

DRAG DROP
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
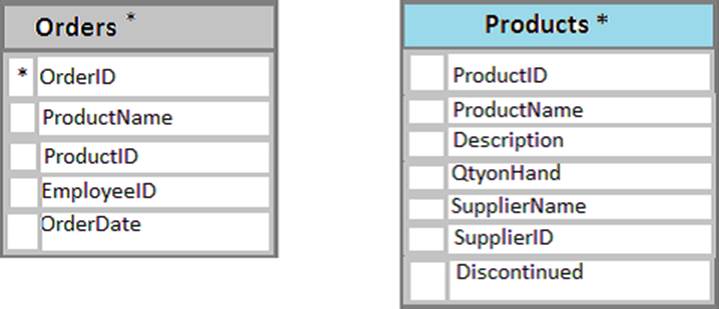
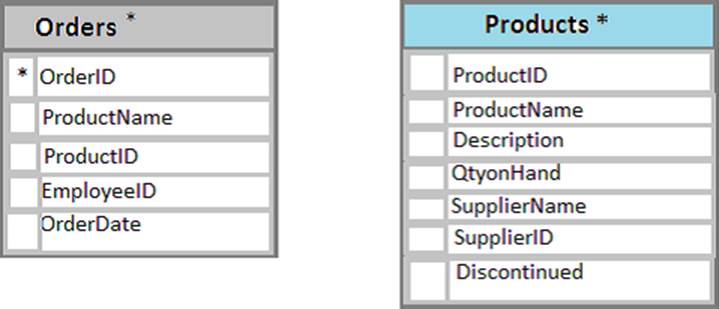
You have a database named Sales that contains the following database tables: Customer, Order, and Products. The Products table and the Order table are shown in the following diagram.
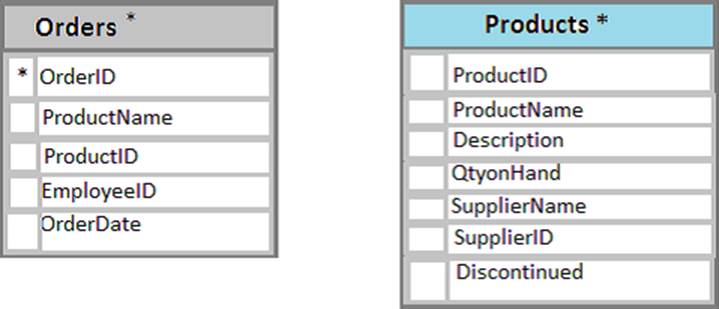

The customer table includes a column that stores the data for the last order that the customer placed.
You plan to create a table named Leads. The Leads table is expected to contain approximately 20,000 records. Storage requirements for the Leads table must be minimized.
Changes to the price of any product must be less a 25 percent increase from the current price. The shipping department must be notified about order and shipping details when an order is entered into the database.
You need to implement the appropriate table objects.
Which object should you use for each table? To answer, drag the appropriate objects to the correct tables. Each object may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.



Explanation:
The Products table needs a primary key constraint on the ProductID field. The Orders table needs a foreign key constraint on the productID field, with a reference to the ProductID field in the Products table.
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database named Sales that contains the following database tables: Customer, Order, and Products.
The Products table and the Order table are shown in the following diagram.
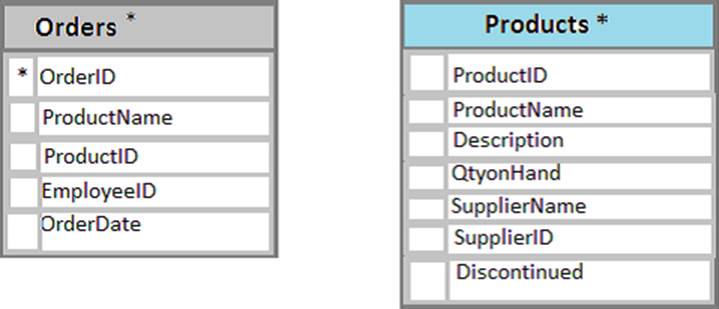
The customer table includes a column that stores the data for the last order that the customer placed.
You plan to create a table named Leads. The Leads table is expected to contain approximately 20,000 records. Storage requirements for the Leads table must be minimized.
You need to implement a stored procedure that deletes a discontinued product from the Products table. You identify the following requirements:
If an open order includes a discontinued product, the records for the product must not be deleted.
The stored procedure must return a custom error message if a product record cannot be deleted. The message must identify the OrderID for the open order.
What should you do? To answer, select the appropriate Transact-SQL segments in the answer area.
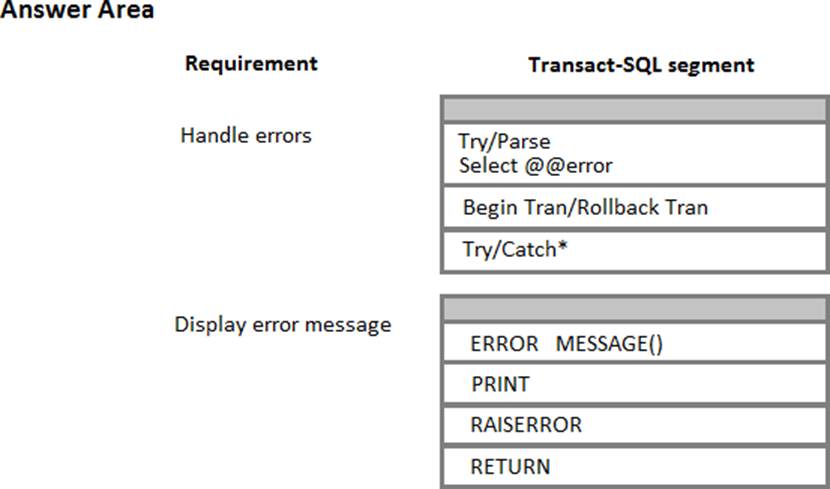

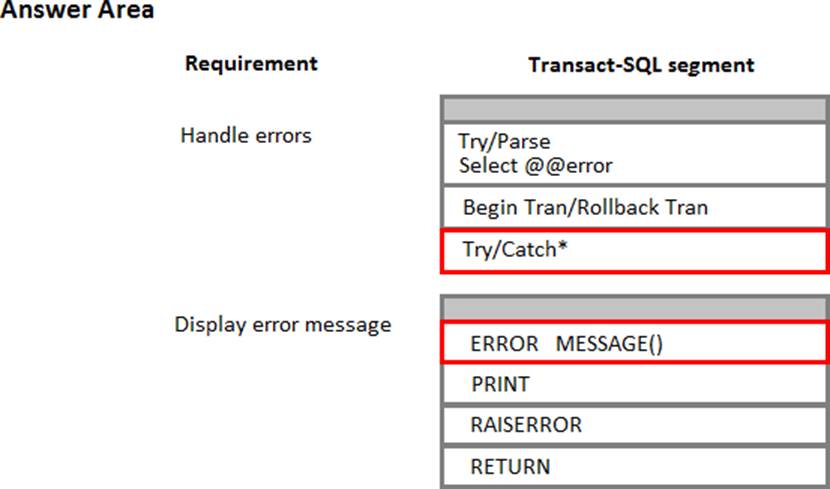
Explanation:
Using TRY…CATCH in Transact-SQL
Errors in Transact-SQL code can be processed by using a TRY…CATCH construct.
TRY…CATCH can use the following error function to capture error information: ERROR_MESSAGE () returns the complete text of the error message. The text includes the values supplied for any substitutable parameters such as lengths, object names, or times.
References: https://technet.microsoft.com/en-us/library/ms179296(v=sql.105).aspx
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database named Sales that contains the following database tables: Customer, Order, and Products.
The Products table and the Order table are shown in the following diagram.
The customer table includes a column that stores the data for the last order that the customer placed.
You plan to create a table named Leads. The Leads table is expected to contain approximately 20,000 records. Storage requirements for the Leads table must be minimized.
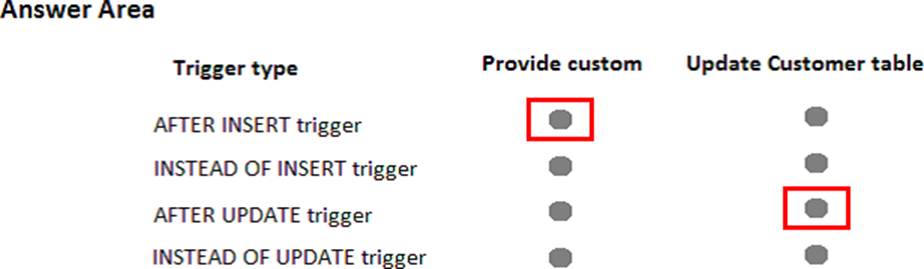
You need to create triggers that meet the following requirements: Optimize the performance and data integrity of the tables. Provide a custom error if a user attempts to create an order for a customer that does not exist. In the Customers table, update the value for the last order placed. Complete all actions as part of the original transaction.
In the table below, identify the trigger types that meet the requirements. NOTE: Make only selection in each column. Each correct selection is worth one point.

Explanation:
INSTEAD OF INSERT triggers can be defined on a view or table to replace the standard action of the INSERT statement. AFTER specifies that the DML trigger is fired only when all operations specified in the triggering SQL statement have executed successfully.
References: https://technet.microsoft.com/en-us/library/ms175089(v=sql.105).aspx
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database named Sales that contains the following database tables: Customer, Order, and Products.
The Products table and the Order table are shown in the following diagram.
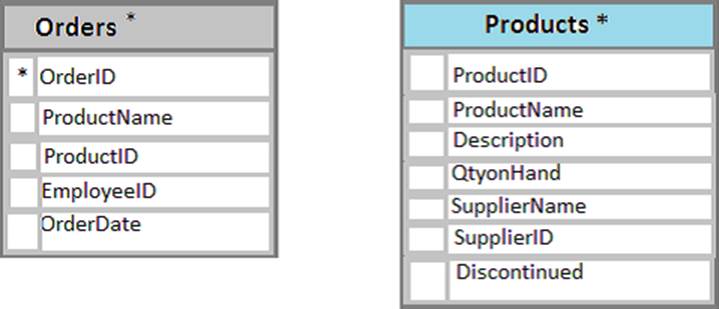
The customer table includes a column that stores the data for the last order that the customer placed.
You plan to create a table named Leads. The Leads table is expected to contain approximately 20,000 records. Storage requirements for the Leads table must be minimized.
The Leads table must include the columns described in the following table.


The data types chosen must consume the least amount of storage possible. You need to select the appropriate data types for the Leads table. In the table below, identify the data type that must be used for each table column. NOTE: Make only one selection in each column.
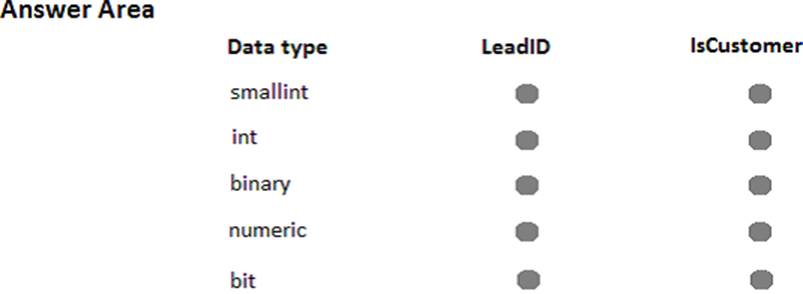


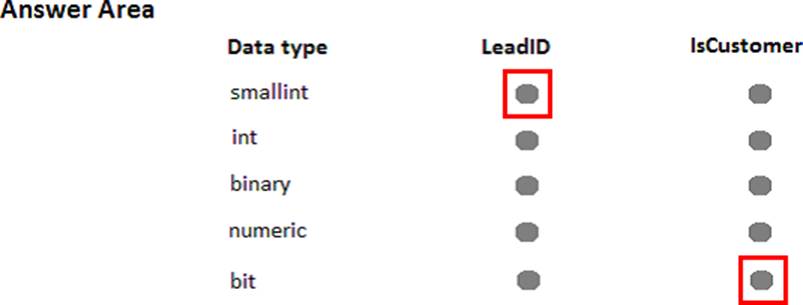
Explanation:
Bit is aTransact-SQL integer data type that can take a value of 1, 0, or NULL. Smallint is a Transact-SQL integer data type that can take a value in the range from -32,768 to 32,767. int, bigint, smallint, and tinyint (Transact-SQL) Exact-number data types that use integer data.
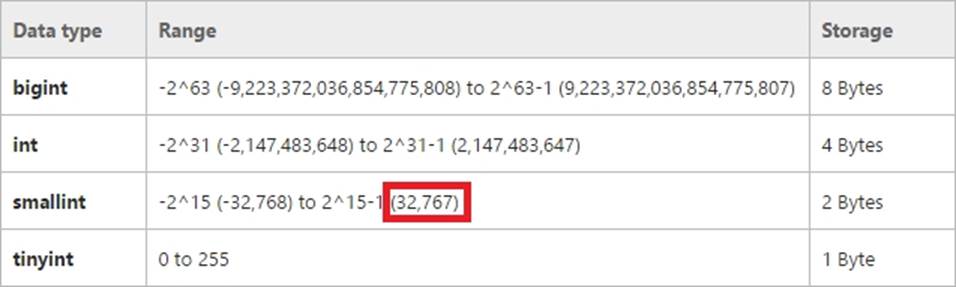

References: https://msdn.microsoft.com/en-us/library/ms187745.aspx https://msdn.microsoft.com/en-us/library/ms177603.aspx
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database named Sales that contains the following database tables: Customer, Order, and Products.
The Products table and the Order table are shown in the following diagram.
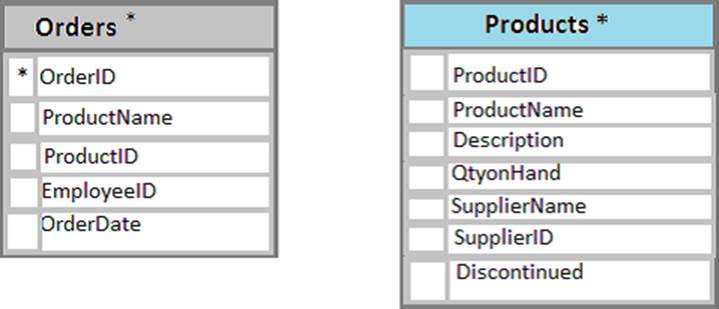
The customer table includes a column that stores the data for the last order that the customer placed.
You plan to create a table named Leads. The Leads table is expected to contain approximately 20,000 records. Storage requirements for the Leads table must be minimized.
You need to modify the database design to meet the following requirements:
– Rows in the Orders table must always have a valid value for the ProductID column.
– Rows in the Products table must not be deleted if they arepart of any rows in the Orders table.
– All rows in both tables must be unique.
In the table below, identify the constraint that must be configured for each table.
NOTE: Make only one selection in each column.


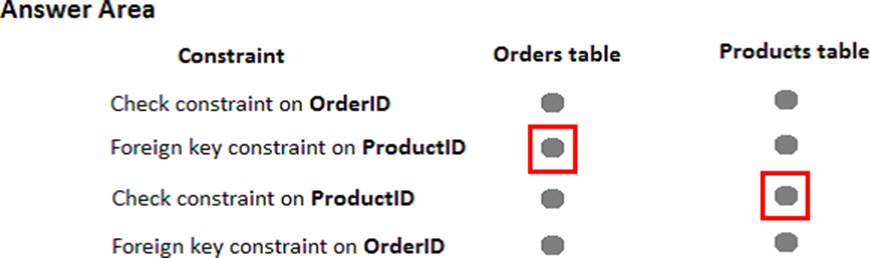
Explanation:
A FOREIGN KEY in one table points to a PRIMARY KEY in another table. Here the foreign key constraint is put on the ProductID in the Orders, and points to the ProductID of the Products table. With a check constraint on the ProductID we can ensure that the Products table contains only unique rows.
References: http://www.w3schools.com/sql/sql_foreignkey.asp
DRAG DROP
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in the series.
You have a database named Sales that contains the following database tables. Customer, Order, and Products.
The Products table and the order table shown in the following diagram.
The Customer table includes a column that stores the date for the last order that the customer placed. You plan to create a table named Leads. The Leads table is expected to contain approximately 20,000 records. Storage requirements for the Leads table must be minimized.
You need to begin to modify the table design to adhere to third normal form.
Which column should you remove for each table? To answer? drag the appropriate column names to the correct locations. Each column name may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
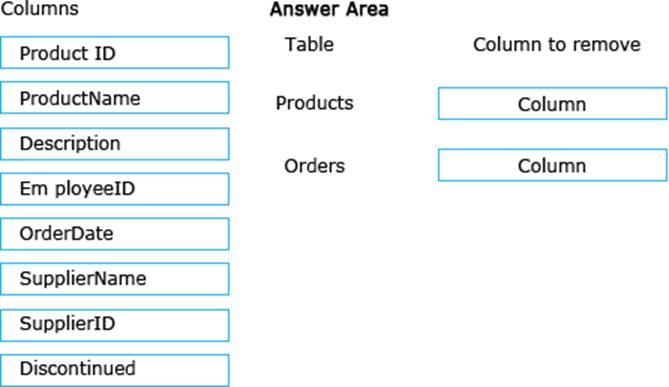


Explanation:
In the Products table the SupplierName is dependant on the SupplierID, not on the ProductID. In the Orders table the ProductName is dependant on the ProductID, not on the OrderID.
Note:
A table is in third normal form when the following conditions are met:
– It is in second normal form.
– All nonprimary fields are dependent on the primary key.
Second normal form states that it should meet all the rules for First 1Normnal Form and there must be no partial dependences of any of the columns on the primary key.
First normal form (1NF) sets the very basic rules for an organized database:
– Define the data items required, because they become the columns in a table. Place related data items in a table.
– Ensure that there are no repeating groups ofdata.
– Ensure that there is a primary key.
References: https://www.tutorialspoint.com/sql/third-normal-form.htm
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:


You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to enable referential integrity for the ProductReview table.
How should you complete the relevant Transact-SQL statement? To answer? select the appropriate Transact-SQL segments in the answer area.
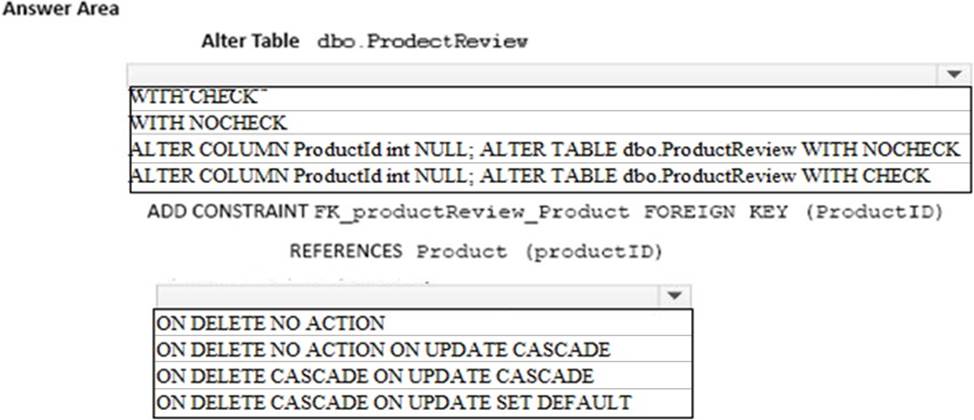

