Question #1
You are creating a regression model with the input income, education and current debt of a customer, what could be the possible output from this model.
- A . Customer fit as a good
- B . Customer fit as acceptable or average category
- C . expressed as a percent, that the customer will default on a loan
- D . 1 and 3 are correct
- E . 2 and 3 are correct
Correct Answer: C
C
Explanation:
Regression is the process of using several inputs to produce one or more outputs. For example The input might be the income, education and current debt of a customer The output might be the probability, expressed as a percent that the customer will default on a loan. Contrast this to classification where the output is not a number, but a class.
C
Explanation:
Regression is the process of using several inputs to produce one or more outputs. For example The input might be the income, education and current debt of a customer The output might be the probability, expressed as a percent that the customer will default on a loan. Contrast this to classification where the output is not a number, but a class.
Question #2
What type of output generated in case of linear regression?
- A . Continuous variable
- B . Discrete Variable
- C . Any of the Continuous and Discrete variable
- D . Values between 0 and 1
Correct Answer: A
A
Explanation:
Linear regression model generate continuous output variable.
A
Explanation:
Linear regression model generate continuous output variable.
Question #3
If E1 and E2 are two events, how do you represent the conditional probability given that E2 occurs given that E1 has occurred?
- A . P(E1)/P(E2)
- B . P(E1+E2)/P(E1)
- C . P(E2)/P(E1)
- D . P(E2)/(P(E1+E2)
Correct Answer: C
Question #4
In which of the scenario you can use the regression to predict the values
- A . Samsung can use it for mobile sales forecast
- B . Mobile companies can use it to forecast manufacturing defects
- C . Probability of the celebrity divorce
- D . Only 1 and 2
- E . All 1 ,2 and 3
Correct Answer: E
E
Explanation:
Regression is a tool which Companies may use this for things such as sales forecasts or forecasting manufacturing defects. Another creative example is predicting the probability of celebrity divorce.
E
Explanation:
Regression is a tool which Companies may use this for things such as sales forecasts or forecasting manufacturing defects. Another creative example is predicting the probability of celebrity divorce.
Question #5
You are working as a data science consultant for a gaming company. You have three member team and all other stake holders are from the company itself like project managers and project sponsored, data team etc.
During the discussion project managed asked you that when can you tell me that the model you are using is robust enough, after which step you can consider answer for this question?
- A . Data Preparation
- B . Discovery
- C . Operationalize
- D . Model planning
- E . Model building
Correct Answer: E
E
Explanation:
To answer whether the model you are building is robust enough or not you need to have answer below questions at least
– Model is performing as expected with the test data or not?
– Whatever hypothesis defined in the initial phase is being tested or not?
– Do we need more data?
– Domain experts are convinced or not with the model?
And all these can be answered when you have built the model and tested with the test data sets. Hence, correct option will be Model Building.
E
Explanation:
To answer whether the model you are building is robust enough or not you need to have answer below questions at least
– Model is performing as expected with the test data or not?
– Whatever hypothesis defined in the initial phase is being tested or not?
– Do we need more data?
– Domain experts are convinced or not with the model?
And all these can be answered when you have built the model and tested with the test data sets. Hence, correct option will be Model Building.
Question #6
Logistic regression is a model used for prediction of the probability of occurrence of an event. It makes use of several variables that may be……
- A . Numerical
- B . Categorical
- C . Both 1 and 2 are correct
- D . None of the 1 and 2 are correct
Correct Answer: C
C
Explanation:
Logistic regression is a model used for prediction of the probability of occurrence of an event. It makes use of several predictor variables that may be either numerical or categories.
C
Explanation:
Logistic regression is a model used for prediction of the probability of occurrence of an event. It makes use of several predictor variables that may be either numerical or categories.
Question #7
Select the statement which applies correctly to the Naive Bayes
- A . Works with a small amount of data
- B . Sensitive to how the input data is prepared
- C . Works with nominal values
Correct Answer: A,B,C
Question #8
The figure below shows a plot of the data of a data matrix M that is 1000 x 2.
