connect to the instance of SQL Server as a member of the sysadmin fixed server role.
References: https://docs.microsoft.com/en-us/sql/database-engine/configure-windows/database-engine-service-startup-options