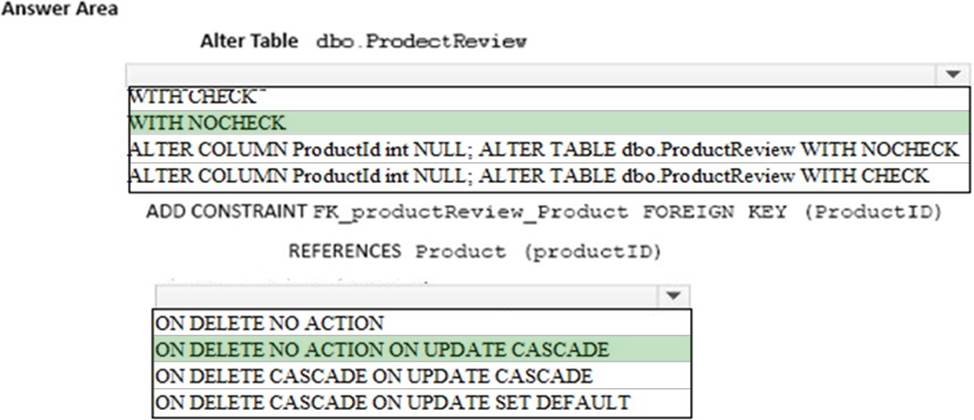
Explanation:
Box 1: WITH NOCHECK
We should use WITH NOCHECK as existing records in the ProductReview table must not be validated with the Product table.
Box 2: ON DELETE NO ACTION ON DELETE NO CASCADE
Deletes should not be allowed, so we use ON DELETE NO ACTION.
Updates should be allowed, so we use ON DELETE NO CASCADE
NO ACTION: the Database Engine raises an error, and the update action on the row in the parent table is rolled back.
CASCADE: corresponding rows are updated in the referencing table when that row is updated in the parent table.
Note: ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Specifies what action happens to rows in the table that is altered, if those rows have a referential relationship and the referenced row is deleted from the parent table. The default is NO ACTION.
ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Specifies what action happens to rows in the table altered when those rows have a referential relationship and the referenced row is updated in the parent table. The default is NO ACTION.
Note: You must modify the ProductReview Table to meet the following requirements:
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:
You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to enable referential integrity for the ProductReview table.
How should you complete the relevant Transact-SQL statement? To answer? select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: WITH NOCHECK
We should use WITH NOCHECK as existing records in the ProductReview table must not be validated with the Product table.
Box 2: ON DELETE NO ACTION ON DELETE NO CASCADE
Deletes should not be allowed, so we use ON DELETE NO ACTION.
Updates should be allowed, so we use ON DELETE NO CASCADE
NO ACTION: the Database Engine raises an error, and the update action on the row in the parent table is rolled back.
CASCADE: corresponding rows are updated in the referencing table when that row is updated in the parent table.
Note: ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Specifies what action happens to rows in the table that is altered, if those rows have a referential relationship and the referenced row is deleted from the parent table. The default is NO ACTION.
ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Specifies what action happens to rows in the table altered when those rows have a referential relationship and the referenced row is updated in the parent table. The default is NO ACTION.
Note: You must modify the ProductReview Table to meet the following requirements:
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:
You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to enable referential integrity for the ProductReview table.
How should you complete the relevant Transact-SQL statement? To answer? select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: WITH NOCHECK
We should use WITH NOCHECK as existing records in the ProductReview table must not be validated with the Product table.
Box 2: ON DELETE NO ACTION ON DELETE NO CASCADE
Deletes should not be allowed, so we use ON DELETE NO ACTION.
Updates should be allowed, so we use ON DELETE NO CASCADE
NO ACTION: the Database Engine raises an error, and the update action on the row in the parent table is rolled back.
CASCADE: corresponding rows are updated in the referencing table when that row is updated in the parent table.
Note: ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Specifies what action happens to rows in the table that is altered, if those rows have a referential relationship and the referenced row is deleted from the parent table. The default is NO ACTION.
ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Specifies what action happens to rows in the table altered when those rows have a referential relationship and the referenced row is updated in the parent table. The default is NO ACTION.
Note: You must modify the ProductReview Table to meet the following requirements:
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:
You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to enable referential integrity for the ProductReview table.
How should you complete the relevant Transact-SQL statement? To answer? select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: WITH NOCHECK
We should use WITH NOCHECK as existing records in the ProductReview table must not be validated with the Product table.
Box 2: ON DELETE NO ACTION ON DELETE NO CASCADE
Deletes should not be allowed, so we use ON DELETE NO ACTION.
Updates should be allowed, so we use ON DELETE NO CASCADE
NO ACTION: the Database Engine raises an error, and the update action on the row in the parent table is rolled back.
CASCADE: corresponding rows are updated in the referencing table when that row is updated in the parent table.
Note: ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Specifies what action happens to rows in the table that is altered, if those rows have a referential relationship and the referenced row is deleted from the parent table. The default is NO ACTION.
ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Specifies what action happens to rows in the table altered when those rows have a referential relationship and the referenced row is updated in the parent table. The default is NO ACTION.
Note: You must modify the ProductReview Table to meet the following requirements:
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:
You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to enable referential integrity for the ProductReview table.
How should you complete the relevant Transact-SQL statement? To answer? select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: WITH NOCHECK
We should use WITH NOCHECK as existing records in the ProductReview table must not be validated with the Product table.
Box 2: ON DELETE NO ACTION ON DELETE NO CASCADE
Deletes should not be allowed, so we use ON DELETE NO ACTION.
Updates should be allowed, so we use ON DELETE NO CASCADE
NO ACTION: the Database Engine raises an error, and the update action on the row in the parent table is rolled back.
CASCADE: corresponding rows are updated in the referencing table when that row is updated in the parent table.
Note: ON DELETE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Specifies what action happens to rows in the table that is altered, if those rows have a referential relationship and the referenced row is deleted from the parent table. The default is NO ACTION.
ON UPDATE { NO ACTION | CASCADE | SET NULL | SET DEFAULT }
Specifies what action happens to rows in the table altered when those rows have a referential relationship and the referenced row is updated in the parent table. The default is NO ACTION.
Note: You must modify the ProductReview Table to meet the following requirements:
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:

You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to create an object that allows finance users to be able to retrieve the required data. The object must not have a negative performance impact.
How should you complete the Transact-SQL statements? To answer, select the appropriate Transact-SQL segments in the answer area.
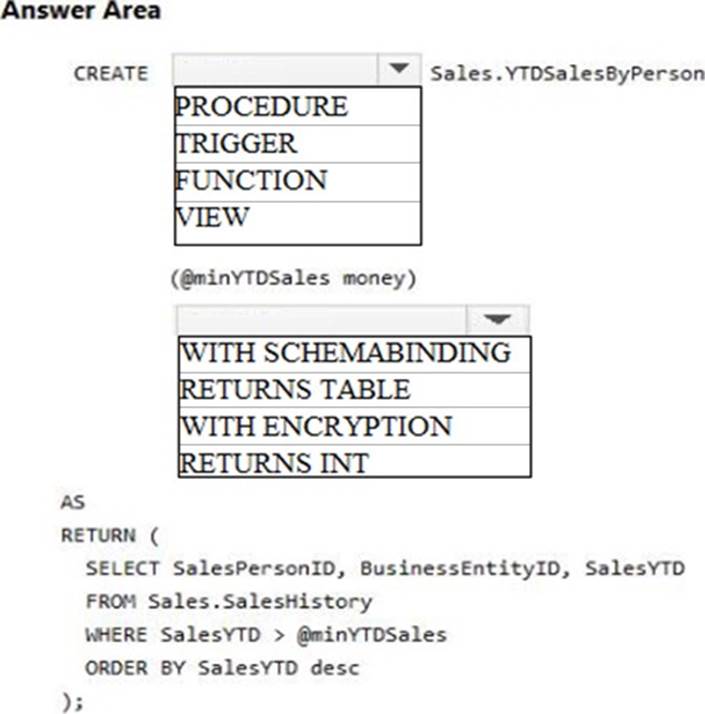

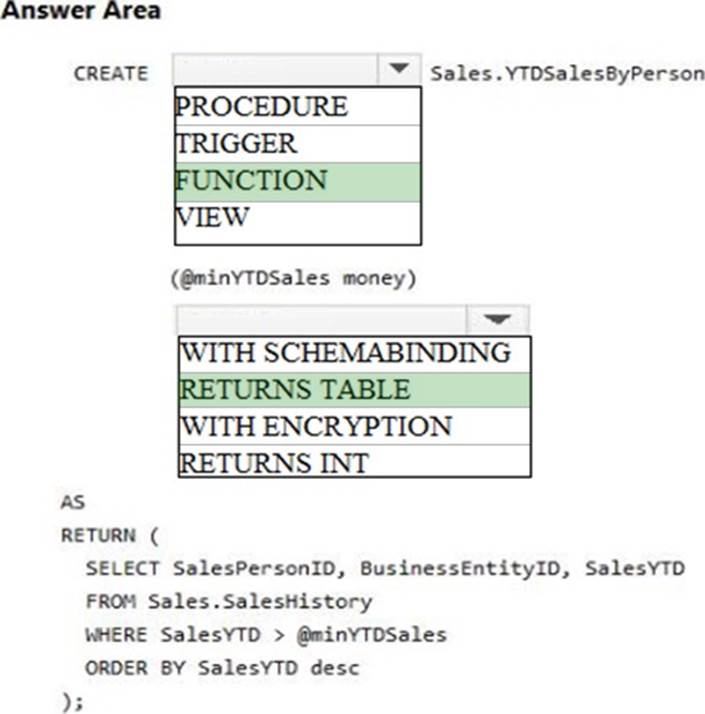
Explanation:
A user defined function can return a table, which can be produces by a SELECT statement.
From question : Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
Incorrect:
Not VIEW: The RETURN clause is not used when you create a view.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-function-transact-sql?view=sqlserver-2017
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:
You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to create an object that allows finance users to be able to retrieve the required data. The object must not have a negative performance impact.
How should you complete the Transact-SQL statements? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
A user defined function can return a table, which can be produces by a SELECT statement.
From question : Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
Incorrect:
Not VIEW: The RETURN clause is not used when you create a view.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-function-transact-sql?view=sqlserver-2017
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:
You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to create an object that allows finance users to be able to retrieve the required data. The object must not have a negative performance impact.
How should you complete the Transact-SQL statements? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
A user defined function can return a table, which can be produces by a SELECT statement.
From question : Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
Incorrect:
Not VIEW: The RETURN clause is not used when you create a view.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-function-transact-sql?view=sqlserver-2017
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:
You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to create an object that allows finance users to be able to retrieve the required data. The object must not have a negative performance impact.
How should you complete the Transact-SQL statements? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
A user defined function can return a table, which can be produces by a SELECT statement.
From question : Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
Incorrect:
Not VIEW: The RETURN clause is not used when you create a view.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-function-transact-sql?view=sqlserver-2017
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:
You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to create an object that allows finance users to be able to retrieve the required data. The object must not have a negative performance impact.
How should you complete the Transact-SQL statements? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
A user defined function can return a table, which can be produces by a SELECT statement.
From question : Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
Incorrect:
Not VIEW: The RETURN clause is not used when you create a view.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-function-transact-sql?view=sqlserver-2017
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:
You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to create an object that allows finance users to be able to retrieve the required data. The object must not have a negative performance impact.
How should you complete the Transact-SQL statements? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
A user defined function can return a table, which can be produces by a SELECT statement.
From question : Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
Incorrect:
Not VIEW: The RETURN clause is not used when you create a view.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-function-transact-sql?view=sqlserver-2017
HOTSPOT
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have a database that contains the following tables: BlogCategory, BlogEntry, ProductReview, Product, and SalesPerson.
The tables were created using the following Transact SQL statements:
You must modify the ProductReview Table to meet the following requirements:
– The table must reference the ProductID column in the Product table
– Existing records in the ProductReview table must not be validated with the Product table.
– Deleting records in the Product table must not be allowed if records are referenced by the ProductReview table.
– Changes to records in the Product table must propagate to the ProductReview table.
You also have the following database tables: Order, ProductTypes, and SalesHistory, The transact-SQL statements for these tables are not available.
You must modify the Orders table to meet the following requirements:
– Create new rows in the table without granting INSERT permissions to the table.
– Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirements:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to create an object that allows finance users to be able to retrieve the required data. The object must not have a negative performance impact.
How should you complete the Transact-SQL statements? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
A user defined function can return a table, which can be produces by a SELECT statement.
From question : Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
Incorrect:
Not VIEW: The RETURN clause is not used when you create a view.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-function-transact-sql?view=sqlserver-2017
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to modify the design of the Orders table.
What should you create?
- A . a stored procedure with the RETURN statement
- B . a FOR UPDATE trigger
- C . an AFTER UPDATE trigger
- D . a user defined function
D
Explanation:
Requirements: You must modify the Orders table to meet the following requirements:
Create new rows in the table without granting INSERT permissions to the table.
Notify the sales person who places an order whether or not the order was completed.
References: https://msdn.microsoft.com/en-us/library/ms186755.aspx
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to modify the design of the Orders table.
What should you create?
- A . a stored procedure with the RETURN statement
- B . a FOR UPDATE trigger
- C . an AFTER UPDATE trigger
- D . a user defined function
D
Explanation:
Requirements: You must modify the Orders table to meet the following requirements:
Create new rows in the table without granting INSERT permissions to the table.
Notify the sales person who places an order whether or not the order was completed.
References: https://msdn.microsoft.com/en-us/library/ms186755.aspx
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to modify the design of the Orders table.
What should you create?
- A . a stored procedure with the RETURN statement
- B . a FOR UPDATE trigger
- C . an AFTER UPDATE trigger
- D . a user defined function
D
Explanation:
Requirements: You must modify the Orders table to meet the following requirements:
Create new rows in the table without granting INSERT permissions to the table.
Notify the sales person who places an order whether or not the order was completed.
References: https://msdn.microsoft.com/en-us/library/ms186755.aspx
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to modify the design of the Orders table.
What should you create?
- A . a stored procedure with the RETURN statement
- B . a FOR UPDATE trigger
- C . an AFTER UPDATE trigger
- D . a user defined function
D
Explanation:
Requirements: You must modify the Orders table to meet the following requirements:
Create new rows in the table without granting INSERT permissions to the table.
Notify the sales person who places an order whether or not the order was completed.
References: https://msdn.microsoft.com/en-us/library/ms186755.aspx
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to modify the design of the Orders table.
What should you create?
- A . a stored procedure with the RETURN statement
- B . a FOR UPDATE trigger
- C . an AFTER UPDATE trigger
- D . a user defined function
D
Explanation:
Requirements: You must modify the Orders table to meet the following requirements:
Create new rows in the table without granting INSERT permissions to the table.
Notify the sales person who places an order whether or not the order was completed.
References: https://msdn.microsoft.com/en-us/library/ms186755.aspx
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to modify the design of the Orders table.
What should you create?
- A . a stored procedure with the RETURN statement
- B . a FOR UPDATE trigger
- C . an AFTER UPDATE trigger
- D . a user defined function
D
Explanation:
Requirements: You must modify the Orders table to meet the following requirements:
Create new rows in the table without granting INSERT permissions to the table.
Notify the sales person who places an order whether or not the order was completed.
References: https://msdn.microsoft.com/en-us/library/ms186755.aspx
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to modify the design of the Orders table.
What should you create?
- A . a stored procedure with the RETURN statement
- B . a FOR UPDATE trigger
- C . an AFTER UPDATE trigger
- D . a user defined function
D
Explanation:
Requirements: You must modify the Orders table to meet the following requirements:
Create new rows in the table without granting INSERT permissions to the table.
Notify the sales person who places an order whether or not the order was completed.
References: https://msdn.microsoft.com/en-us/library/ms186755.aspx
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to update the SalesHistory table
How should you complete the Transact_SQL statement? To answer? select the appropriate Transact-SQL, segments in the answer area.
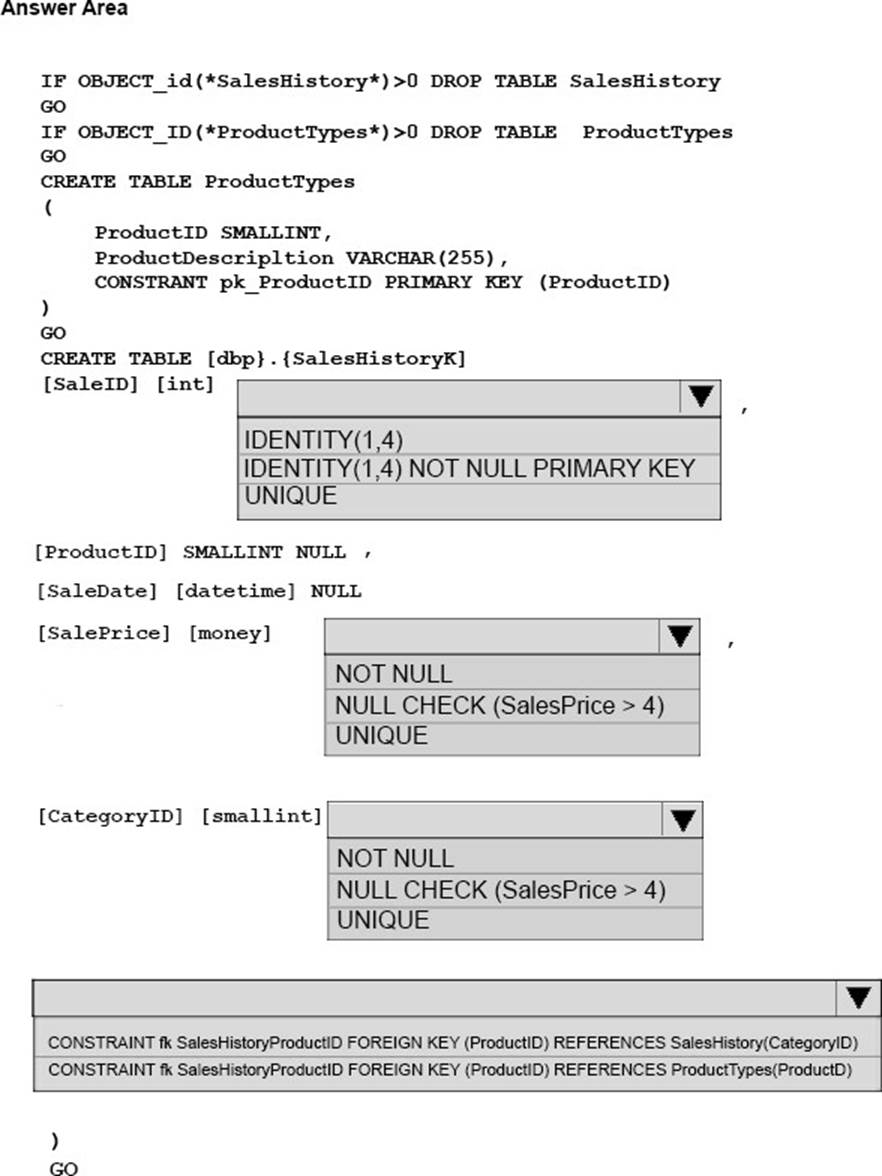