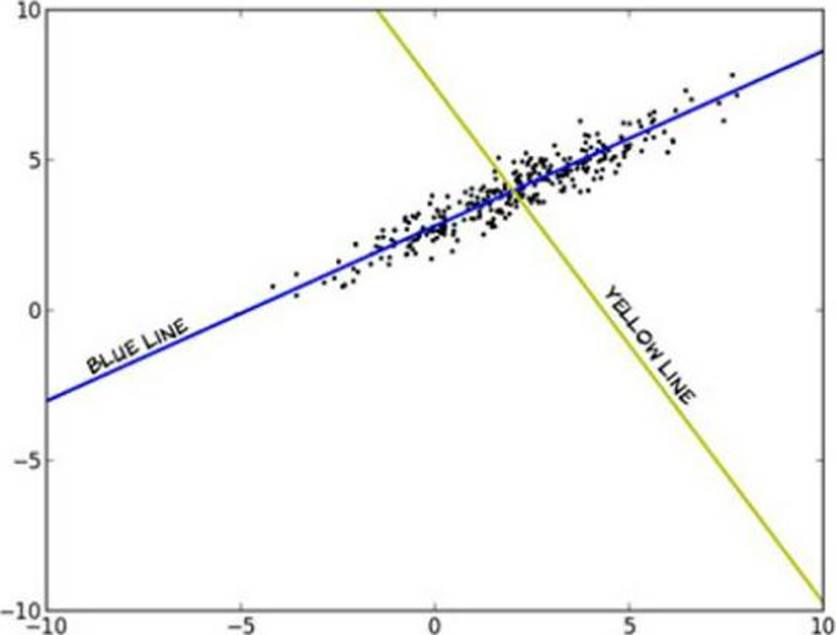
Which line represents the first principal component?
- A . yellow
- B . blue
- C . Neither
Correct Answer: B
B
Explanation:
Principal component analysis (PCA) involves a mathematical procedure that transforms a number of (possibly) correlated variables into a (smaller) number of uncorrelated variables called principal components. The first principal component accounts for as much of the variability in the data as possible, and each succeeding component accounts for as much of the remaining variability as possible.
The first principal component corresponds to the greatest variance in the data. The blue line is evidently this first principal component, because if we project the data onto the blue line, the data is more spread out (higher variance) than if projected onto any other line, including the yellow one.
B
Explanation:
Principal component analysis (PCA) involves a mathematical procedure that transforms a number of (possibly) correlated variables into a (smaller) number of uncorrelated variables called principal components. The first principal component accounts for as much of the variability in the data as possible, and each succeeding component accounts for as much of the remaining variability as possible.
The first principal component corresponds to the greatest variance in the data. The blue line is evidently this first principal component, because if we project the data onto the blue line, the data is more spread out (higher variance) than if projected onto any other line, including the yellow one.
Question #9
Refer to Exhibit
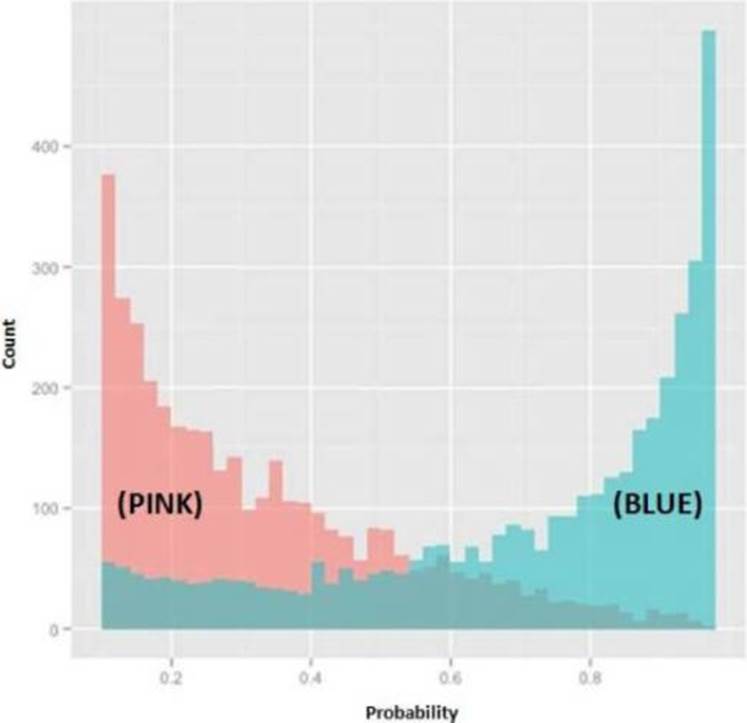
In the exhibit, the x-axis represents the derived probability of a borrower defaulting on a loan. Also in the exhibit, the pink represents borrowers that are known to have not defaulted on their loan, and the blue represents borrowers that are known to have defaulted on their loan.
Which analytical method could produce the probabilities needed to build this exhibit?
- A . Linear Regression
- B . Logistic Regression
- C . Discriminant Analysis
- D . Association Rules
Correct Answer: B
Question #10
You are working on a email spam filtering assignment, while working on this you find there is new word e.g. HadoopExam comes in email, and in your solutions you never come across this word before, hence probability of this words is coming in either email could be zero.
