HOTSPOT
Your Azure Machine Learning workspace has a dataset named real_estate_data.
A sample of the data in the dataset follows.

You want to use automated machine learning to find the best regression model for predicting the price column.
You need to configure an automated machine learning experiment using the Azure Machine Learning SDK.
How should you complete the code? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point.
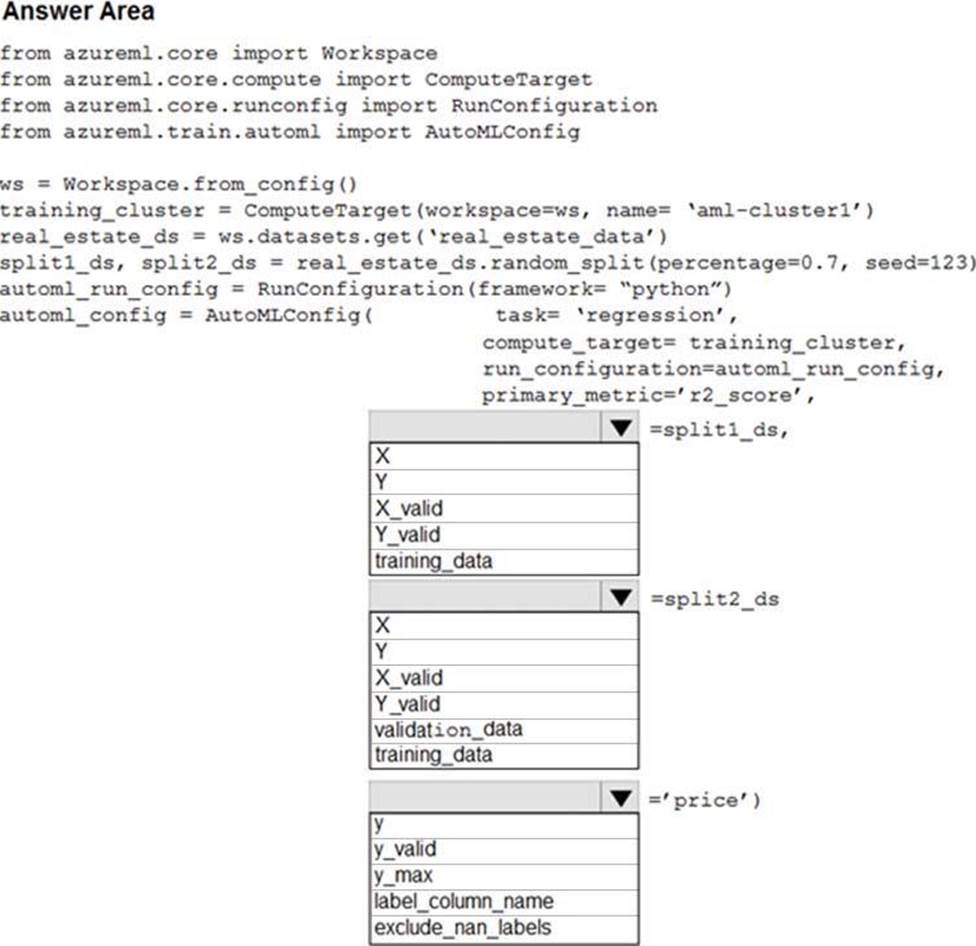
Answer: 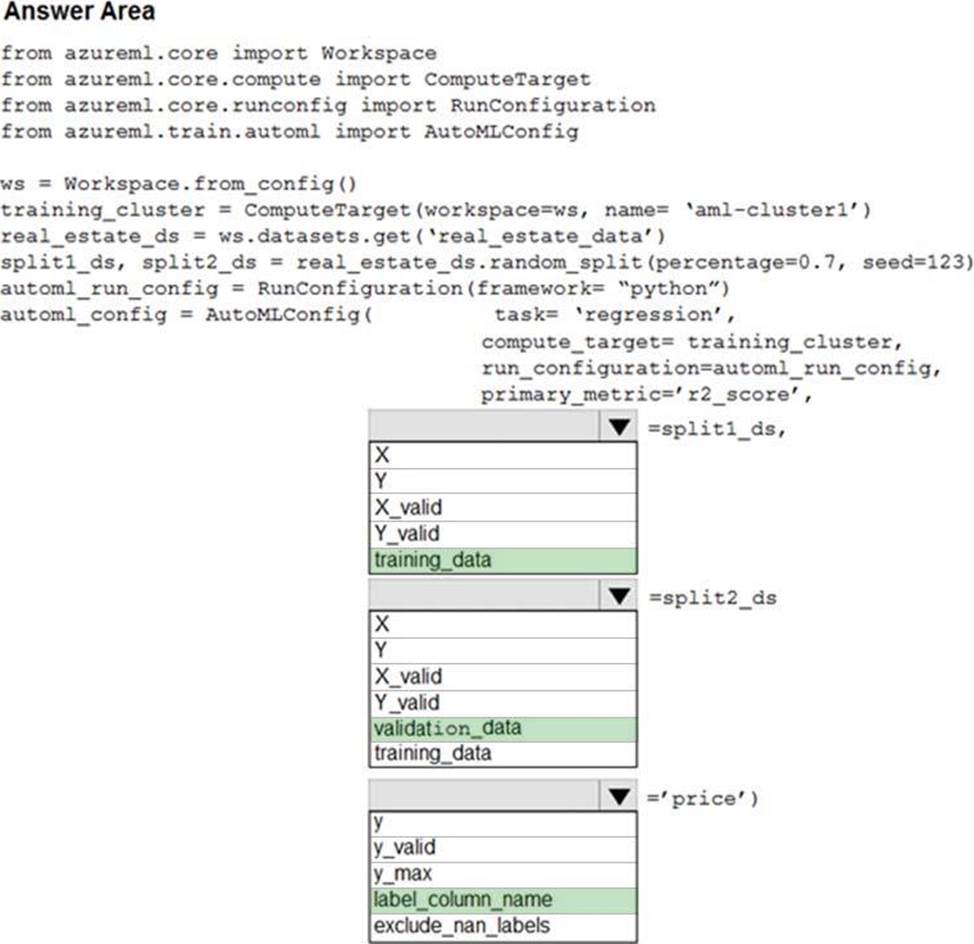
Explanation:
Box 1: training_data
The training data to be used within the experiment. It should contain both training features and a label column (optionally a sample weights column). If training_data is specified, then the label_column_name parameter must also be specified.
Box 2: validation_data
Provide validation data: In this case, you can either start with a single data file and split it into training and validation sets or you can provide a separate data file for the validation set. Either way, the validation_data parameter in your AutoMLConfig object assigns which data to use as your validation set.
Example, the following code example explicitly defines which portion of the provided data in dataset to use for training and validation.
dataset = Dataset.Tabular.from_delimited_files(data)
training_data, validation_data = dataset.random_split(percentage=0.8, seed=1)
automl_config = AutoMLConfig(compute_target = aml_remote_compute, task = ‘classification’,
primary_metric = ‘AUC_weighted’,
training_data = training_data,
validation_data = validation_data,
label_column_name = ‘Class’
)
Box 3: label_column_name
label_column_name:
The name of the label column. If the input data is from a pandas.DataFrame which doesn’t have column names, column indices can be used instead, expressed as integers.
This parameter is applicable to training_data and validation_data parameters.
Latest DP-100 Dumps Valid Version with 227 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