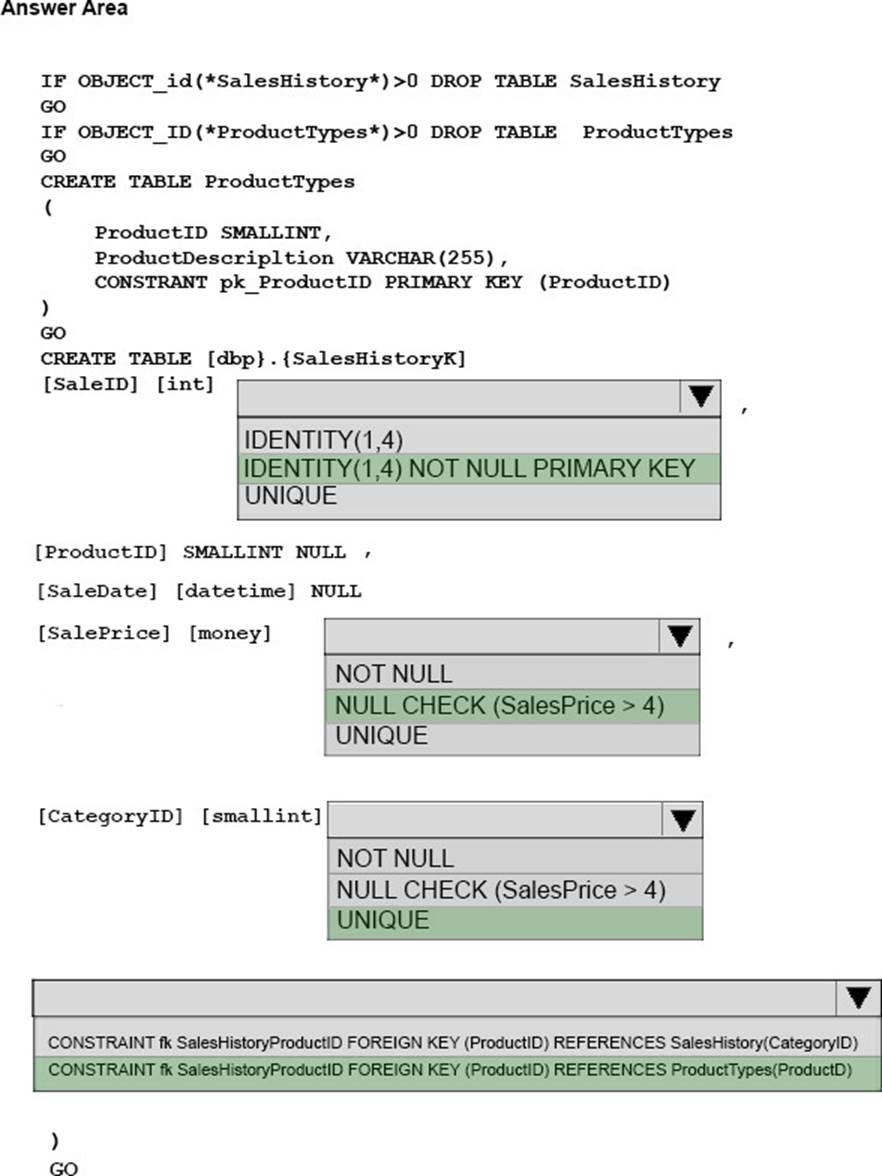
Explanation:
Box 1:
SaleID must be the primary key, as a constraint on the SaleID column that allows the field to be used as a record identifier is required.
Box 2:
A constraint that limits the SalePrice column to values greater than four.
Box 3: UNIQUE
A constraint on the CategoryID column that allows one row with a null value in the column.
Box 4:
A foreign keyconstraint must be put on the productID referencing the ProductTypes table, as a constraint that uses the ProductID column to reference the Product column of the ProductTypes table is required.
Note: Requirements are:
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constraint that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to update the SalesHistory table
How should you complete the Transact_SQL statement? To answer? select the appropriate Transact-SQL, segments in the answer area.
Explanation:
Box 1:
SaleID must be the primary key, as a constraint on the SaleID column that allows the field to be used as a record identifier is required.
Box 2:
A constraint that limits the SalePrice column to values greater than four.
Box 3: UNIQUE
A constraint on the CategoryID column that allows one row with a null value in the column.
Box 4:
A foreign keyconstraint must be put on the productID referencing the ProductTypes table, as a constraint that uses the ProductID column to reference the Product column of the ProductTypes table is required.
Note: Requirements are:
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constraint that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to update the SalesHistory table
How should you complete the Transact_SQL statement? To answer? select the appropriate Transact-SQL, segments in the answer area.
Explanation:
Box 1:
SaleID must be the primary key, as a constraint on the SaleID column that allows the field to be used as a record identifier is required.
Box 2:
A constraint that limits the SalePrice column to values greater than four.
Box 3: UNIQUE
A constraint on the CategoryID column that allows one row with a null value in the column.
Box 4:
A foreign keyconstraint must be put on the productID referencing the ProductTypes table, as a constraint that uses the ProductID column to reference the Product column of the ProductTypes table is required.
Note: Requirements are:
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constraint that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to update the SalesHistory table
How should you complete the Transact_SQL statement? To answer? select the appropriate Transact-SQL, segments in the answer area.
Explanation:
Box 1:
SaleID must be the primary key, as a constraint on the SaleID column that allows the field to be used as a record identifier is required.
Box 2:
A constraint that limits the SalePrice column to values greater than four.
Box 3: UNIQUE
A constraint on the CategoryID column that allows one row with a null value in the column.
Box 4:
A foreign keyconstraint must be put on the productID referencing the ProductTypes table, as a constraint that uses the ProductID column to reference the Product column of the ProductTypes table is required.
Note: Requirements are:
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constraint that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to update the SalesHistory table
How should you complete the Transact_SQL statement? To answer? select the appropriate Transact-SQL, segments in the answer area.
Explanation:
Box 1:
SaleID must be the primary key, as a constraint on the SaleID column that allows the field to be used as a record identifier is required.
Box 2:
A constraint that limits the SalePrice column to values greater than four.
Box 3: UNIQUE
A constraint on the CategoryID column that allows one row with a null value in the column.
Box 4:
A foreign keyconstraint must be put on the productID referencing the ProductTypes table, as a constraint that uses the ProductID column to reference the Product column of the ProductTypes table is required.
Note: Requirements are:
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constraint that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to update the SalesHistory table
How should you complete the Transact_SQL statement? To answer? select the appropriate Transact-SQL, segments in the answer area.
Explanation:
Box 1:
SaleID must be the primary key, as a constraint on the SaleID column that allows the field to be used as a record identifier is required.
Box 2:
A constraint that limits the SalePrice column to values greater than four.
Box 3: UNIQUE
A constraint on the CategoryID column that allows one row with a null value in the column.
Box 4:
A foreign keyconstraint must be put on the productID referencing the ProductTypes table, as a constraint that uses the ProductID column to reference the Product column of the ProductTypes table is required.
Note: Requirements are:
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constraint that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to update the SalesHistory table
How should you complete the Transact_SQL statement? To answer? select the appropriate Transact-SQL, segments in the answer area.
Explanation:
Box 1:
SaleID must be the primary key, as a constraint on the SaleID column that allows the field to be used as a record identifier is required.
Box 2:
A constraint that limits the SalePrice column to values greater than four.
Box 3: UNIQUE
A constraint on the CategoryID column that allows one row with a null value in the column.
Box 4:
A foreign keyconstraint must be put on the productID referencing the ProductTypes table, as a constraint that uses the ProductID column to reference the Product column of the ProductTypes table is required.
Note: Requirements are:
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constraint that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to update the SalesHistory table
How should you complete the Transact_SQL statement? To answer? select the appropriate Transact-SQL, segments in the answer area.
Explanation:
Box 1:
SaleID must be the primary key, as a constraint on the SaleID column that allows the field to be used as a record identifier is required.
Box 2:
A constraint that limits the SalePrice column to values greater than four.
Box 3: UNIQUE
A constraint on the CategoryID column that allows one row with a null value in the column.
Box 4:
A foreign keyconstraint must be put on the productID referencing the ProductTypes table, as a constraint that uses the ProductID column to reference the Product column of the ProductTypes table is required.
Note: Requirements are:
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constraint that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to update the SalesHistory table
How should you complete the Transact_SQL statement? To answer? select the appropriate Transact-SQL, segments in the answer area.
Explanation:
Box 1:
SaleID must be the primary key, as a constraint on the SaleID column that allows the field to be used as a record identifier is required.
Box 2:
A constraint that limits the SalePrice column to values greater than four.
Box 3: UNIQUE
A constraint on the CategoryID column that allows one row with a null value in the column.
Box 4:
A foreign keyconstraint must be put on the productID referencing the ProductTypes table, as a constraint that uses the ProductID column to reference the Product column of the ProductTypes table is required.
Note: Requirements are:
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constraint that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Notify the sales person who places an order whether or not the order was completed.
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constant that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
Finance department users must be able to retrieve data from the SalesHistory table for sales persons where the value of the SalesYTD column is above a certain threshold.
You plan to create a memory-optimized table named SalesOrder.
The table must meet the following requirments:
– The table must hold 10 million unique sales orders.
– The table must use checkpoints to minimize I/O operations and must not use transaction logging.
– Data loss is acceptable.
Performance for queries against the SalesOrder table that use Where clauses with exact equality operations must be optimized.
You need to update the SalesHistory table
How should you complete the Transact_SQL statement? To answer? select the appropriate Transact-SQL, segments in the answer area.
Explanation:
Box 1:
SaleID must be the primary key, as a constraint on the SaleID column that allows the field to be used as a record identifier is required.
Box 2:
A constraint that limits the SalePrice column to values greater than four.
Box 3: UNIQUE
A constraint on the CategoryID column that allows one row with a null value in the column.
Box 4:
A foreign keyconstraint must be put on the productID referencing the ProductTypes table, as a constraint that uses the ProductID column to reference the Product column of the ProductTypes table is required.
Note: Requirements are:
You must add the following constraints to the SalesHistory table:
– a constraint on the SaleID column that allows the field to be used as a record identifier
– a constraint that uses the ProductID column to reference the Product column of the ProductTypes table
– a constraint on the CategoryID column that allows one row with a null value in the column
– a constraint that limits the SalePrice column to values greater than four
If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
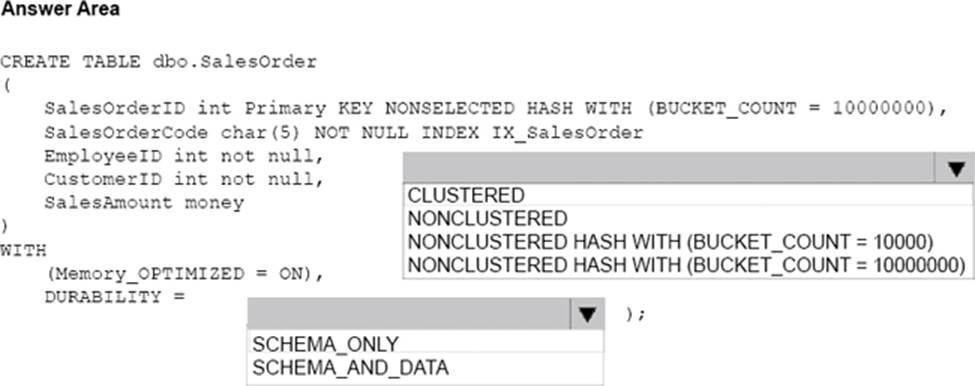

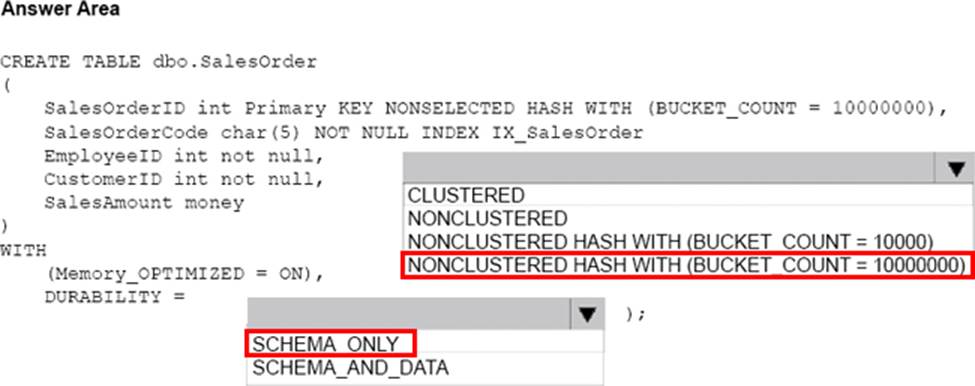
Explanation:
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT
Box 4: ROLLBACK
If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT
Box 4: ROLLBACK
If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT
Box 4: ROLLBACK
If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT
Box 4: ROLLBACK
If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT
Box 4: ROLLBACK
If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT
Box 4: ROLLBACK
If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT
Box 4: ROLLBACK
If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT
Box 4: ROLLBACK
If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT
Box 4: ROLLBACK
If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
Explanation:
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT
Box 4: ROLLBACK
If an error occurs during a delete operation on either table, all changes must be rolled back, otherwise all changes should be committed.
How should you complete the procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
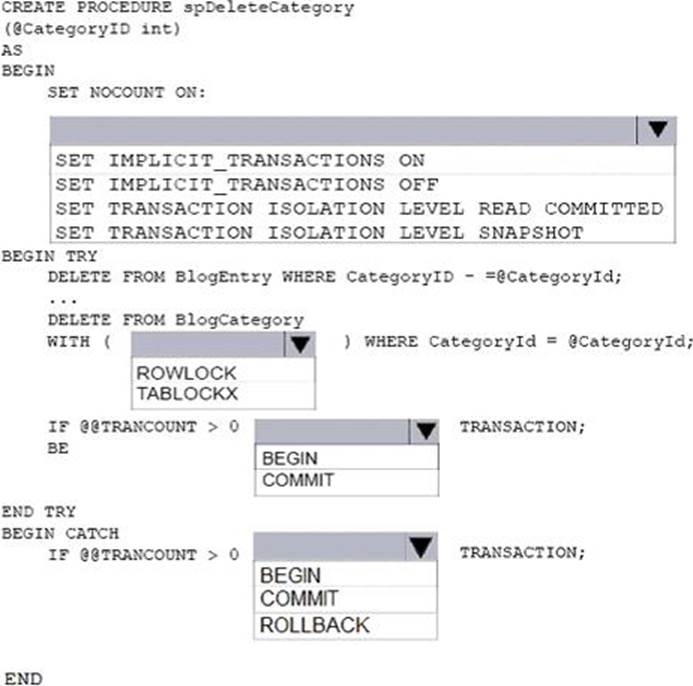

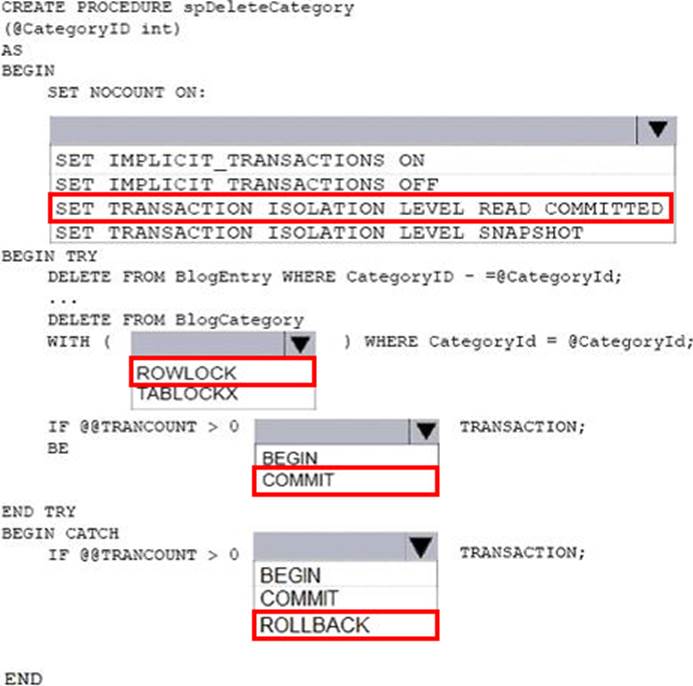
Explanation:
Box 1: SET TRANSACTION ISOLATION LEVEL READ COMMITTED
You can minimize locking contention while protecting transactions from dirty reads of uncommitted data modifications by using either of the following:
* The READ COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option set ON.
* The SNAPSHOT isolation level.
With ROWLOCK we should use READ COMMITTED
Box 2: ROWLOCK
Requirement: Avoid locking the entire table when deleting records from the BlogCategory table
ROWLOCK specifies that row locks are taken when page or table locks are ordinarily taken. When specified in transactions operating at the SNAPSHOT isolation level, row locks are not taken unless ROWLOCK is combined with other table hints that require locks, such as UPDLOCK and HOLDLOCK.
Box 3: COMMIT
Box 4: ROLLBACK
DRAG DROP
You are analyzing the performance of a database environment.
Applications that access the database are experiencing locks that are held for a large amount of time. You are experiencing isolation phenomena such as dirty, nonrepeatable and phantom reads.
You need to identify the impact of specific transaction isolation levels on the concurrency and consistency of data.
What are the consistency and concurrency implications of each transaction isolation level? To answer, drag the appropriate isolation levels to the correct locations. Each isolation level may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.

Explanation:
Read Uncommitted (aka dirty read): A transaction T1executing under this isolation level can access data changed by concurrent transaction(s).
Pros: No read locks needed to read data (i.e. no reader/writer blocking). Note, T1 still takes transaction duration locks for any data modified.
Cons: Data is notguaranteed to be transactionally consistent.
Read Committed: A transaction T1 executing under this isolation level can only access committed data.
Pros: Good compromise between concurrency and consistency.
Cons: Locking and blocking. The data can change when accessed multiple times within the same transaction.
Repeatable Read: A transaction T1 executing under this isolation level can only access committed data with an additional guarantee that any data read cannot change (i.e. it is repeatable) for the duration of the transaction.
Pros: Higher data consistency.
Cons: Locking and blocking. The S locks are held for the duration of the transaction that can lower the concurrency. It does not protect against phantom rows.
Serializable: A transaction T1 executing under this isolation level provides the highest data consistency including elimination of phantoms but at the cost of reduced concurrency. It prevents phantoms by taking a range lock or table level lock if range lock can’t be acquired (i.e. no index on the predicate column) for the duration of the transaction.
Pros: Full data consistency including phantom protection.
Cons: Locking and blocking. The S locks are held for the duration of the transaction that can lower the concurrency.
References: https://blogs.msdn.microsoft.com/sqlcat/2011/02/20/concurrency-series-basics-of-transaction-isolation-levels/
DRAG DROP
You are evaluating the performance of a database environment. You must avoid unnecessary locks and ensure that lost updates do not occur. You need to choose the transaction isolation level for each data scenario.
Which isolation level should you use for each scenario? To answer, drag the appropriate isolation levels to the correct scenarios. Each isolation may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.