So which of the following algorithm can help you to avoid zero probability?
- A . Naive Bayes
- B . Laplace Smoothing
- C . Logistic Regression
- D . All of the above
Correct Answer: B
B
Explanation:
Laplace smoothing is a technique for parameter estimation which accounts for unobserved events. It is more robust and will not fail completely when data that has never been observed in training shows up.
B
Explanation:
Laplace smoothing is a technique for parameter estimation which accounts for unobserved events. It is more robust and will not fail completely when data that has never been observed in training shows up.
Question #11
A bio-scientist is working on the analysis of the cancer cells. To identify whether the cell is cancerous or not, there has been hundreds of tests are done with small variations to say yes to the problem. Given the test result for a sample of healthy and cancerous cells, which of the following technique you will use to determine whether a cell is healthy?
- A . Linear regression
- B . Collaborative filtering
- C . Naive Bayes
- D . Identification Test
Correct Answer: C
C
Explanation:
In this problem you have been given high-dimensional independent variables like yes, no: test results etc. and you have to predict either valid or not valid (One of two).
So all of the below technique can be applied to this problem.
Support vector machines Naive Bayes Logistic regression Random decision forests
C
Explanation:
In this problem you have been given high-dimensional independent variables like yes, no: test results etc. and you have to predict either valid or not valid (One of two).
So all of the below technique can be applied to this problem.
Support vector machines Naive Bayes Logistic regression Random decision forests
Question #12
Consider flipping a coin for which the probability of heads is p, where p is unknown, and our goa is to estimate p. The obvious approach is to count how many times the coin came up heads and divide by the total number of coin flips. If we flip the coin 1000 times and it comes up heads 367 times, it is very reasonable to estimate p as approximately 0.367.
However, suppose we flip the coin only twice and we get heads both times. Is it reasonable to estimate p as 1.0? Intuitively, given that we only flipped the coin twice, it seems a bit rash to conclude that the coin will always come up heads, and____________is a way of avoiding such rash conclusions.
- A . Naive Bayes
- B . Laplace Smoothing
- C . Logistic Regression
- D . Linear Regression
Correct Answer: B
B
Explanation:
Smooth the estimates: consider flipping a coin for which the probability of heads is p, where p is unknown, and our goal is to estimate p. The obvious approach is to count how many times the coin came up heads and divide by the total number of coin flips. If we flip the coin 1000 times and it comes up heads 367 times, it is very reasonable to estimate p as approximately 0.367. However, suppose we flip the coin only twice and we get heads both times. Is it reasonable to estimate p as 1.0? Intuitively, given that we only flipped the coin twice, it seems a bit rash to conclude that the coin will always come up heads, and smoothing is a way of avoiding such rash conclusions. A simple smoothing method, called Laplace smoothing (or Laplace’s law of succession or add-one smoothing in R&N), is to estimate p by (one plus the number of heads) / (two plus the total number of flips). Said differently, if we are keeping count of the number of heads and the number of tails, this rule is equivalent to starting each of our counts at one, rather than zero. Another advantage of Laplace smoothing is that it avoids estimating any probabilities to be zero, even for events never observed in the data. Laplace add-one smoothing now assigns too much probability to unseen words
B
Explanation:
Smooth the estimates: consider flipping a coin for which the probability of heads is p, where p is unknown, and our goal is to estimate p. The obvious approach is to count how many times the coin came up heads and divide by the total number of coin flips. If we flip the coin 1000 times and it comes up heads 367 times, it is very reasonable to estimate p as approximately 0.367. However, suppose we flip the coin only twice and we get heads both times. Is it reasonable to estimate p as 1.0? Intuitively, given that we only flipped the coin twice, it seems a bit rash to conclude that the coin will always come up heads, and smoothing is a way of avoiding such rash conclusions. A simple smoothing method, called Laplace smoothing (or Laplace’s law of succession or add-one smoothing in R&N), is to estimate p by (one plus the number of heads) / (two plus the total number of flips). Said differently, if we are keeping count of the number of heads and the number of tails, this rule is equivalent to starting each of our counts at one, rather than zero. Another advantage of Laplace smoothing is that it avoids estimating any probabilities to be zero, even for events never observed in the data. Laplace add-one smoothing now assigns too much probability to unseen words
Question #13
What is one modeling or descriptive statistical function in MADlib that is typically not provided in a standard relational database?
- A . Expected value
- B . Variance
- C . Linear regression
- D . Quantiles
Correct Answer: C
C
Explanation:
Linear regression models a linear relationship of a scalar dependent variable y to one or more explanatory independent variables x to build a model of coefficients.
