DRAG DROP
Note: This question is part of a series of questions that use the same scenario. For your convenience, the scenario is repeated in each question. Each question presents a different goal and answer choices, but the text of the scenario is exactly the same in each question in this series.
You have five servers that run Microsoft Windows 2012 R2. Each server hosts a Microsoft SQL Server instance. The topology for the environment is shown in the following diagram.
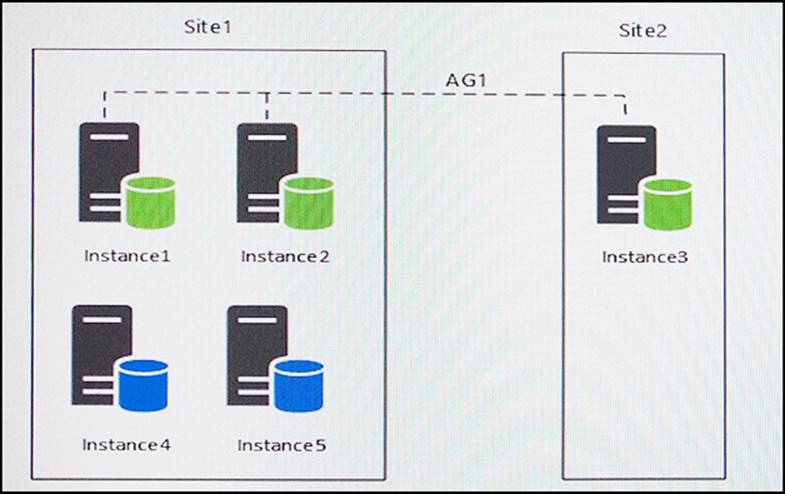
You have an Always On Availability group named AG1.
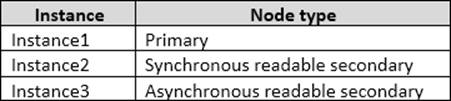
The details for AG1 are shown in the following table.
Instance1 experiences heavy read-write traffic. The instance hosts a database named OperationsMain that is four terabytes (TB) in size. The database has multiple data files and filegroups. One of the filegroups is read_only and is half of the total database size.
Instance4 and Instance5 are not part of AG1. Instance4 is engaged in heavy read-write I/O.
Instance5 hosts a database named StagedExternal. A nightly BULK INSERT process loads data into an empty table that has a rowstore clustered index and two nonclustered rowstore indexes.
You must minimize the growth of the StagedExternal database log file during the BULK INSERT operations and perform point-in-time recovery after the BULK INSERT transaction. Changes made must not interrupt the log backup chain.
You plan to add a new instance named Instance6 to a datacenter that is geographically distant from Site1 and Site2. You must minimize latency between the nodes in AG1.
All databases use the full recovery model. All backups are written to the network location \SQLBackup. A separate process copies backups to an offsite location. You should minimize both the time required to restore the databases and the space required to store backups.
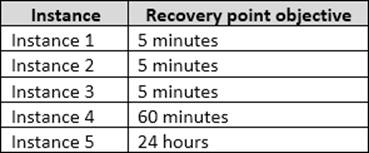
The recovery point objective (RPO) for each instance is shown in the following table.
Full backups of OperationsMain take longer than six hours to complete. All SQL Server backups
use the keyword COMPRESSION.
You plan to deploy the following solutions to the environment. The solutions will access a database named DB1 that is part of AG1.
-Reporting system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader role. The user has EXECUTE permissions on the database. Queries make no changes to the data. The queries must be load balanced over variable read-only replicas.
-Operations system: This solution accesses data inDB1with a login that is mapped to a database user that is a member of the db_datareader and db_datawriter roles. The user has EXECUTE permissions on the database. Queries from the operations system will perform both DDL and DML operations.
The wait statistics monitoring requirements for the instances are described in the following table.

You need to configure a new replica of AG1 on Instance6.