Explanation:
Box 1: Read committed
Read Committed: A transaction T1 executing under this isolation level can only access committed data.
Pros: Good compromise between concurrency and consistency.
Cons: Locking and blocking. The data can change whenaccessed multiple times within the same transaction.
Box 2: Read Uncommitted
Read Uncommitted (aka dirty read): A transaction T1 executing under this isolation level can access data changed by concurrent transaction(s).
Pros: No read locks needed to readdata (i.e. no reader/writer blocking). Note, T1 still takes transaction duration locks for any data modified.
Cons: Data is not guaranteed to be transactionally consistent.
Box 3: Serializable
Serializable: A transaction T1 executing under thisisolation level provides the highest data consistency including elimination of phantoms but at the cost of reduced concurrency. It prevents phantoms by taking a range lock or table level lock if range lock can’t be acquired (i.e. no index on the predicatecolumn) for the duration of the transaction.
Pros: Full data consistency including phantom protection.
Cons: Locking and blocking. The S locks are held for the duration of the transaction that can lower the concurrency.
References: https://blogs.msdn.microsoft.com/sqlcat/2011/02/20/concurrency-series-basics-of-transaction-isolation-levels/
DRAG DROP
You have two database tables. Table1 is a partioned table and Table 2 is a nonpartioned table.
Users report that queries take a long time to complete. You monitor queries by using Microsoft SQL Server Profiler. You observe lock escalation for Table1 and Table 2.
You need to allow escalation of Table1 locks to the partition level and prevent all lock escalation for Table2.
Which Transact-SQL statement should you run for each table? To answer, drag the appropriate Transact-SQL statements to the correct tables. Each command may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
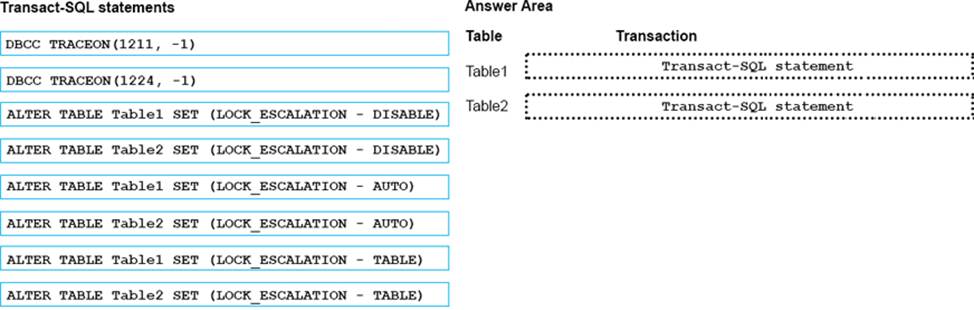

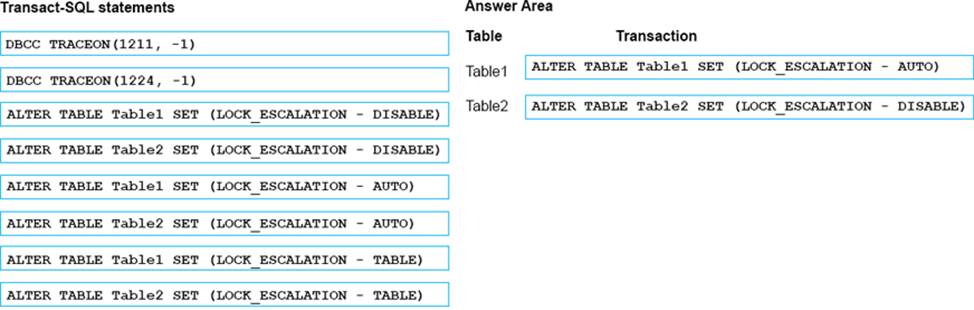
Explanation:
Since SQL Server 2008 you can also control how SQL Server performs the Lock Escalation C through the ALTER TABLE statement and the property LOCK_ESCALATION.
There are 3 different options available:
TABLE
AUTO
DISABLE
Box 1: Table1, Auto
The default option is TABLE, means that SQL Server *always* performs the Lock Escalation to the table level Ceven when the table is partitioned. If you have your table partitioned, and you want to have a Partition Level Lock Escalation (because you have tested your data access pattern, and you don’t cause deadlocks with it), then you can change the option to AUTO. AUTO means that the Lock Escalation is performed to the partition level, if the table is partitioned, and otherwise to the table level.
Box 2: Table 2, DISABLE
With the option DISABLE you can completely disable the Lock Escalation for that specific table.
For partitioned tables, use the LOCK_ESCALATION option of ALTER TABLE to escalate locks to the HoBT level instead of the table or to disable lock escalation.
References: http://www.sqlpassion.at/archive/2014/02/25/lock-escalations/
DRAG DROP
You have a database that contains three encrypted store procedures named dbo.Proc1, dbo.Proc2 and dbo.Proc3. The stored procedures include INSERT, UPDATE, DELETE and BACKUP DATABASE statements.
You have the following requirements:
– You must run all the stored procedures within the same transaction.
– You must automatically start a transaction when stored procedures include DML statements.
– You must not automatically start a transaction when stored procedures include DDL statements.
You need to run all three stored procedures.
Which four Transact-SQL segments should you use to develop the solution? To answer, move the appropriate Transact-SQL segments to the answer area and arrange then in the correct order.



Explanation:
Note:
Implicit transaction mode remains in effect until the connection executes a SET IMPLICIT_TRANSACTIONS OFF statement, which returns the connection to autocommit mode. In autocommit mode, allindividual statements are committed if they complete successfully.
When a connection is in implicit transaction mode and the connection is not currently in a transaction, executing any of the following statements starts a transaction:
ALTER TABLE (DDL)
FETCH
REVOKE
BEGIN TRANSACTION
GRANT
SELECT
CREATE (DDL)
INSERT
TRUNCATE TABLE
DELETE (DML)
OPEN
UPDATE (DML)
DROP (DDL)
Note 2: XACT_STATE returns the following values.
1 The current request has an active user transaction. The request can perform any actions, including writing data and committing the transaction. The transaction is committable.
-1 The current request has an active user transaction, but an error has occurred that has caused the transaction to be classified as an uncommittable transaction.the transaction is uncommittable and should be rolled back.
0 There is no active user transaction for the current request. Acommit or rollback operation would generate an error.
References:
https://technet.microsoft.com/en-us/library/ms187807(v=sql.105).aspx
https://technet.microsoft.com/en-us/library/ms189797(v=sql.110).aspx
HOTSPOT
You are profiling a frequently used database table named UserEvents. The READ_COMMITED_SNAPSHOT database option is set to OFF.
In the trace results, you observe that lock escalation occurred for one stored procedure even though the number of locks in the database did not exceed memory or configuration thresholds.
Events details are provided in the following table:
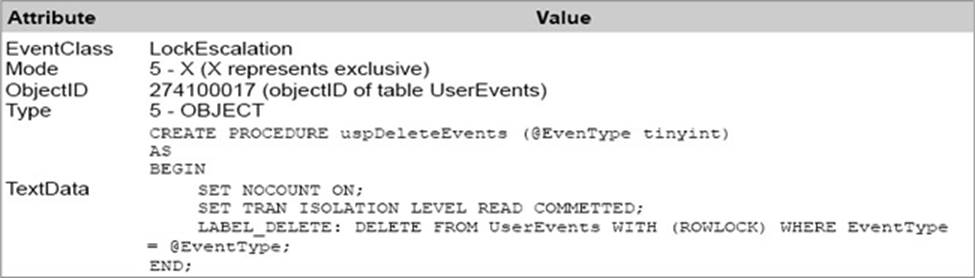

You need to modify the uspDeleteEvents stored procedure to avoid lock escalation.
How should you modify the stored procedure? To answer, select the appropriate Transact-SQL segments in the answer area.
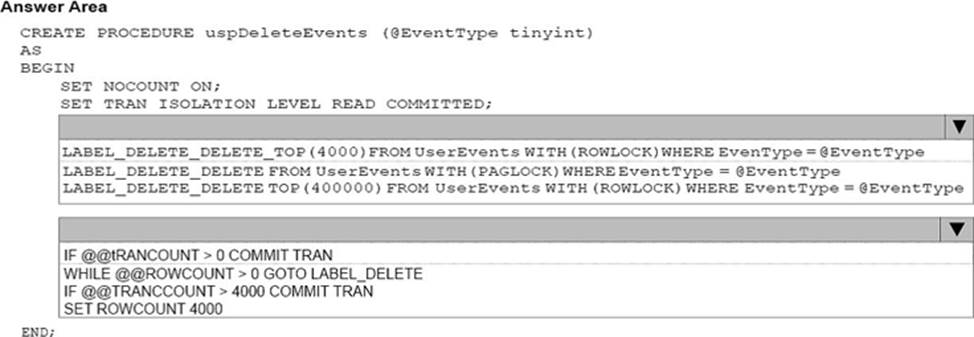

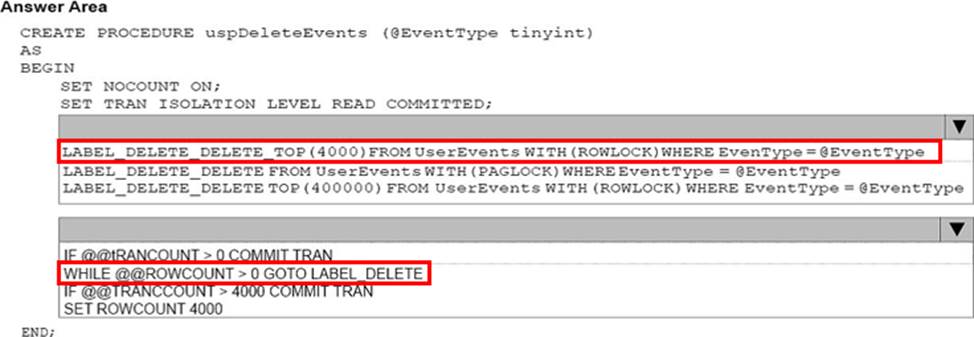
Explanation:
Delete up to 4000 rows at a time. Keep doing it until all rows have been deleted.
Note that @@ROWCOUNT returns the number of rows affected by the last statement.
References: https://msdn.microsoft.com/en-us/library/ms187316.aspx
You have a database that is experiencing deadlock issues when users run queries. You need to ensure that all deadlocks are recorded in XML format.
What should you do?
- A . Create a Microsoft SQL Server Integration Services package that uses sys.dm_tran_locks.
- B . Enable trace flag 1224 by using the Database Cpmsistency Checker (BDCC).
- C . Enable trace flag 1222 in the startup options for Microsoft SQL Server.
- D . Use the Microsoft SQL Server Profiler Lock:Deadlock event class.
C
Explanation:
When deadlocks occur, trace flag 1204 and trace flag 1222 return information that is capturedin the SQL Server error log. Trace flag 1204 reports deadlock information formatted by each node involved in the deadlock. Trace flag 1222 formats deadlock information, first by processes and then by resources.
The output format for Trace Flag 1222 only returns information in an XML-like format.
References: https://technet.microsoft.com/en-us/library/ms178104(v=sql.105).aspx
You are developing an application that connects to a database.
The application runs the following jobs:
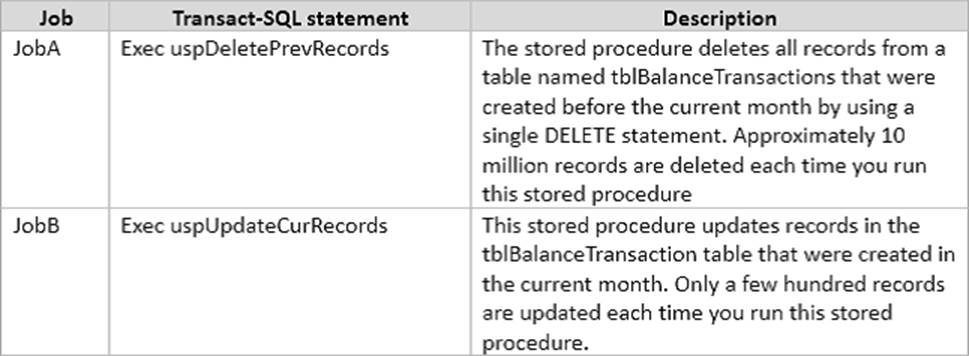

The READ_COMMITTED_SNAPSHOT database option is set to OFF, and auto-content is set to ON. Within the stored procedures, no explicit transactions are defined.
If JobB starts before JobA, it can finish in seconds. If JobA starts first, JobB takes a long time to complete. You need to use Microsoft SQL Server Profiler to determine whether the blocking that you observe in JobB is caused by locks acquired by JobA.
Which trace event class in the Locks event category should you use?
- A . LockAcquired
- B . LockCancel
- C . LockDeadlock
- D . LockEscalation
A
Explanation:
The Lock:Acquiredevent class indicates that acquisition of a lock on a resource, such asa data page, has been achieved. The Lock: Acquired and Lock: Released event classes can be used to monitor when objects are being locked, the type of locks taken, and for how long the locks were retained. Locks retained for long periods of time may cause contention issues and should be investigated.
HOTSPOT
You have a database that contains both disk-based and memory-optimized tables. You need to create two modules.
The modules must meet the requirements described in the following table.


Which programming object should you use for each module? To answer, select the appropriate object types in the answer area.
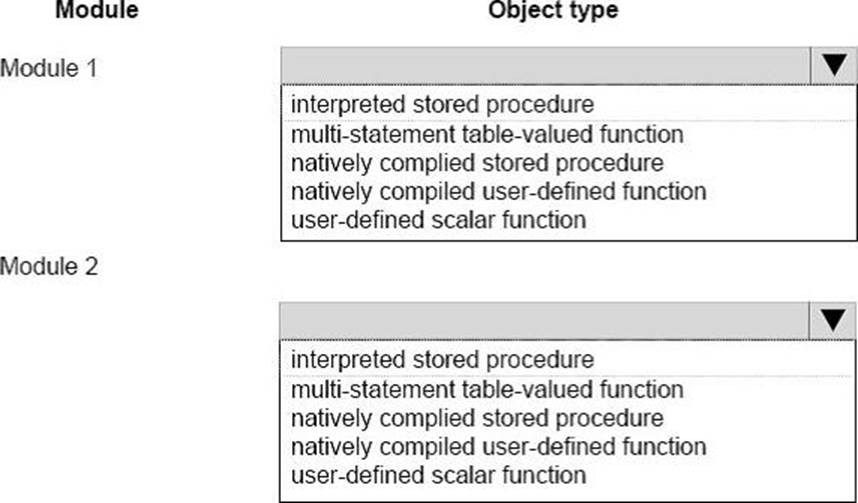


Explanation:
Returning Data by Using OUTPUT Parameters
If you specify the OUTPUT keyword for aparameter in the procedure definition, the stored procedure can return the current value of the parameter to the calling program when the stored procedure exits.
SQL Server stored procedures, views and functions are able to use the WITH ENCRYPTION optionto disguise the contents of a particular procedure or function from discovery.
Native Compilation of Tables and Stored Procedures
In-Memory OLTP introduces the concept of native compilation. SQL Server can natively compile stored procedures that accessmemory-optimized tables. SQL Server is also able to nativelycompile memory-optimized tables. Native compilation allows faster data access and more efficient query execution than interpreted (traditional) Transact-SQL. Native compilation of tables and stored procedures produce DLLs.
References: https://technet.microsoft.com/en-us/library/ms187004(v=sql.105).aspx
https://msdn.microsoft.com/en-us/library/dn249342.aspx
HOTSPOT
You have a database that contains both disk-based and memory-optimized tables. You need to create two modules.
The modules must meet the requirements described in the following table.
Which programming object should you use for each module? To answer, select the appropriate object types in the answer area.
Explanation:
Returning Data by Using OUTPUT Parameters
If you specify the OUTPUT keyword for aparameter in the procedure definition, the stored procedure can return the current value of the parameter to the calling program when the stored procedure exits.
SQL Server stored procedures, views and functions are able to use the WITH ENCRYPTION optionto disguise the contents of a particular procedure or function from discovery.
Native Compilation of Tables and Stored Procedures
In-Memory OLTP introduces the concept of native compilation. SQL Server can natively compile stored procedures that accessmemory-optimized tables. SQL Server is also able to nativelycompile memory-optimized tables. Native compilation allows faster data access and more efficient query execution than interpreted (traditional) Transact-SQL. Native compilation of tables and stored procedures produce DLLs.
References: https://technet.microsoft.com/en-us/library/ms187004(v=sql.105).aspx
https://msdn.microsoft.com/en-us/library/dn249342.aspx
HOTSPOT
You have a database that contains both disk-based and memory-optimized tables. You need to create two modules.
The modules must meet the requirements described in the following table.
Which programming object should you use for each module? To answer, select the appropriate object types in the answer area.
Explanation:
Returning Data by Using OUTPUT Parameters
If you specify the OUTPUT keyword for aparameter in the procedure definition, the stored procedure can return the current value of the parameter to the calling program when the stored procedure exits.
SQL Server stored procedures, views and functions are able to use the WITH ENCRYPTION optionto disguise the contents of a particular procedure or function from discovery.
Native Compilation of Tables and Stored Procedures
In-Memory OLTP introduces the concept of native compilation. SQL Server can natively compile stored procedures that accessmemory-optimized tables. SQL Server is also able to nativelycompile memory-optimized tables. Native compilation allows faster data access and more efficient query execution than interpreted (traditional) Transact-SQL. Native compilation of tables and stored procedures produce DLLs.
References: https://technet.microsoft.com/en-us/library/ms187004(v=sql.105).aspx
https://msdn.microsoft.com/en-us/library/dn249342.aspx
HOTSPOT
You have a database that contains both disk-based and memory-optimized tables. You need to create two modules.
The modules must meet the requirements described in the following table.
Which programming object should you use for each module? To answer, select the appropriate object types in the answer area.
Explanation:
Returning Data by Using OUTPUT Parameters
If you specify the OUTPUT keyword for aparameter in the procedure definition, the stored procedure can return the current value of the parameter to the calling program when the stored procedure exits.
SQL Server stored procedures, views and functions are able to use the WITH ENCRYPTION optionto disguise the contents of a particular procedure or function from discovery.
Native Compilation of Tables and Stored Procedures
In-Memory OLTP introduces the concept of native compilation. SQL Server can natively compile stored procedures that accessmemory-optimized tables. SQL Server is also able to nativelycompile memory-optimized tables. Native compilation allows faster data access and more efficient query execution than interpreted (traditional) Transact-SQL. Native compilation of tables and stored procedures produce DLLs.
References: https://technet.microsoft.com/en-us/library/ms187004(v=sql.105).aspx
https://msdn.microsoft.com/en-us/library/dn249342.aspx
HOTSPOT
You have a database that contains both disk-based and memory-optimized tables. You need to create two modules.
The modules must meet the requirements described in the following table.
Which programming object should you use for each module? To answer, select the appropriate object types in the answer area.
Explanation:
Returning Data by Using OUTPUT Parameters
If you specify the OUTPUT keyword for aparameter in the procedure definition, the stored procedure can return the current value of the parameter to the calling program when the stored procedure exits.
SQL Server stored procedures, views and functions are able to use the WITH ENCRYPTION optionto disguise the contents of a particular procedure or function from discovery.
Native Compilation of Tables and Stored Procedures
In-Memory OLTP introduces the concept of native compilation. SQL Server can natively compile stored procedures that accessmemory-optimized tables. SQL Server is also able to nativelycompile memory-optimized tables. Native compilation allows faster data access and more efficient query execution than interpreted (traditional) Transact-SQL. Native compilation of tables and stored procedures produce DLLs.
References: https://technet.microsoft.com/en-us/library/ms187004(v=sql.105).aspx
https://msdn.microsoft.com/en-us/library/dn249342.aspx
HOTSPOT
You have a database that contains both disk-based and memory-optimized tables. You need to create two modules.
The modules must meet the requirements described in the following table.
Which programming object should you use for each module? To answer, select the appropriate object types in the answer area.
Explanation:
Returning Data by Using OUTPUT Parameters
If you specify the OUTPUT keyword for aparameter in the procedure definition, the stored procedure can return the current value of the parameter to the calling program when the stored procedure exits.
SQL Server stored procedures, views and functions are able to use the WITH ENCRYPTION optionto disguise the contents of a particular procedure or function from discovery.
Native Compilation of Tables and Stored Procedures
In-Memory OLTP introduces the concept of native compilation. SQL Server can natively compile stored procedures that accessmemory-optimized tables. SQL Server is also able to nativelycompile memory-optimized tables. Native compilation allows faster data access and more efficient query execution than interpreted (traditional) Transact-SQL. Native compilation of tables and stored procedures produce DLLs.
References: https://technet.microsoft.com/en-us/library/ms187004(v=sql.105).aspx
https://msdn.microsoft.com/en-us/library/dn249342.aspx
HOTSPOT
You have a database that contains both disk-based and memory-optimized tables. You need to create two modules.
The modules must meet the requirements described in the following table.
Which programming object should you use for each module? To answer, select the appropriate object types in the answer area.
Explanation:
Returning Data by Using OUTPUT Parameters
If you specify the OUTPUT keyword for aparameter in the procedure definition, the stored procedure can return the current value of the parameter to the calling program when the stored procedure exits.
SQL Server stored procedures, views and functions are able to use the WITH ENCRYPTION optionto disguise the contents of a particular procedure or function from discovery.
Native Compilation of Tables and Stored Procedures
In-Memory OLTP introduces the concept of native compilation. SQL Server can natively compile stored procedures that accessmemory-optimized tables. SQL Server is also able to nativelycompile memory-optimized tables. Native compilation allows faster data access and more efficient query execution than interpreted (traditional) Transact-SQL. Native compilation of tables and stored procedures produce DLLs.
References: https://technet.microsoft.com/en-us/library/ms187004(v=sql.105).aspx
https://msdn.microsoft.com/en-us/library/dn249342.aspx
HOTSPOT
You have a database that contains both disk-based and memory-optimized tables. You need to create two modules.
The modules must meet the requirements described in the following table.
Which programming object should you use for each module? To answer, select the appropriate object types in the answer area.
Explanation:
Returning Data by Using OUTPUT Parameters
If you specify the OUTPUT keyword for aparameter in the procedure definition, the stored procedure can return the current value of the parameter to the calling program when the stored procedure exits.
SQL Server stored procedures, views and functions are able to use the WITH ENCRYPTION optionto disguise the contents of a particular procedure or function from discovery.
Native Compilation of Tables and Stored Procedures
In-Memory OLTP introduces the concept of native compilation. SQL Server can natively compile stored procedures that accessmemory-optimized tables. SQL Server is also able to nativelycompile memory-optimized tables. Native compilation allows faster data access and more efficient query execution than interpreted (traditional) Transact-SQL. Native compilation of tables and stored procedures produce DLLs.
References: https://technet.microsoft.com/en-us/library/ms187004(v=sql.105).aspx
https://msdn.microsoft.com/en-us/library/dn249342.aspx
HOTSPOT
You have a database that contains both disk-based and memory-optimized tables. You need to create two modules.
The modules must meet the requirements described in the following table.
Which programming object should you use for each module? To answer, select the appropriate object types in the answer area.
Explanation:
Returning Data by Using OUTPUT Parameters
If you specify the OUTPUT keyword for aparameter in the procedure definition, the stored procedure can return the current value of the parameter to the calling program when the stored procedure exits.
SQL Server stored procedures, views and functions are able to use the WITH ENCRYPTION optionto disguise the contents of a particular procedure or function from discovery.
Native Compilation of Tables and Stored Procedures
In-Memory OLTP introduces the concept of native compilation. SQL Server can natively compile stored procedures that accessmemory-optimized tables. SQL Server is also able to nativelycompile memory-optimized tables. Native compilation allows faster data access and more efficient query execution than interpreted (traditional) Transact-SQL. Native compilation of tables and stored procedures produce DLLs.
References: https://technet.microsoft.com/en-us/library/ms187004(v=sql.105).aspx
https://msdn.microsoft.com/en-us/library/dn249342.aspx
HOTSPOT
You have a database that contains both disk-based and memory-optimized tables. You need to create two modules.
The modules must meet the requirements described in the following table.
Which programming object should you use for each module? To answer, select the appropriate object types in the answer area.
Explanation:
Returning Data by Using OUTPUT Parameters
If you specify the OUTPUT keyword for aparameter in the procedure definition, the stored procedure can return the current value of the parameter to the calling program when the stored procedure exits.
SQL Server stored procedures, views and functions are able to use the WITH ENCRYPTION optionto disguise the contents of a particular procedure or function from discovery.
Native Compilation of Tables and Stored Procedures
In-Memory OLTP introduces the concept of native compilation. SQL Server can natively compile stored procedures that accessmemory-optimized tables. SQL Server is also able to nativelycompile memory-optimized tables. Native compilation allows faster data access and more efficient query execution than interpreted (traditional) Transact-SQL. Native compilation of tables and stored procedures produce DLLs.
References: https://technet.microsoft.com/en-us/library/ms187004(v=sql.105).aspx
https://msdn.microsoft.com/en-us/library/dn249342.aspx
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Users must be able to retrieve an account number by supplying customer information.
You need to implement the design changes while minimizing data redundancy.
What should you do?
- A . Split the table into three separate tables. Include the AccountNumber and CustomerID columns in the first table. Include the CustomerName and Gender columns in the second table. Include the AccountStatus column in the third table.
- B . Split the table into two separate tables. Include AccountNumber, CustomerID, CustomerName and Gender columns in the first table. Include the AccountNumber and AccountStatus columns in the second table.
- C . Split the table into two separate tables, Include the CustomerID and AccountNumber columns in the first table. Include the AccountNumber, AccountStatus, CustomerName and Gender columns in the second table.
- D . Split the table into two separate tables, Include the CustomerID, CustomerName and Gender columns in the first table. Include AccountNumber, AccountStatus and CustomerID columns in the second table.
D
Explanation:
Two tables is enough.CustomerID must be in both tables.
Contains all of the columns required by the SELECT statement.
Which three Transact_SQL segments should you use to develop the solution? To answer, move the appropriate code blocks from the list of code blocks to the answer area and arrange them in the correct order.


