Hortonworks Apache Hadoop Developer Hadoop 2.0 Certification exam for Pig and Hive Developer Online Training
Hortonworks Apache Hadoop Developer Online Training
The questions for Apache Hadoop Developer were last updated at Mar 21,2026.
- Exam Code: Apache Hadoop Developer
- Exam Name: Hadoop 2.0 Certification exam for Pig and Hive Developer
- Certification Provider: Hortonworks
- Latest update: Mar 21,2026
You need to perform statistical analysis in your MapReduce job and would like to call methods in the Apache Commons Math library, which is distributed as a 1.3 megabyte Java archive (JAR) file.
Which is the best way to make this library available to your MapReducer job at runtime?
- A . Have your system administrator copy the JAR to all nodes in the cluster and set its location in the HADOOP_CLASSPATH environment variable before you submit your job.
- B . Have your system administrator place the JAR file on a Web server accessible to all cluster nodes and then set the HTTP_JAR_URL environment variable to its location.
- C . When submitting the job on the command line, specify the Clibjars option followed by the JAR file path.
- D . Package your code and the Apache Commands Math library into a zip file named JobJar.zip
In a MapReduce job with 500 map tasks, how many map task attempts will there be?
- A . It depends on the number of reduces in the job.
- B . Between 500 and 1000.
- C . At most 500.
- D . At least 500.
- E . Exactly 500.
You want to count the number of occurrences for each unique word in the supplied input data. You’ve decided to implement this by having your mapper tokenize each word and emit a literal value 1, and then have your reducer increment a counter for each literal 1 it receives. After successful implementing this, it occurs to you that you could optimize this by specifying a combiner.
Will you be able to reuse your existing Reduces as your combiner in this case and why or why not?
- A . Yes, because the sum operation is both associative and commutative and the input and output types to the reduce method match.
- B . No, because the sum operation in the reducer is incompatible with the operation of a Combiner.
- C . No, because the Reducer and Combiner are separate interfaces.
- D . No, because the Combiner is incompatible with a mapper which doesn’t use the same data type for both the key and value.
- E . Yes, because Java is a polymorphic object-oriented language and thus reducer code can be reused as a combiner.
What data does a Reducer reduce method process?
- A . All the data in a single input file.
- B . All data produced by a single mapper.
- C . All data for a given key, regardless of which mapper(s) produced it.
- D . All data for a given value, regardless of which mapper(s) produced it.
Given a directory of files with the following structure: line number, tab character, string:
Example:
1abialkjfjkaoasdfjksdlkjhqweroij
2kadfjhuwqounahagtnbvaswslmnbfgy
3kjfteiomndscxeqalkzhtopedkfsikj
You want to send each line as one record to your Mapper.
Which InputFormat should you use to complete the line: conf.setInputFormat (____.class) ; ?
- A . SequenceFileAsTextInputFormat
- B . SequenceFileInputFormat
- C . KeyValueFileInputFormat
- D . BDBInputFormat
Examine the following Hive statements:
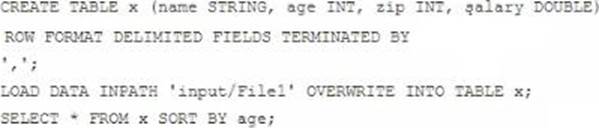
Assuming the statements above execute successfully, which one of the following statements is true?
- A . Each reducer generates a file sorted by age
- B . The SORT BY command causes only one reducer to be used
- C . The output of each reducer is only the age column
- D . The output is guaranteed to be a single file with all the data sorted by age
When can a reduce class also serve as a combiner without affecting the output of a MapReduce program?
- A . When the types of the reduce operation’s input key and input value match the types of the reducer’s output key and output value and when the reduce operation is both communicative and associative.
- B . When the signature of the reduce method matches the signature of the combine method.
- C . Always. Code can be reused in Java since it is a polymorphic object-oriented programming language.
- D . Always. The point of a combiner is to serve as a mini-reducer directly after the map phase to increase performance.
- E . Never. Combiners and reducers must be implemented separately because they serve different purposes.
What does the following WebHDFS command do?
Curl -1 -L “http://host:port/webhdfs/v1/foo/bar?op=OPEN”
- A . Make a directory /foo/bar
- B . Read a file /foo/bar
- C . List a directory /foo
- D . Delete a directory /foo/bar
You need to run the same job many times with minor variations. Rather than hardcoding all job configuration options in your drive code, you’ve decided to have your Driver subclass org.apache.hadoop.conf.Configured and implement the org.apache.hadoop.util.Tool interface.
Indentify which invocation correctly passes.mapred.job.name with a value of Example to Hadoop?
- A . hadoop “mapred.job.name=Example” MyDriver input output
- B . hadoop MyDriver mapred.job.name=Example input output
- C . hadoop MyDrive CD mapred.job.name=Example input output
- D . hadoop setproperty mapred.job.name=Example MyDriver input output
- E . hadoop setproperty (“mapred.job.name=Example”) MyDriver input output
Determine which best describes when the reduce method is first called in a MapReduce job?
- A . Reducers start copying intermediate key-value pairs from each Mapper as soon as it has completed. The programmer can configure in the job what percentage of the intermediate data should arrive before the reduce method begins.
- B . Reducers start copying intermediate key-value pairs from each Mapper as soon as it has completed. The reduce method is called only after all intermediate data has been copied and sorted.
- C . Reduce methods and map methods all start at the beginning of a job, in order to provide optimal performance for map-only or reduce-only jobs.
- D . Reducers start copying intermediate key-value pairs from each Mapper as soon as it has completed. The reduce method is called as soon as the intermediate key-value pairs start to arrive.
Latest Apache Hadoop Developer Dumps Valid Version with 108 Q&As
Latest And Valid Q&A | Instant Download | Once Fail, Full Refund