How should you complete the Transact-SQL statement? To answer, drag the appropriate Transact-SQL statements to the correct locations. Each Transact-SQL segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
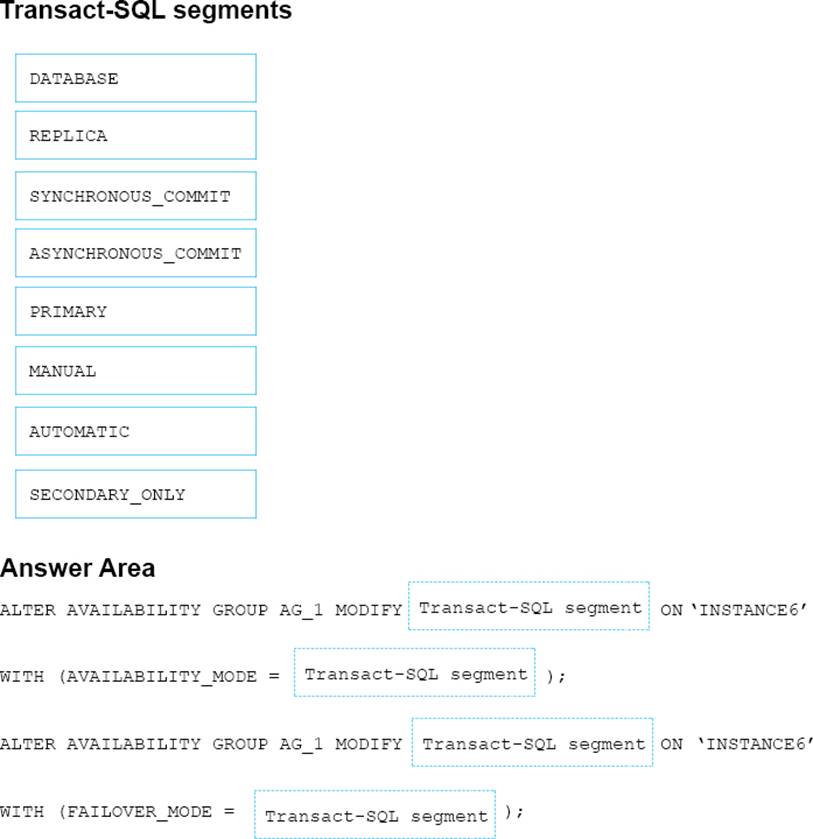
Answer: 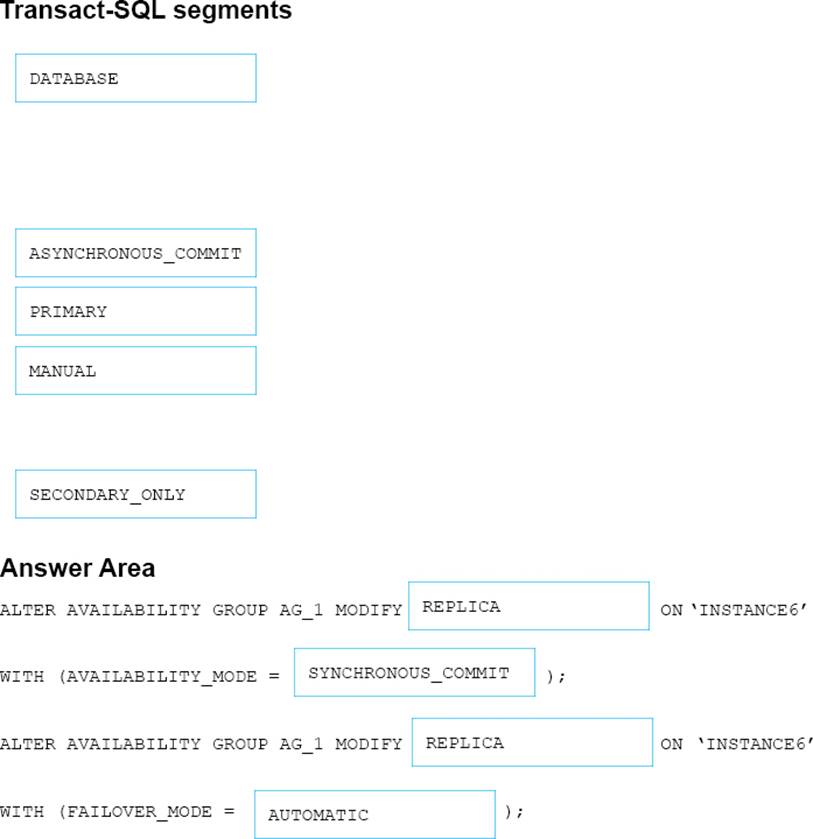
Explanation:
Scenario: You plan to add a new instance named Instance6 to a datacenter that is geographically distant from Site1 and Site2. You must minimize latency between the nodes in AG1.
Box 1: REPLICA
MODIFY REPLICA ON modifies any of the replicas ofthe availability group.
Box 2: SYNCHRONOUS_COMMIT
You must minimize latency between the nodes in AG1
AVAILABILITY_MODE = {SYNCHRONOUS_COMMIT | ASYNCHRONOUS_COMMIT}
Specifies whether the primary replica has to wait for the secondary availability group to acknowledge the hardening (writing) of the log records to disk before the primary replica can commit the transaction on a given primary database.
FAILOVER AUTOMATIC (box 4) requires SYNCHRONOUS_COMMIT
Box 3: REPLICA
MODIFY REPLICA ON modifies any of the replicas of the availability group.
Box 4: AUTOMATIC
You must minimize latency between the nodes in AG1
FAILOVER_MODE = {AUTOMATIC | MANUAL}
Specifies the failover mode of the availability replica that you are defining.
FAILOVER_MODE is required in the ADD REPLICA ON clause and optional in the MODIFY REPLICA ON clause.
AUTOMATIC enables automatic failover. AUTOMATIC is supported only if you also specify AVAILABILITY_MODE = SYNCHRONOUS_COMMIT.
References: https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-availability-group-transact-sql
Latest 70-764 Dumps Valid Version with 451 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