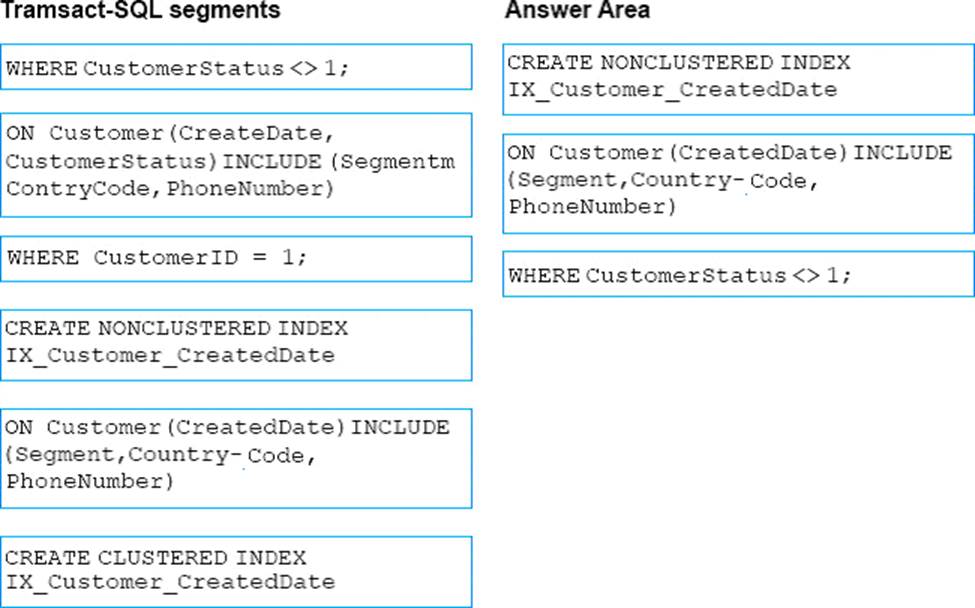
Explanation:
Box 1: Clustered Index
With the same size of keys, the nonclustered indexes need more space than clustered indexes.
Box 2, Box 3:
Include the CustomerStatus column in the index, and only when CustomerStatusnot equal to 1 (the active customers).
References: http://www.sqlserverlogexplorer.com/overview-of-cluster-and-noncluster-index/
Contains all of the columns required by the SELECT statement.
Which three Transact_SQL segments should you use to develop the solution? To answer, move the appropriate code blocks from the list of code blocks to the answer area and arrange them in the correct order.
Explanation:
Box 1: Clustered Index
With the same size of keys, the nonclustered indexes need more space than clustered indexes.
Box 2, Box 3:
Include the CustomerStatus column in the index, and only when CustomerStatusnot equal to 1 (the active customers).
References: http://www.sqlserverlogexplorer.com/overview-of-cluster-and-noncluster-index/
Contains all of the columns required by the SELECT statement.
Which three Transact_SQL segments should you use to develop the solution? To answer, move the appropriate code blocks from the list of code blocks to the answer area and arrange them in the correct order.
Explanation:
Box 1: Clustered Index
With the same size of keys, the nonclustered indexes need more space than clustered indexes.
Box 2, Box 3:
Include the CustomerStatus column in the index, and only when CustomerStatusnot equal to 1 (the active customers).
References: http://www.sqlserverlogexplorer.com/overview-of-cluster-and-noncluster-index/
Contains all of the columns required by the SELECT statement.
Which three Transact_SQL segments should you use to develop the solution? To answer, move the appropriate code blocks from the list of code blocks to the answer area and arrange them in the correct order.
Explanation:
Box 1: Clustered Index
With the same size of keys, the nonclustered indexes need more space than clustered indexes.
Box 2, Box 3:
Include the CustomerStatus column in the index, and only when CustomerStatusnot equal to 1 (the active customers).
References: http://www.sqlserverlogexplorer.com/overview-of-cluster-and-noncluster-index/
Contains all of the columns required by the SELECT statement.
Which three Transact_SQL segments should you use to develop the solution? To answer, move the appropriate code blocks from the list of code blocks to the answer area and arrange them in the correct order.
Explanation:
Box 1: Clustered Index
With the same size of keys, the nonclustered indexes need more space than clustered indexes.
Box 2, Box 3:
Include the CustomerStatus column in the index, and only when CustomerStatusnot equal to 1 (the active customers).
References: http://www.sqlserverlogexplorer.com/overview-of-cluster-and-noncluster-index/
Contains all of the columns required by the SELECT statement.
Which three Transact_SQL segments should you use to develop the solution? To answer, move the appropriate code blocks from the list of code blocks to the answer area and arrange them in the correct order.
Explanation:
Box 1: Clustered Index
With the same size of keys, the nonclustered indexes need more space than clustered indexes.
Box 2, Box 3:
Include the CustomerStatus column in the index, and only when CustomerStatusnot equal to 1 (the active customers).
References: http://www.sqlserverlogexplorer.com/overview-of-cluster-and-noncluster-index/
Contains all of the columns required by the SELECT statement.
Which three Transact_SQL segments should you use to develop the solution? To answer, move the appropriate code blocks from the list of code blocks to the answer area and arrange them in the correct order.
Explanation:
Box 1: Clustered Index
With the same size of keys, the nonclustered indexes need more space than clustered indexes.
Box 2, Box 3:
Include the CustomerStatus column in the index, and only when CustomerStatusnot equal to 1 (the active customers).
References: http://www.sqlserverlogexplorer.com/overview-of-cluster-and-noncluster-index/
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
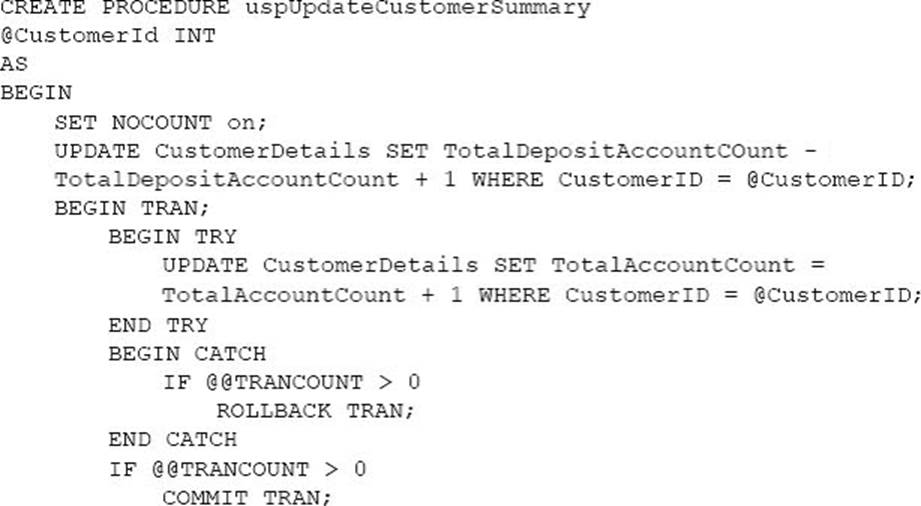

You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
When a procedure calls spDeleteCustAcctRelationship, if the calling stored procedures has already started an active transaction, all the detections made by the spDeleteCustAccRelationship stored procedure must be committed by the caller; otherwise changes must be committed within the spDeleteCustAcctRelationship stored procedure. If any error occurs during the delete operation, only the deletes made by the soDeleteCustACCTRelationships stored procedure must be rolled back and the status must be updated.
You need to complete the stored procedure to ensure all the requirements are met.
How should you complete the procedure? To answer, drag the Transact-SQL segments to the correct location. Each transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.


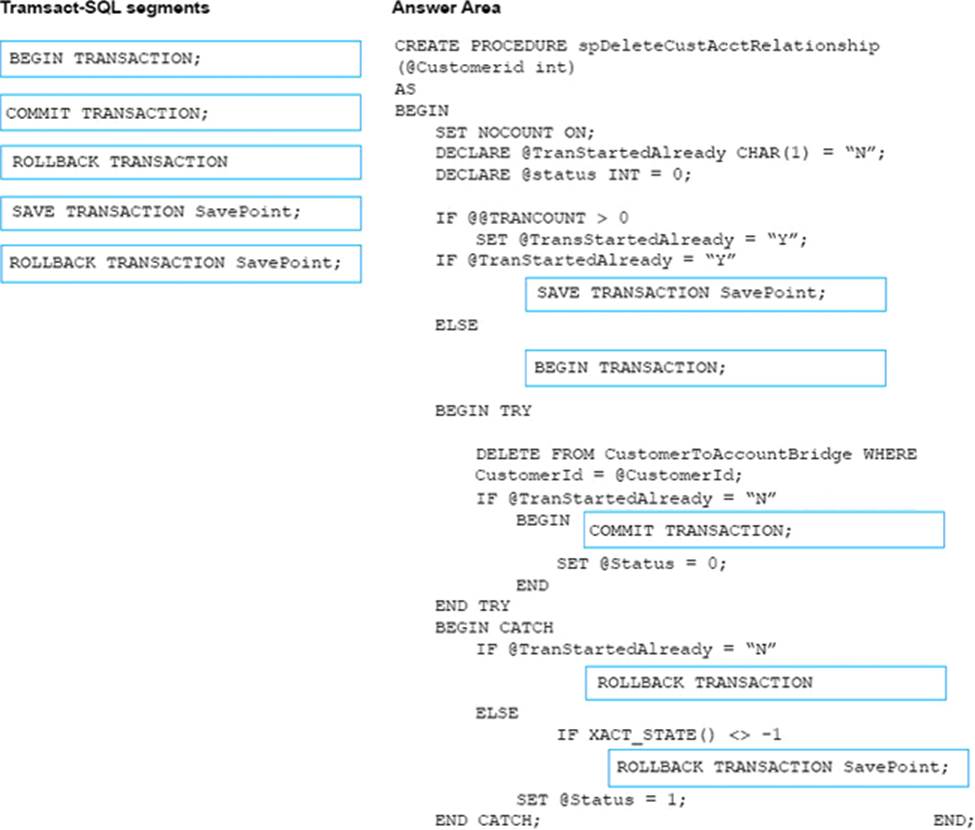
Explanation:
Savepoints offer a mechanism to roll back portions of transactions. You create a savepoint using the SAVE TRANSACTION savepoint_name statement. Later, you execute a ROLLBACK TRANSACTION savepoint_name statement to roll back to the savepoint instead of rolling back to the start of the transaction.
References: https://technet.microsoft.com/en-us/library/ms178157(v=sql.105).aspx
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
When a procedure calls spDeleteCustAcctRelationship, if the calling stored procedures has already started an active transaction, all the detections made by the spDeleteCustAccRelationship stored procedure must be committed by the caller; otherwise changes must be committed within the spDeleteCustAcctRelationship stored procedure. If any error occurs during the delete operation, only the deletes made by the soDeleteCustACCTRelationships stored procedure must be rolled back and the status must be updated.
You need to complete the stored procedure to ensure all the requirements are met.
How should you complete the procedure? To answer, drag the Transact-SQL segments to the correct location. Each transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
Explanation:
Savepoints offer a mechanism to roll back portions of transactions. You create a savepoint using the SAVE TRANSACTION savepoint_name statement. Later, you execute a ROLLBACK TRANSACTION savepoint_name statement to roll back to the savepoint instead of rolling back to the start of the transaction.
References: https://technet.microsoft.com/en-us/library/ms178157(v=sql.105).aspx
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
When a procedure calls spDeleteCustAcctRelationship, if the calling stored procedures has already started an active transaction, all the detections made by the spDeleteCustAccRelationship stored procedure must be committed by the caller; otherwise changes must be committed within the spDeleteCustAcctRelationship stored procedure. If any error occurs during the delete operation, only the deletes made by the soDeleteCustACCTRelationships stored procedure must be rolled back and the status must be updated.
You need to complete the stored procedure to ensure all the requirements are met.
How should you complete the procedure? To answer, drag the Transact-SQL segments to the correct location. Each transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
Explanation:
Savepoints offer a mechanism to roll back portions of transactions. You create a savepoint using the SAVE TRANSACTION savepoint_name statement. Later, you execute a ROLLBACK TRANSACTION savepoint_name statement to roll back to the savepoint instead of rolling back to the start of the transaction.
References: https://technet.microsoft.com/en-us/library/ms178157(v=sql.105).aspx
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
When a procedure calls spDeleteCustAcctRelationship, if the calling stored procedures has already started an active transaction, all the detections made by the spDeleteCustAccRelationship stored procedure must be committed by the caller; otherwise changes must be committed within the spDeleteCustAcctRelationship stored procedure. If any error occurs during the delete operation, only the deletes made by the soDeleteCustACCTRelationships stored procedure must be rolled back and the status must be updated.
You need to complete the stored procedure to ensure all the requirements are met.
How should you complete the procedure? To answer, drag the Transact-SQL segments to the correct location. Each transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
Explanation:
Savepoints offer a mechanism to roll back portions of transactions. You create a savepoint using the SAVE TRANSACTION savepoint_name statement. Later, you execute a ROLLBACK TRANSACTION savepoint_name statement to roll back to the savepoint instead of rolling back to the start of the transaction.
References: https://technet.microsoft.com/en-us/library/ms178157(v=sql.105).aspx
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
When a procedure calls spDeleteCustAcctRelationship, if the calling stored procedures has already started an active transaction, all the detections made by the spDeleteCustAccRelationship stored procedure must be committed by the caller; otherwise changes must be committed within the spDeleteCustAcctRelationship stored procedure. If any error occurs during the delete operation, only the deletes made by the soDeleteCustACCTRelationships stored procedure must be rolled back and the status must be updated.
You need to complete the stored procedure to ensure all the requirements are met.
How should you complete the procedure? To answer, drag the Transact-SQL segments to the correct location. Each transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
Explanation:
Savepoints offer a mechanism to roll back portions of transactions. You create a savepoint using the SAVE TRANSACTION savepoint_name statement. Later, you execute a ROLLBACK TRANSACTION savepoint_name statement to roll back to the savepoint instead of rolling back to the start of the transaction.
References: https://technet.microsoft.com/en-us/library/ms178157(v=sql.105).aspx
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
When a procedure calls spDeleteCustAcctRelationship, if the calling stored procedures has already started an active transaction, all the detections made by the spDeleteCustAccRelationship stored procedure must be committed by the caller; otherwise changes must be committed within the spDeleteCustAcctRelationship stored procedure. If any error occurs during the delete operation, only the deletes made by the soDeleteCustACCTRelationships stored procedure must be rolled back and the status must be updated.
You need to complete the stored procedure to ensure all the requirements are met.
How should you complete the procedure? To answer, drag the Transact-SQL segments to the correct location. Each transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
Explanation:
Savepoints offer a mechanism to roll back portions of transactions. You create a savepoint using the SAVE TRANSACTION savepoint_name statement. Later, you execute a ROLLBACK TRANSACTION savepoint_name statement to roll back to the savepoint instead of rolling back to the start of the transaction.
References: https://technet.microsoft.com/en-us/library/ms178157(v=sql.105).aspx
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
When a procedure calls spDeleteCustAcctRelationship, if the calling stored procedures has already started an active transaction, all the detections made by the spDeleteCustAccRelationship stored procedure must be committed by the caller; otherwise changes must be committed within the spDeleteCustAcctRelationship stored procedure. If any error occurs during the delete operation, only the deletes made by the soDeleteCustACCTRelationships stored procedure must be rolled back and the status must be updated.
You need to complete the stored procedure to ensure all the requirements are met.
How should you complete the procedure? To answer, drag the Transact-SQL segments to the correct location. Each transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.
Explanation:
Savepoints offer a mechanism to roll back portions of transactions. You create a savepoint using the SAVE TRANSACTION savepoint_name statement. Later, you execute a ROLLBACK TRANSACTION savepoint_name statement to roll back to the savepoint instead of rolling back to the start of the transaction.
References: https://technet.microsoft.com/en-us/library/ms178157(v=sql.105).aspx
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
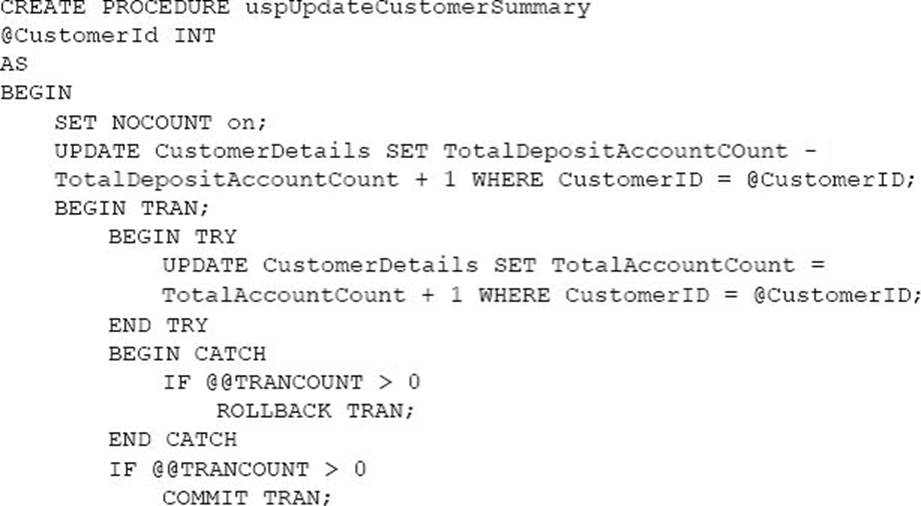
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Website Customer.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations, Each Transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
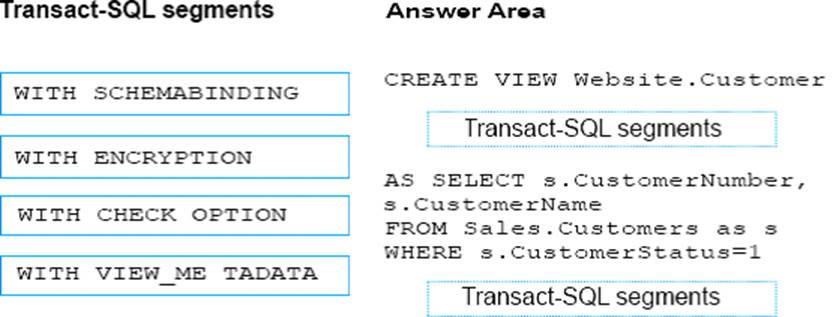

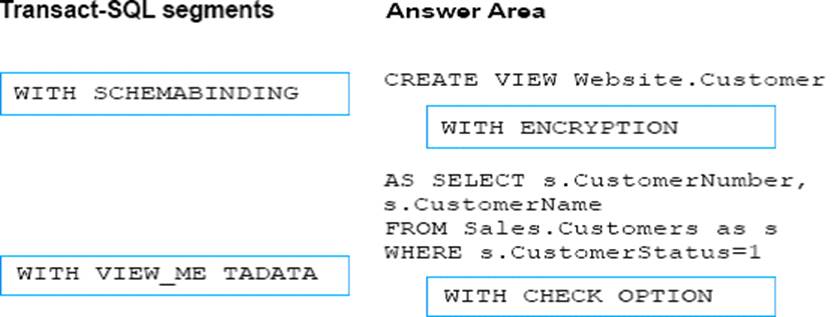
Explanation:
Box 1: WITH ENCRYPTION
Using WITH ENCRYPTION prevents the view from being published as part of SQL Server replication.
Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Website.Customer must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Website Customer.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations, Each Transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Explanation:
Box 1: WITH ENCRYPTION
Using WITH ENCRYPTION prevents the view from being published as part of SQL Server replication.
Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Website.Customer must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Website Customer.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations, Each Transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Explanation:
Box 1: WITH ENCRYPTION
Using WITH ENCRYPTION prevents the view from being published as part of SQL Server replication.
Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Website.Customer must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Website Customer.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations, Each Transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Explanation:
Box 1: WITH ENCRYPTION
Using WITH ENCRYPTION prevents the view from being published as part of SQL Server replication.
Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Website.Customer must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Website Customer.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations, Each Transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Explanation:
Box 1: WITH ENCRYPTION
Using WITH ENCRYPTION prevents the view from being published as part of SQL Server replication.
Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Website.Customer must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Website Customer.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations, Each Transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Explanation:
Box 1: WITH ENCRYPTION
Using WITH ENCRYPTION prevents the view from being published as part of SQL Server replication.
Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Website.Customer must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Website Customer.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations, Each Transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Explanation:
Box 1: WITH ENCRYPTION
Using WITH ENCRYPTION prevents the view from being published as part of SQL Server replication.
Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Website.Customer must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Website Customer.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations, Each Transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Explanation:
Box 1: WITH ENCRYPTION
Using WITH ENCRYPTION prevents the view from being published as part of SQL Server replication.
Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Website.Customer must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Website Customer.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations, Each Transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Explanation:
Box 1: WITH ENCRYPTION
Using WITH ENCRYPTION prevents the view from being published as part of SQL Server replication.
Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Website.Customer must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Website Customer.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations, Each Transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Explanation:
Box 1: WITH ENCRYPTION
Using WITH ENCRYPTION prevents the view from being published as part of SQL Server replication.
Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Website.Customer must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
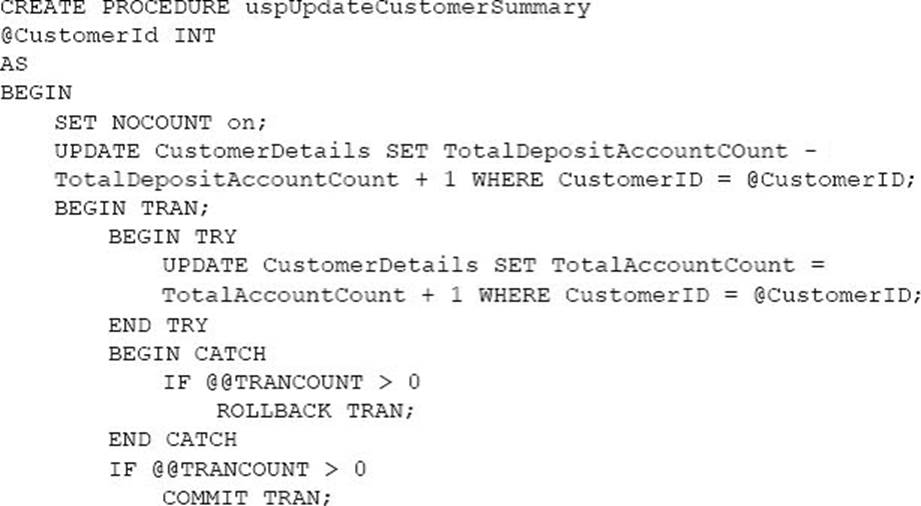
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Sales.FemaleCustomers.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact_SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
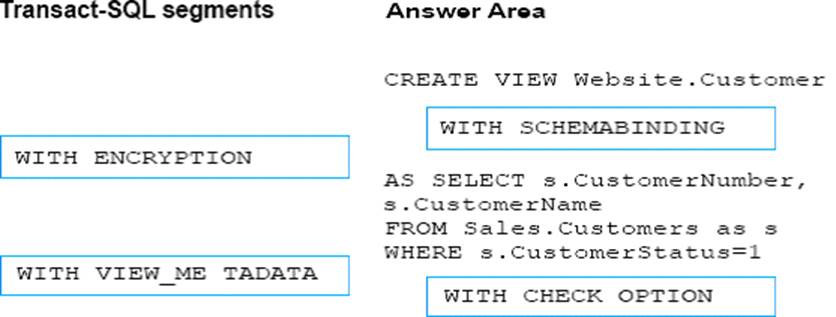
Explanation:
Box 1: WITH SCHEMABINDING:
SCHEMABINDING binds the view to the schema of the underlying table or tables. When SCHEMABINDING is specified, the base table or tables cannot be modified in a way that would affect the view definition.
Box 2: Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Sales.Female.Customers must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Sales.FemaleCustomers.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact_SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
Explanation:
Box 1: WITH SCHEMABINDING:
SCHEMABINDING binds the view to the schema of the underlying table or tables. When SCHEMABINDING is specified, the base table or tables cannot be modified in a way that would affect the view definition.
Box 2: Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Sales.Female.Customers must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Sales.FemaleCustomers.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact_SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
Explanation:
Box 1: WITH SCHEMABINDING:
SCHEMABINDING binds the view to the schema of the underlying table or tables. When SCHEMABINDING is specified, the base table or tables cannot be modified in a way that would affect the view definition.
Box 2: Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Sales.Female.Customers must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Sales.FemaleCustomers.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact_SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
Explanation:
Box 1: WITH SCHEMABINDING:
SCHEMABINDING binds the view to the schema of the underlying table or tables. When SCHEMABINDING is specified, the base table or tables cannot be modified in a way that would affect the view definition.
Box 2: Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Sales.Female.Customers must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Sales.FemaleCustomers.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact_SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
Explanation:
Box 1: WITH SCHEMABINDING:
SCHEMABINDING binds the view to the schema of the underlying table or tables. When SCHEMABINDING is specified, the base table or tables cannot be modified in a way that would affect the view definition.
Box 2: Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Sales.Female.Customers must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Sales.FemaleCustomers.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact_SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
Explanation:
Box 1: WITH SCHEMABINDING:
SCHEMABINDING binds the view to the schema of the underlying table or tables. When SCHEMABINDING is specified, the base table or tables cannot be modified in a way that would affect the view definition.
Box 2: Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Sales.Female.Customers must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Sales.FemaleCustomers.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact_SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
Explanation:
Box 1: WITH SCHEMABINDING:
SCHEMABINDING binds the view to the schema of the underlying table or tables. When SCHEMABINDING is specified, the base table or tables cannot be modified in a way that would affect the view definition.
Box 2: Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Sales.Female.Customers must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Sales.FemaleCustomers.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact_SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
Explanation:
Box 1: WITH SCHEMABINDING:
SCHEMABINDING binds the view to the schema of the underlying table or tables. When SCHEMABINDING is specified, the base table or tables cannot be modified in a way that would affect the view definition.
Box 2: Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Sales.Female.Customers must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Sales.FemaleCustomers.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact_SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
Explanation:
Box 1: WITH SCHEMABINDING:
SCHEMABINDING binds the view to the schema of the underlying table or tables. When SCHEMABINDING is specified, the base table or tables cannot be modified in a way that would affect the view definition.
Box 2: Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Sales.Female.Customers must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary.
The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the spUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
You need to create Sales.FemaleCustomers.
How should you complete the view definition? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact_SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
Explanation:
Box 1: WITH SCHEMABINDING:
SCHEMABINDING binds the view to the schema of the underlying table or tables. When SCHEMABINDING is specified, the base table or tables cannot be modified in a way that would affect the view definition.
Box 2: Box 2: WITH CHECK OPTION
CHECK OPTION forces all data modification statements executed against the view to follow the criteria set within select_statement. When a row is modified through a view, the WITH CHECK OPTION makes sure the data remains visible through the view after the modification is committed.
Note: Sales.Female.Customers must meet the following requirements:
Only allow updates through the views that adhere to the view filter.
You have the following stored procedures: spDeleteCustAcctRelationship and spUpdateCustomerSummary. The spUpdateCustomerSummary stored procedure was created by running the following Transacr-SQL statement:
You run the uspUpdateCustomerSummary stored procedure to make changes to customer account summaries. Other stored procedures call the spDeleteCustAcctRelationship to delete records from the CustomerToAccountBridge table.
When you start uspUpdateCustomerSummary, there are no active transactions. The procedure fails at the second update statement due to a CHECK constraint violation on the TotalDepositAccountCount column.
What is the impact of the stored procedure on the CustomerDetails table?
- A . The value of the TotalAccountCount column decreased.
- B . The value of the TotalDepositAccountCount column is decreased.
- C . The statement that modifies TotalDepositAccountCount is excluded from the transaction.
- D . The value of the TotalAccountCount column is not changed.
Note: This question is part of a series of questions that use the same answer choices. An answer choice may be correct for more than one question on the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You work on an OLTP database that has no memory-optimized file group defined.
You have a table names tblTransaction that is persisted on disk and contains the information described in the following table:
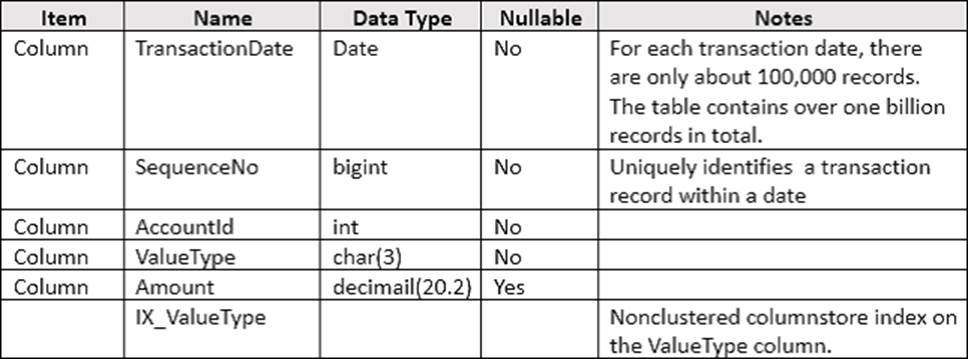

Users report that the following query takes a long time to complete.


You need to create an index that:
– improves the query performance
– does not impact the existing index
– minimizes storage size of the table (inclusive of index pages).
What should you do?
- A . Create aclustered index on the table.
- B . Create a nonclustered index on the table.
- C . Create a nonclustered filtered index on the table.
- D . Create a clustered columnstore index on the table.
- E . Create a nonclustered columnstore index on the table.
- F . Create a hashindex on the table.
C
Explanation:
A filtered index is an optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes.
Note: This question is part of a series of questions that use the same answer choices. An answer choice may be correct for more than one question on the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You work on an OLTP database that has no memory-optimized file group defined.
You have a table names tblTransaction that is persisted on disk and contains the information described in the following table:
Users report that the following query takes a long time to complete.
You need to create an index that:
– improves the query performance
– does not impact the existing index
– minimizes storage size of the table (inclusive of index pages).
What should you do?
- A . Create aclustered index on the table.
- B . Create a nonclustered index on the table.
- C . Create a nonclustered filtered index on the table.
- D . Create a clustered columnstore index on the table.
- E . Create a nonclustered columnstore index on the table.
- F . Create a hashindex on the table.
C
Explanation:
A filtered index is an optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes.
Note: This question is part of a series of questions that use the same answer choices. An answer choice may be correct for more than one question on the series. Each question is independent of the other questions in this series. Information and details provided in a question apply only to that question.
You work on an OLTP database that has no memory-optimized file group defined.
You have a table names tblTransaction that is persisted on disk and contains the information described in the following table:
Users report that the following query takes a long time to complete.
You need to create an index that:
– improves the query performance
– does not impact the existing index
– minimizes storage size of the table (inclusive of index pages).
What should you do?
- A . Create aclustered index on the table.
- B . Create a nonclustered index on the table.
- C . Create a nonclustered filtered index on the table.
- D . Create a clustered columnstore index on the table.
- E . Create a nonclustered columnstore index on the table.
- F . Create a hashindex on the table.
C
Explanation:
A filtered index is an optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes.
FirstName must be added to the index as an included column.
What should you do?
- A . Create a clustered index on the table.
- B . Create a nonclustered index on the table.
- C . Create a nonclustered filtered index on the table.
- D . Create a clustered columnstore index on the table.
- E . Create a nonclustered columnstore index on the table.
- F . Create a hash index on the table.
B
Explanation:
By including nonkey columns, you can create nonclustered indexes that cover more queries.
This is because the nonkeycolumns have the following benefits:
They can be data types not allowed as index key columns. They are not considered by the Database Engine when calculating the number of index key columns or index key size.
Note: The question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other question in the series. Information and details provided in a question apply only to that question.
You have a reporting database that includes a non-partitioned fact table named Fact_Sales. The table is persisted on disk. Users report that their queries take a long time to complete. The system administrator reports that the table takes too much space in the database. You observe that there are no indexes defined on the table, and many columns have repeating values.
You need to create the most efficient index on the table, minimize disk storage and improve reporting query performance.
What should you do?
- A . Create a clustered index on the table.
- B . Create a nonclustered index on the table.
- C . Create a nonclustered filtered index on the table.
- D . Create a clustered columnstore index on the table.
- E . Create a nonclustered columnstore index on the table.
- F . Create a hash index on the table.
D
Explanation:
The columnstore index is the standard for storing and querying largedata warehousing fact tables. It uses column-based data storage and query processing to achieve up to 10x query performance gains in your data warehouse over traditional row-oriented storage, and up to 10x data compression over the uncompressed data size. A clustered columnstore index is the physical storage for the entire table.
Note: The question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other question in the series. Information and details provided in a question apply only to that question.
You have a database named DB1. The database does not use a memory-optimized filegroup. The database contains a table named Table1.
The table must support the following workloads:


You need to add the most efficient index to support the new OLTP workload, while not deteriorating the existing Reporting query performance.
What should you do?
- A . Create a clustered index on the table.
- B . Create a nonclustered index on the table.
- C . Create a nonclustered filtered index on the table.
- D . Create a clustered columnstore index on the table.
- E . Create a nonclustered columnstore index on the table.
- F . Create a hash index on the table.
C
Explanation:
A filtered index is an optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes.
References: https://technet.microsoft.com/en-us/library/cc280372(v=sql.105).aspx
Note: The question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other question in the series. Information and details provided in a question apply only to that question.
You have a database named DB1. The database does not have a memory optimized filegroup.
You create a table by running the following Transact-SQL statement:
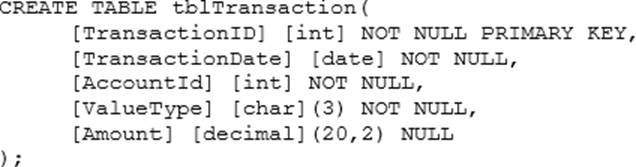

The table is currently used for OLTP workloads. The analytics user group needs to perform real-time operational analytics that scan most of the records in the table to aggregate on a number of columns. You need to add the most efficient index to support the analytics workload without changing the OLTP application.
What should you do?
- A . Create a clustered indexon the table.
- B . Create a nonclustered index on the table.
- C . Create a nonclustered filtered index on the table.
- D . Create a clustered columnstore index on the table.
- E . Create a nonclustered columnstore index on the table.
- F . Create a hash index on the table.
E
Explanation:
A nonclustered columnstore index enables real-time operational analytics in which the OLTP workload uses the underlying clustered index, while analytics run concurrently on the columnstore index.
Columnstore indexes can achieve up to 100xbetter performance on analytics and data warehousing workloads and up to 10x better data compression than traditional rowstore indexes. These recommendations will help your queries achieve the very fast query performance that columnstore indexes are designed to provide.
References: https://msdn.microsoft.com/en-us/library/gg492088.aspx
DRAG DROP
You are analyzing the performance of a database environment.
You suspect there are several missing indexes in the current database.
You need to return a prioritized list of the missing indexes on the current database.
How should you complete the Transact-SQL statement? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact-SQL segment may be used once, more than once or not at all. You may need to drag the split bar between panes or scroll to view content.
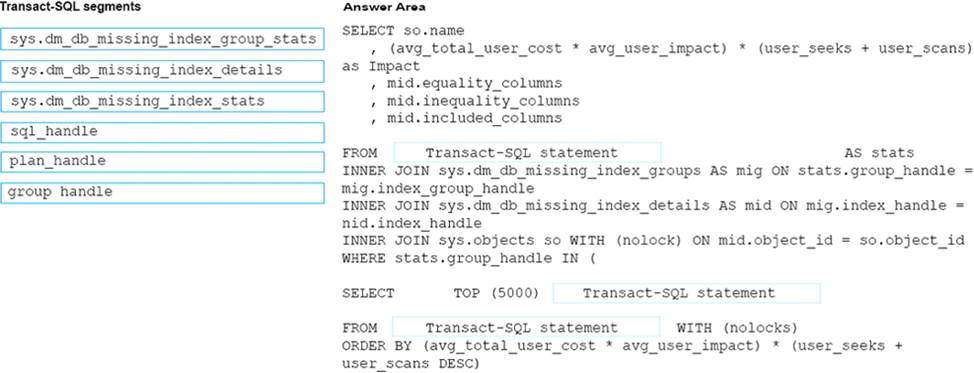

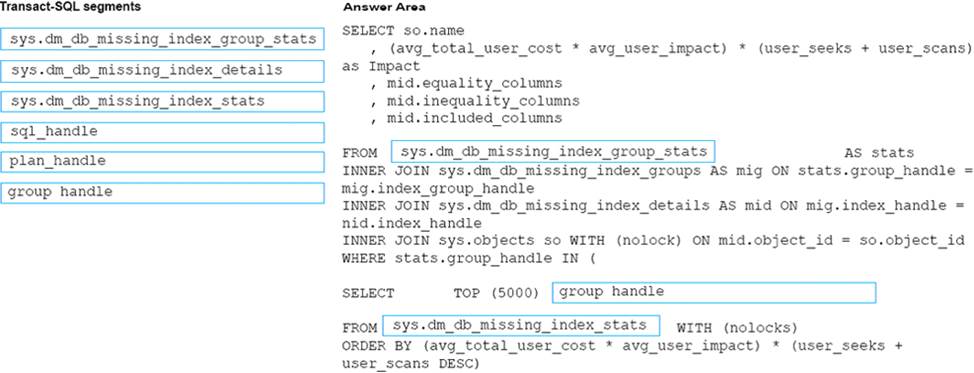
Explanation:
Box 1: sys.db_db_missing_index_group_stats
Box 2: group_handle
Example: The following query determines which missing indexes comprise a particular missing index group, and displays their column details. For the sake of this example, the missing index group handle is 24.
SELECT migs.group_handle, mid.*
FROM sys.dm_db_missing_index_group_stats AS migs
INNER JOIN sys.dm_db_missing_index_groups AS mig
ON (migs.group_handle = mig.index_group_handle)
INNER JOIN sys.dm_db_missing_index_details AS mid
ON (mig.index_handle = mid.index_handle)
WHERE migs.group_handle = 24;
Box 3: sys.db_db_missing_index_group_stats
The sys.db_db_missing_index_group_stats table include the required columns for the subquery: avg_total_user_cost and avg_user_impact.
Example: Find the 10 missing indexes with the highest anticipated improvement for user queries
The following query determines which 10 missing indexes would produce the highest anticipated cumulative improvement, in descending order, for user queries.
SELECT TOP 10 *
FROM sys.dm_db_missing_index_group_stats
ORDER BY avg_total_user_cost * avg_user_impact * (user_seeks + user_scans)DESC;
DRAG DROP
You are monitoring a Microsoft Azure SQL Database. The database is experiencing high CPU consumption. You need to determine which query uses the most cumulative CPU.
How should you complete the Transact-SQL statement? To answer, drag the appropriate Transact-SQL segments to the correct locations. Each Transact-SQL segment may be used once, more than one or not at all. You may need to drag the split bar between panes or scroll to view content.
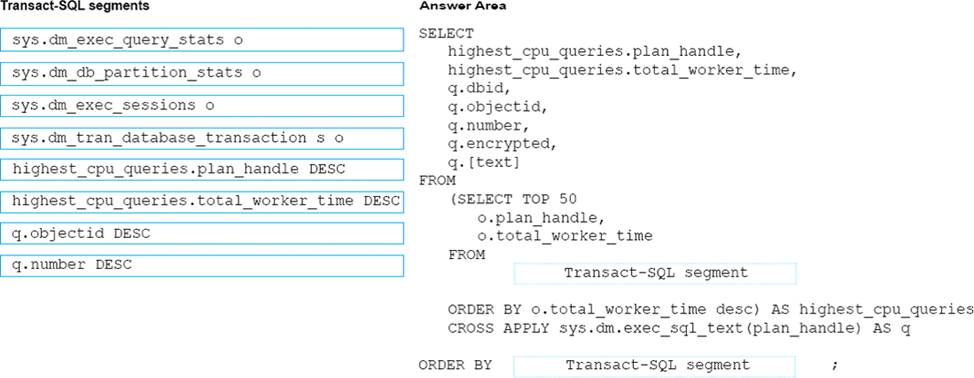

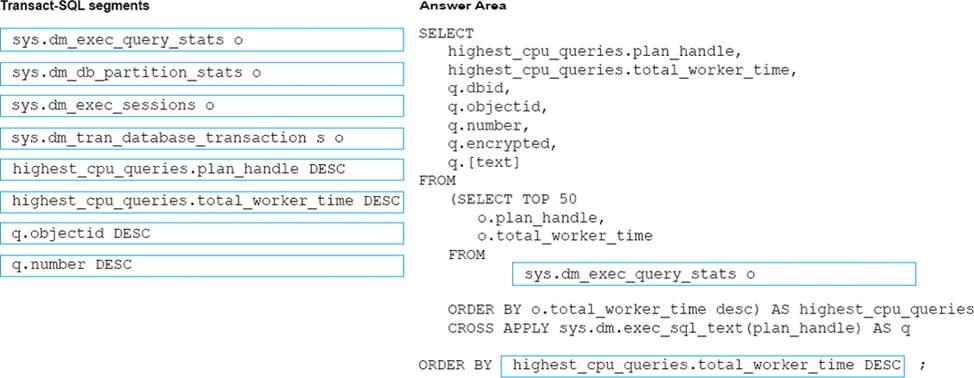
Explanation:
Box 1: sys.dm_exec_query_stats
sys.dm_exec_query_stats returns aggregateperformance statistics for cached query plans in SQL Server.
Box 2: highest_cpu_queries.total_worker_time DESC
Sort on total_worker_time column
Example: The following example returns information about the top five queries ranked by average CPU time.
Thisexample aggregates the queries according to their query hash so that logically equivalentqueries are grouped by their cumulative resource consumption.
USE AdventureWorks2012;
GO
SELECT TOP 5 query_stats.query_hash AS "Query Hash",
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS "Avg CPU Time",
MIN(query_stats.statement_text) AS "Statement Text"
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
– QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle)as ST) as query_stats
GROUP BY query_stats.query_hash
ORDER BY 2 DESC;
References: https://msdn.microsoft.com/en-us/library/ms189741.aspx
DRAG DROP
You are analyzing the memory usage of a Microsoft SQL Server instance.
You need to obtain the information described on the following table.


Which performance counter should you use for each requirement? To answer, drag the appropriate performance counters to the correct requirements. Each performance counter may be used once, more than once or not at all. You may need to drag the split bat between panes or scroll to view content.
NOTE: Each correct selection is worth one point.


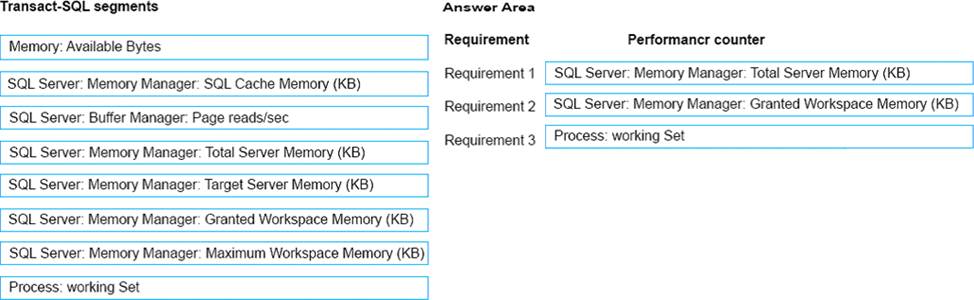
Explanation:
Requirement1: SQL Server: Memory Manager: Total Server Memory (KB)
This counter specifies theamount of memory the server has committed using the memory manager.
Requirement2: SQL Server: Memory Manager: Granted Workspace Memory (KB)
Specifies the total amount of memory currently granted to executing processes, such as hash, sort, bulk copy, andindex creation operations.
Requirement3: Process: working Set
Each time a process is created, it reserves the minimum working set size for the process. The virtual memory manager attempts to keep enough memory for the minimum working set resident when the process is active, but keeps no more than the maximum size.
References:
https://msdn.microsoft.com/en-us/library/ms190924.aspx
https://blogs.technet.microsoft.com/askperf/2007/05/18/sql-and-the-working-set/
You use Microsoft SQL Server Profile to evaluate a query named Query1.
The Profiler report indicates the following issues:
– At each level of the query plan, a low total number of rows are processed.
– The query uses many operations. This results in a high overall cost for the query.
You need to identify the information that will be useful for the optimizer.
What should you do?
- A . Start a SQL Server Profiler trace for the event class Auto Stats in the Performance event category.
- B . Create one Extended Events session with the sqlserver.missing_column_statistics event added.
- C . Start a SQL Server Profiler trace for the event class Soft Warnings in the Errors and Warnings event category.
- D . Create one Extended Events session with the sqlserver.missing_join_predicate event added.
D
Explanation:
The Missing Join Predicate event class indicates that a query is being executed that has no join predicate. This could result in a long-running query.
You are experiencing performance issues with the database server. You need to evaluate schema locking issues, plan cache memory pressure points, and backup I/O problems.
What should you create?
- A . a System Monitor report
- B . a sys.dm_exec_query_stats dynamic management view query
- C . a sys.dm_exec_session_wait_stats dynamicmanagement view query
- D . an Activity Monitor session in Microsoft SQL Management Studio.
C
Explanation:
sys.dm_exec_session_wait_stats returns information about all the waits encountered by threads that executed for each session. You can use this view to diagnose performance issues with the SQL Server session and also with specific queries and batches.
Note: SQL Server wait stats are, at their highest conceptual level, grouped into two broad categories: signal waits and resource waits. A signal wait is accumulated by processes running on SQL Server which are waiting for a CPU to become available (so called because the process has “signaled” that it is ready for processing). A resource wait is accumulated by processes running on SQL Server which are waiting fora specific resource to become available, such as waiting for the release of a lock on a specific record.
HOTSPOT
You are maintaining statistics for a database table named tblTransaction. The table contains more than 10 million records.
You need to create a stored procedure that meets the following requirements:
– On weekdays, update statistics for a sample of the total number of records in the table.
– On weekends, update statistics by sampling all rows in the table.
A maintenance task will call this stored procedure daily.
How should you complete the stored procedure? To answer, select the appropriate Transact-SQL segments in the answer area. NOTE: Each correct selection is worth one point.
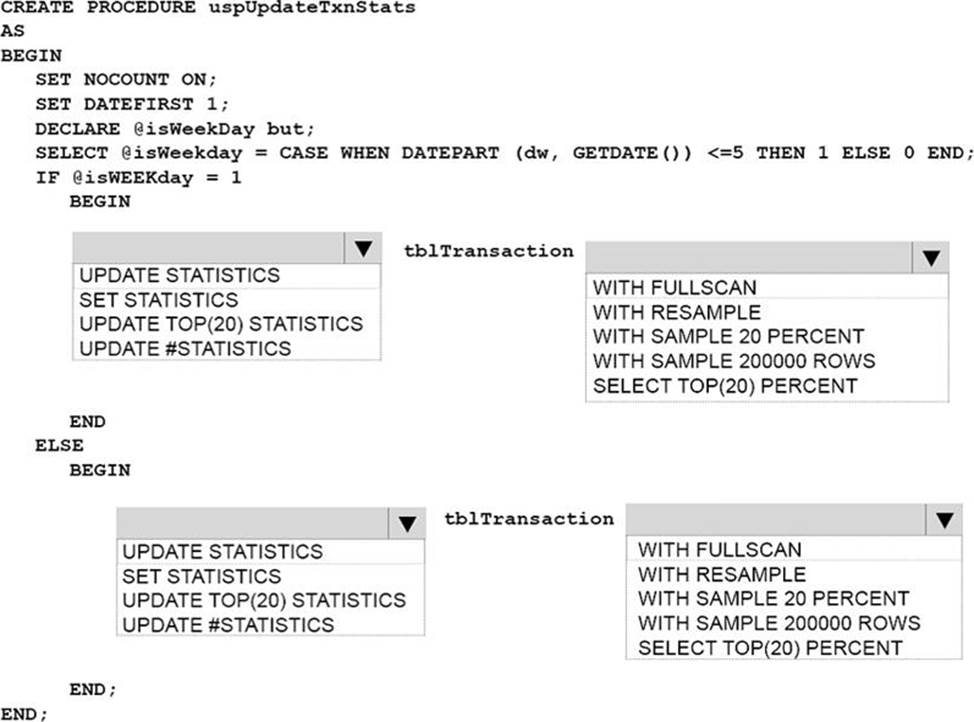


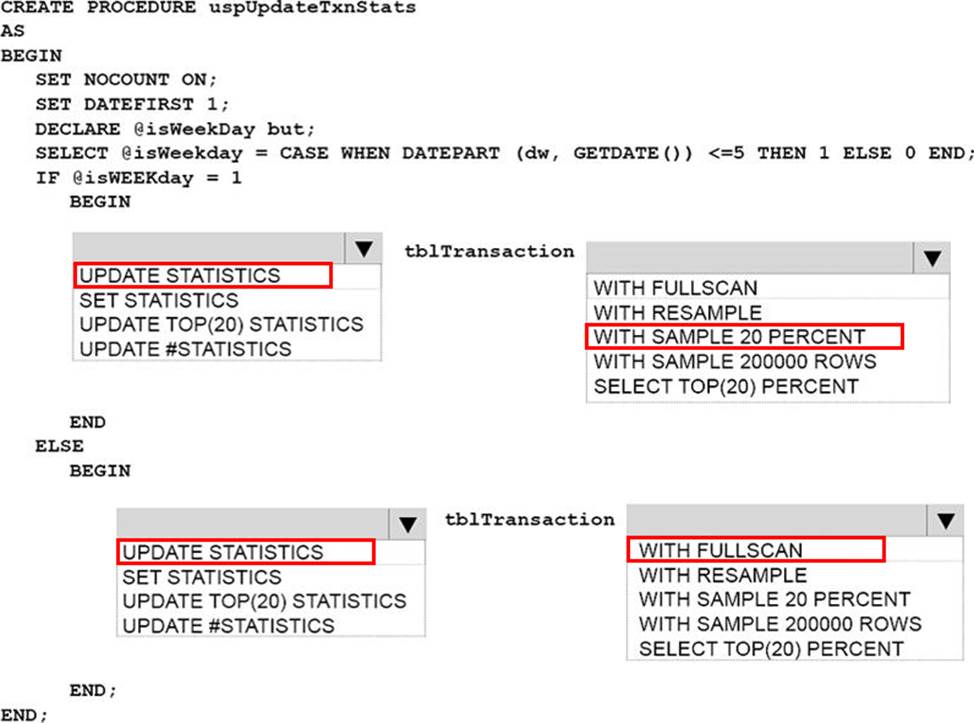
Explanation:
Box 1: UPDATE STATISTICS
Box 2: SAMPLE 20 PERCENT
UPDATE STATISTICS tablenameSAMPLE number { PERCENT | ROWS }
Specifies the approximate percentage or number of rows in the table or indexed view for the query optimizer to use when it updates statistics. For PERCENT, number can be from 0 through 100 and for ROWS, number can be from0 to the total number of rows.
Box 3: UPDATE STATISTICS
Box 4: WITH FULLSCAN
FULLSCAN computes statistics by scanning all rows in the table or indexed view. FULLSCAN and SAMPLE 100 PERCENT have the same results. FULLSCAN cannot be used with the SAMPLE option.
References: https://msdn.microsoft.com/en-us/library/ms187348.aspx
DRAG DROP
You have a database named MyDatabase. You must monitor all the execution plans in XML format by using Microsoft SQL Trace.
The trace must meet the following requirements:
– Capture execution plans only for queries that run the MyDatabase database.
– Filter out plans with event duration of less than or equal to 100 microseconds.
– Save trace results to a disk on the server.
You need to create the trace.
In which order should you arrange the Transact-SQL segments to develop the solution? To answer, move all Transact-SQL segments to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.


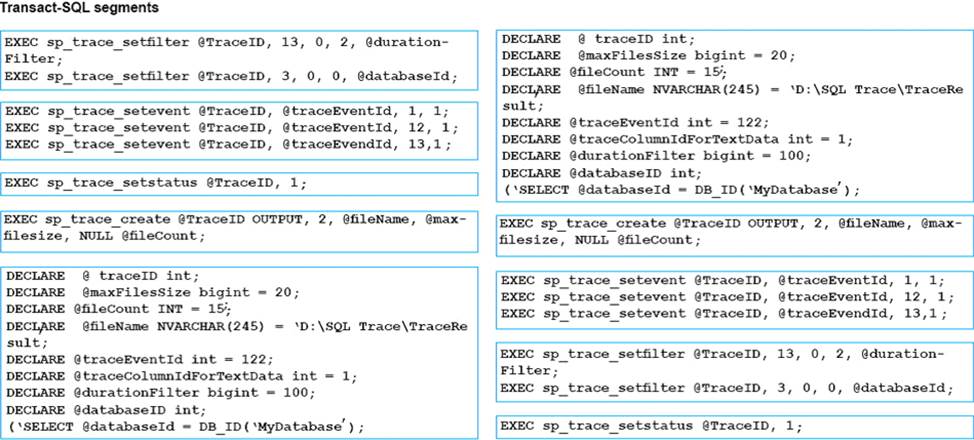
Explanation:
The following system stored procedures are used to define and manage traces:
* sp_trace_create is used to define a trace and specify an output file location as well asother options that I’ll cover in the coming pages. This stored procedure returns a handle to the created trace, in the form of an integer trace ID.
* sp_trace_setevent is used to add event/column combinations to traces based on the trace ID, as well as toremove them, if necessary, from traces in which they have already been defined.
* sp_trace_setfilter is used to define event filters based on trace columns.
* sp_trace_setstatus is called to turn on a trace, to stop a trace, and to delete a trace definitiononce you’re done with it. Traces can be started and stopped multiple times over their lifespan.
References: https://msdn.microsoft.com/en-us/library/cc293613.aspx
HOTSPOT
You are analyzing the performance of a database environment. You need to find all unused indexes in the current database.
How should you complete the Transact-SQL statement? To answer, select the appropriate Transact-SQL
segments in the answer area.

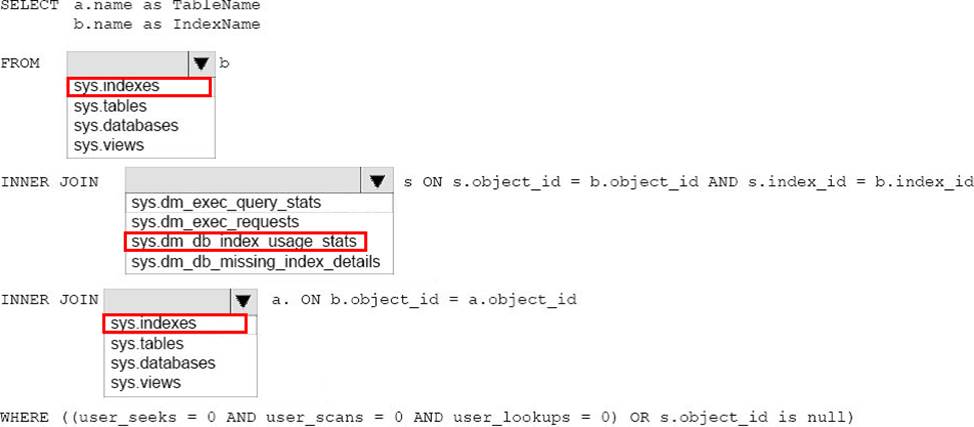
Explanation:
Example: Following query helps you to find all unused indexes within database using sys.dm_db_index_usage_stats DMV.
— Ensure a USE statement has been executed first.
SELECT u.*
FROM [sys].[indexes] i
INNER JOIN [sys].[objects] o ON (i.OBJECT_ID = o.OBJECT_ID)
LEFT JOIN [sys].[dm_db_index_usage_stats] u ON (i.OBJECT_ID = u.OBJECT_ID)
AND i.[index_id] = u.[index_id]
AND u.[database_id] = DB_ID() –returning the database ID of the current database
WHERE o.[type] <> ‘S’ –shouldn’t be a system base table
AND i.[type_desc] <> ‘HEAP’
AND i.[name] NOT LIKE ‘PK_%’
AND u.[user_seeks] + u.[user_scans] + u.[user_lookups] = 0
AND u.[last_system_scan] IS NOT NULL
ORDER BY 1 ASC
References: https://basitaalishan.com/2012/06/15/find-unused-indexes-using-sys-dm_db_index_usage_stats/
HOTSPOT
You are reviewing the execution plans in the query plan cache.
You observe the following:
– There are a large number of single use plans.
– There are a large number of simple execution plans that use multiple CPU cores.
You need to configure the server to optimize query plan execution.
Which two setting should you modify on the properties page for the Microsoft SQL Server instance? To answer, select the appropriate settings in the answer area.
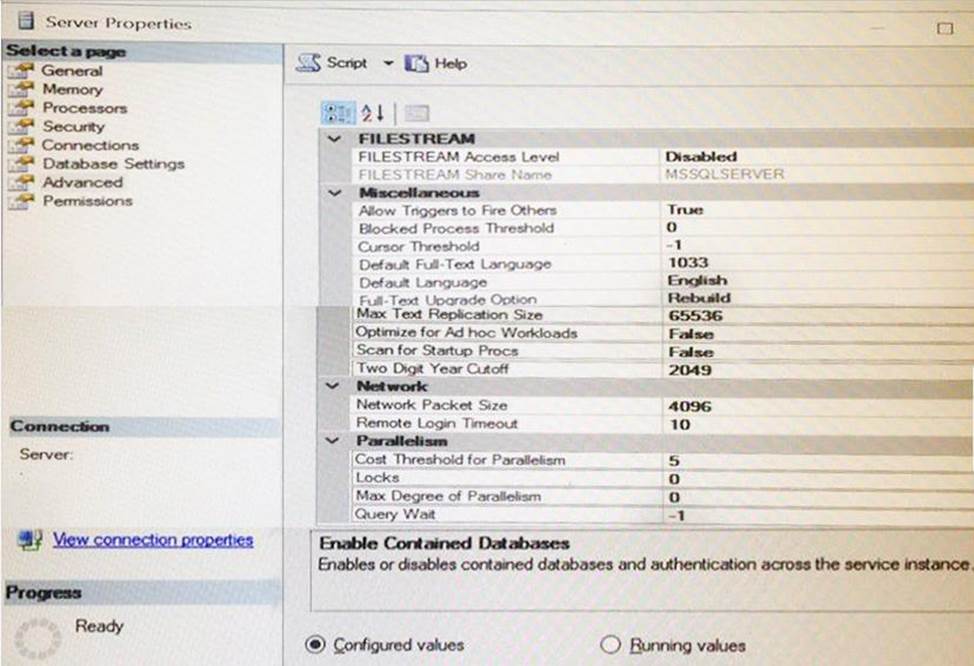


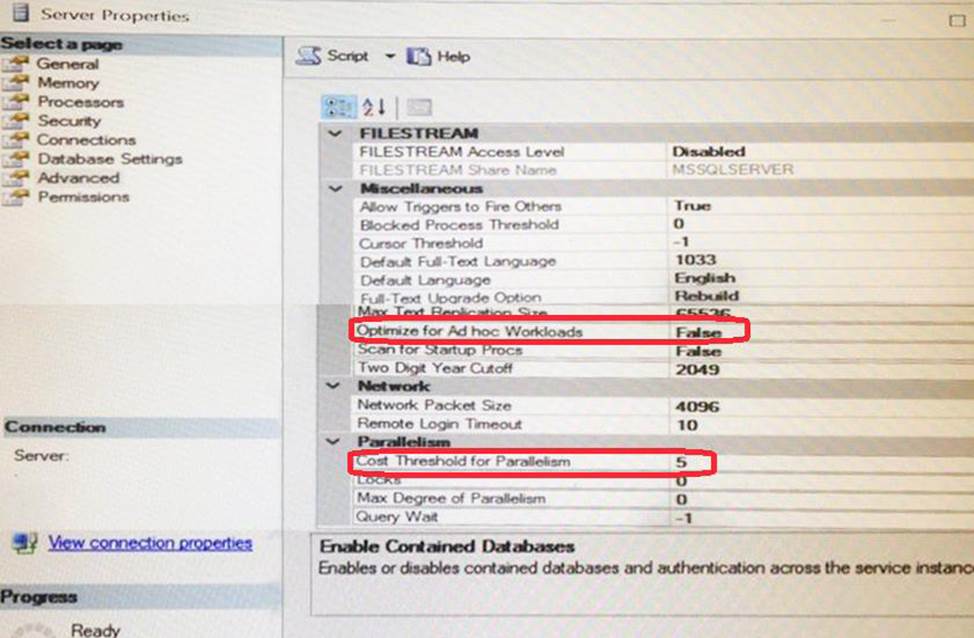
Explanation:
* Optimize for ad hoc workloads
The optimize for ad hoc workloads option is used to improve the efficiency of the plan cache for workloads that contain many single use ad hoc batches. When this option is set to 1, the Database Engine stores a small compiled plan stub in the plan cache when a batch is compiled for the first time, instead of the full compiled plan. This helps to relieve memory pressure by not allowing the plan cache to become filled with compiled plans that are not reused.
* Cost Threshold for Parallelism
Use the cost threshold for parallelism option to specify the threshold at which Microsoft SQL Server creates and runs parallel plans for queries. SQL Server creates and runs a parallel plan for a query only when the estimated cost to run a serial plan for the same query is higher than the value set in cost threshold for parallelism. The cost refers to an estimated elapsed time in seconds required to run the serial plan on a specific hardware configuration.
5 means 5 seconds, but is is 5 seconds on a machine internal to Microsoft from some time in the 1990s. There’s no way to relate it to execution time on your current machine, so we treat it as a pure number now. Raising it to 50 is a common suggestion nowadays, so that more of your simpler queries run on a single thread.
Note: this question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in the series. Information and details provided in a question apply only to that question.
You are developing an application to track customer sales.
You need to create a database object that meets the following requirements:
– Return a value of 0 if data inserted successfully into the Customers table.
– Return a value of 1 if data is not inserted successfully into the Customers table.
– Support logic that is written by using managed code.
What should you create?
- A . extended procedure
- B . CLR procedure
- C . user-defined procedure
- D . DML trigger
- E . DDL trigger
- F . scalar-valued function
- G . table-valued function
B
Explanation:
DML triggers is a special type of stored procedure that automatically takes effect when a data manipulation language (DML) event takes place that affects the table or view defined in the trigger. DML events include INSERT, UPDATE, or DELETE statements.DML triggers can be used to enforce business rules and data integrity, query other tables, and include complex Transact-SQL statements.
A CLR trigger is a type of DDL trigger. A CLR Trigger can be either an AFTER or INSTEAD OF trigger. A CLR trigger canalso be a DDL trigger. Instead of executing a Transact-SQL stored procedure, a CLR trigger executes one or more methods written in managed code that are members of an assembly created in the .NET Framework and uploaded in SQL Server.
References: https://msdn.microsoft.com/en-us/library/ms178110.aspx
Note: this question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in the series. Information and details provided in a question apply only to that question.
You are developing an application to track customer sales.
You need to create a database object that meets the following requirements:
– Return a value of 0 if data inserted successfully into the Customers table.
– Return a value of 1 if data is not inserted successfully into the Customers table.
– Support TRY…CATCH error handling
– Be written by using Transact-SQL statements.
What should you create?
- A . extended procedure
- B . CLR procedure
- C . user-defined procedure
- D . DML trigger
- E . scalar-valued function
- F . table-valued function
D
Explanation:
DML triggers is a special type of stored procedure that automatically takes effect when a data manipulation language (DML) event takes place that affects the table or view defined in the trigger. DML events include INSERT, UPDATE, or DELETE statements. DML triggers can be usedto enforce business rules and data integrity, query other tables, and include complex Transact-SQL statements.
References: https://msdn.microsoft.com/en-us/library/ms178110.aspx
Note: this question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in the series. Information and details provided in a question apply only to that question.
You are developing an application to track customer sales.
You need to create a database object that meets the following requirements:
– Launch when table data is modified.
– Evaluate the state a table before and after a data modification and take action based on the difference.
– Prevent malicious or incorrect table data operations.
– Prevent changes that violate referential integrity by cancelling the attempted data modification.
– Run managed code packaged in an assembly that is created in the Microsoft.NET Framework and located into Microsoft SQL Server.
What should you create?
- A . extended procedure
- B . CLR procedure
- C . user-defined procedure
- D . DML trigger
- E . scalar-valued function
- F . table-valued function
B
Explanation:
You can create a database object inside SQL Server that is programmed in an assembly created in the Microsoft .NET Framework common language runtime (CLR). Database objects that can leverage the rich programmingmodel provided by the CLR include DML triggers, DDL triggers, stored procedures, functions, aggregate functions, and types.
Creating a CLR trigger (DML or DDL) in SQL Server involves the following steps:
Define the trigger as a class in a .NETFramework-supported language. For more information about how to program triggers in the CLR, see CLR Triggers. Then, compile the class to build an assembly in the .NET Framework using the appropriate language compiler.
Register the assembly in SQL Server using the CREATE ASSEMBLY statement. For more information about assemblies in SQL Server, see Assemblies (Database Engine).
Create the trigger that references the registered assembly.
References: https://msdn.microsoft.com/en-us/library/ms179562.aspx
Note: this question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in the series. Information and details provided in a question apply only to that question.
You are developing and application to track customer sales.
You need to return the sum of orders that have been finalized, given a specified order identifier. This value will be used in other Transact-SQL statements. You need to create a database object.
What should you create?
- A . extended procedure
- B . CLR procedure
- C . user-defined procedure
- D . DML trigger
- E . scalar-valued function
- F . table-valued function
F
Explanation:
User-defined scalar functions return a single data value of the type defined in the RETURNS clause.
References: https://technet.microsoft.com/en-us/library/ms177499(v=sql.105).aspx
Note: this question is part of a series of questions that use the same or similar answer choices. An answer choice may be correct for more than one question in the series. Each question is independent of the other questions in the series. Information and details provided in a question apply only to that question.
You are developing and application to track customer sales.
You need to create an object that meet the following requirements:
– Run managed code packaged in an assembly that was created in the Microsoft.NET Framework and uploaded in Microsoft SQL Server.
– Run written a transaction and roll back if a future occurs.
– Run when a table is created or modified.
What should you create?
- A . extended procedure
- B . CLR procedure
- C . user-defined procedure
- D . DML trigger
- E . scalar-valued function
- F . table-valued function
B
Explanation:
The common language runtime (CLR) is the heart of the Microsoft .NET Framework andprovides the execution environment for all .NET Framework code. Code that runs within the CLR is referred to as managed code.
With the CLR hosted in Microsoft SQL Server (called CLR integration), you can author stored procedures,
triggers, user-defined functions, user-defined types, and user-defined aggregates in managed code. Because managed code compiles to native code prior to execution, you can achieve significant performance increases in some scenarios.
You have a view that includes an aggregate.
You must be able to change the values of columns in the view. The changes must be reflected in the tables that the view uses. You need to ensure that you can update the view.
What should you create?
- A . table-valued function
- B . a schema-bound view
- C . a partitioned view
- D . a DML trigger
B
Explanation:
When you use the SchemaBinding keyword while creating a view or function you bind the structure of any underlying tables or views. Itmeans that as long as that schemabound object exists as a schemabound object (ie you don’t remove schemabinding) you are limited in changes that can be made to the tables or views that it refers to.
References: https://sqlstudies.com/2014/08/06/schemabinding-what-why/
DRAG DROP
You are creating a stored procedure which will insert data into the table shown in the Database schema exhibit. (Click the exhibit button.)
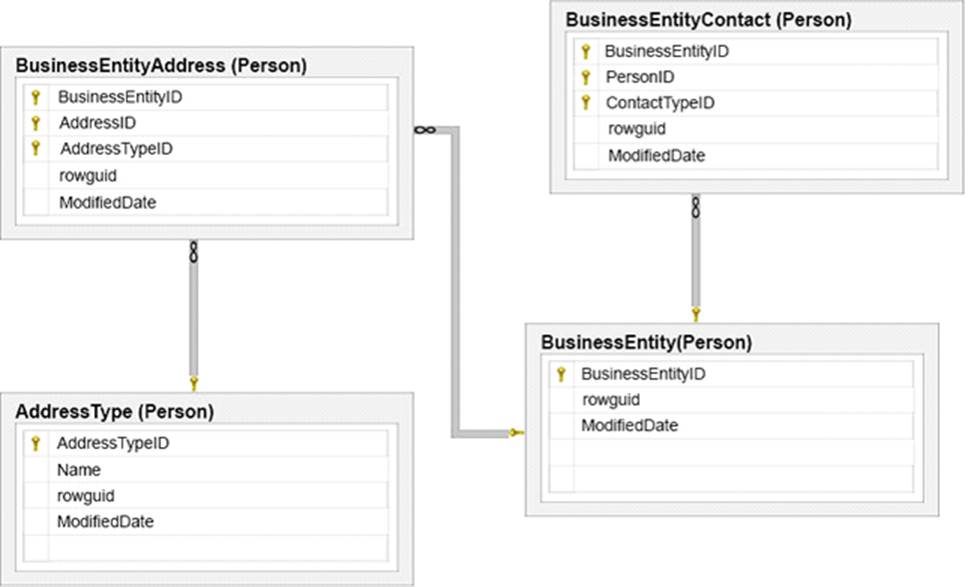

You need to insert a new customer record into the tables as a single unit of work.
Which five Transact-SQL segments should you use to develop the solution? To answer, move the appropriate Transact-SQL segments to the answer area and arrange the, in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
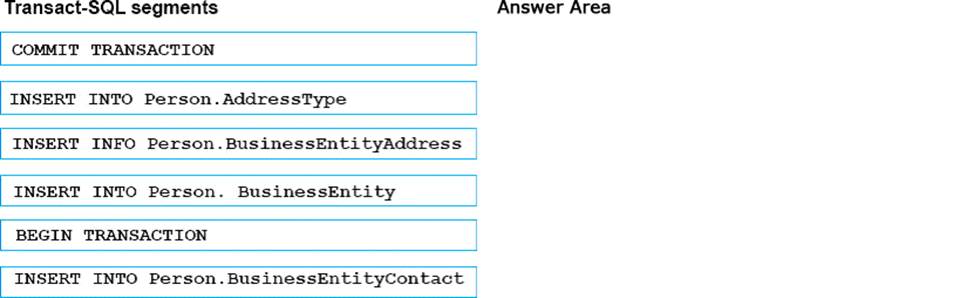


Explanation:
The entities on the many side, of the 1-many relations, must be added before we add the entities on the 1side.
We must insert new rows into BusinessEntityContact and BusinessEntityAddress tables, before we insert the corresponding rows into the BusinessEntity and AddressType tables.
Note: This question is part of a series of questions that use the same or similar answer choices. An Answer choice may be correct for more than one question in the series. Each question independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database developer for a company. The company has a server that has multiple physical disks. The disks are not part of a RAID array. The server hosts three Microsoft SQL Server instances. There are many SQL jobs that run during off-peak hours. You must monitor and optimize the SQL Server to maximize throughput, response time, and overall SQL performance. You need to identify previous situations where a modification has prevented queries from selecting data in tables.
What should you do?
- A . Create a sys.dm_os_waiting_tasks query.
- B . Create a sys.dm_exec_sessions query.
- C . Create a Performance Monitor Data Collector Set.
- D . Create a sys.dm_os_memory_objects query.
- E . Create a sp_configure ‘max server memory’ query.
- F . Create a SQL Profiler trace.
- G . Create a sys.dm_os_wait_stats query.
- H . Create an Extended Event.
G
Explanation:
sys.dm_os_wait_stats returns information about all the waits encountered by threads that executed. You can use this aggregated view to diagnose performance issues with SQL Server and also with specific queries and batches.
Note: This question is part of a series of questions that use the same or similar answer choices. AnAnswer choice may be correct for more than one question in the series. Each question independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database developer for a company. The company has a server that has multiple physical disks. The disks are not part of a RAID array. The server hosts three Microsoft SQL Server instances. There are many SQL jobs that run during off-peak hours.
You observe that many deadlocks appear to be happening during specific times of the day.
You need to monitor the SQL environment and capture the information about the processes that are causing the deadlocks. Captured information must be viewable as the queries are running.
What should you do?
- A . A. Create a sys.dm_os_waiting_tasks query.
- B . Create a sys.dm_exec_sessions query.
- C . Create a PerformanceMonitor Data Collector Set.
- D . Create a sys.dm_os_memory_objects query.
- E . Create a sp_configure ‘max server memory’ query.
- F . Create a SQL Profiler trace.
- G . Create a sys.dm_os_wait_stats query.
- H . Create an Extended Event.
F
Explanation:
To view deadlock information, the Database Engine provides monitoring tools in the form of two trace flags, and the deadlock graph event in SQL Server Profiler.
Trace Flag 1204 and Trace Flag 1222
When deadlocks occur, trace flag 1204 and trace flag 1222 return information that is captured in the SQL Server error log. Trace flag 1204 reports deadlock information formatted by each nodeinvolved in the deadlock. Trace flag 1222 formats deadlock information, first by processes and then by resources. It is possible to enable bothtrace flags to obtain two representations of the same deadlock event.
References: https://technet.microsoft.com/en-us/library/ms178104(v=sql.105).aspx
Note: This question is part of a series of questions that use the same or similar answer choices. An Answer choice may be correct for more than one question in the series. Each question independent of the other questions in this series. Information and details provided in a question apply only to that question.
You are a database developer for a company. The company has a server that has multiple physical disks. The disks are not part of a RAID array. The server hosts three Microsoft SQL Server instances. There are many SQL jobs that run during off-peak hours.
You must monitor the SQL Server instances in real time and optimize the server to maximize throughput, response time, and overall SQL performance.
What should you do?
- A . A. Create asys.dm_os_waiting_tasks query.
- B . Create a sys.dm_exec_sessions query.
- C . Create a Performance Monitor Data Collector Set.
- D . Create a sys.dm_os_memory_objects query.
- E . Create a sp_configure ‘max server memory’ query.
- F . Create a SQL Profiler trace.
- G . Create a sys.dm_os_wait_stats query.
- H . Create an Extended Event.
B
Explanation:
sys.dm_exec_sessions returns one row per authenticated session on SQL Server. sys.dm_exec_sessions is a server-scope view that shows information about all active user connections and internal tasks. This information includes client version, client program name, client login time, login user, current session setting, and more. Use sys.dm_exec_sessions to first view the current system load and to identify a session of interest, and then learn more information about that session by using other dynamic management views or dynamic management functions.
Examples of use include finding long-running cursors, and finding idle sessions that have open transactions.