C
Explanation:
Linear regression models a linear relationship of a scalar dependent variable y to one or more explanatory independent variables x to build a model of coefficients.
Question #14
As a data scientist consultant at ABC Corp, you are working on a recommendation engine for the learning resources for end user.
So Which recommender system technique benefits most from additional user preference data?
- A . Naive Bayes classifier
- B . Item-based collaborative filtering
- C . Logistic Regression
- D . Content-based filtering
Correct Answer: B
B
Explanation:
Item-based scales with the number of items, and user-based scales with the number of users you have. If you have something like a store, you’ll have a few thousand items at the most. The biggest stores at the time of writing have around 100,000 items. In the Netflix competition, there were 480,000 users and 17,700 movies. If you have a lot of users: then you’ll probably want to go with item-based similarity. For most product-driven recommendation engines, the number of users outnumbers the number of items. There are more people buying items than unique items for sale. Item-based collaborative filtering makes predictions based on users preferences for items. More preference data should be beneficial to this type of algorithm. Content-based filtering recommender systems use information about items or users, and not user preferences, to make recommendations. Logistic Regression, Power iteration and a Naive Bayes classifier are not recommender system techniques.
B
Explanation:
Item-based scales with the number of items, and user-based scales with the number of users you have. If you have something like a store, you’ll have a few thousand items at the most. The biggest stores at the time of writing have around 100,000 items. In the Netflix competition, there were 480,000 users and 17,700 movies. If you have a lot of users: then you’ll probably want to go with item-based similarity. For most product-driven recommendation engines, the number of users outnumbers the number of items. There are more people buying items than unique items for sale. Item-based collaborative filtering makes predictions based on users preferences for items. More preference data should be beneficial to this type of algorithm. Content-based filtering recommender systems use information about items or users, and not user preferences, to make recommendations. Logistic Regression, Power iteration and a Naive Bayes classifier are not recommender system techniques.
Question #15
Which of the following technique can be used to the design of recommender systems?
- A . Naive Bayes classifier
- B . Power iteration
- C . Collaborative filtering
- D . 1 and 3
- E . 2 and 3
Correct Answer: C
C
Explanation:
One approach to the design of recommender systems that has seen wide use is collaborative filtering. Collaborative filtering methods are based on collecting and analyzing a large amount of information on users’ behaviors, activities or preferences and predicting what users will like based on their similarity to other users. A key advantage of the collaborative filtering approach is that it does not rely on machine analyzable content and therefore it is capable of accurately recommending complex items such as movies without requiring an "understanding" of the item itself. Many algorithms have been used in measuring user similarity or item similarity in recommender systems. For example the k-nearest neighbor (k-NN) approach and the Pearson Correlation
C
Explanation:
One approach to the design of recommender systems that has seen wide use is collaborative filtering. Collaborative filtering methods are based on collecting and analyzing a large amount of information on users’ behaviors, activities or preferences and predicting what users will like based on their similarity to other users. A key advantage of the collaborative filtering approach is that it does not rely on machine analyzable content and therefore it is capable of accurately recommending complex items such as movies without requiring an "understanding" of the item itself. Many algorithms have been used in measuring user similarity or item similarity in recommender systems. For example the k-nearest neighbor (k-NN) approach and the Pearson Correlation
Question #16
Regularization is a very important technique in machine learning to prevent over fitting. And Optimizing with a L1 regularization term is harder than with an L2 regularization term because
- A . The penalty term is not differentiate
- B . The second derivative is not constant
- C . The objective function is not convex
- D . The constraints are quadratic
Correct Answer: A
A
Explanation:
Regularization is a very important technique in machine learning to prevent overfitting. Mathematically speaking, it adds a regularization term in order to prevent the coefficients to fit so perfectly to overfit. The difference between the L1 and L2 is just that L2 is the sum of the square of the weights, while L1 is just the sum of the weights.
Much of optimization theory has historically focused on convex loss functions because they’re much easier to optimize than non-convex functions: a convex function over a bounded domain is guaranteed to have a minimum, and it’s easy to find that minimum by following the gradient of the function at each point no matter where you start. For non-convex functions, on the other hand, where you start matters a great deal; if you start in a bad position and follow the gradient, you’re likely to end up in a local minimum that is not necessarily equal to the global minimum.
You can think of convex functions as cereal bowls: anywhere you start in the cereal bowl, you’re likely to roll down to the bottom. A non-convex function is more like a skate park: lots of ramps, dips, ups and downs. It’s a lot harder to find the lowest point in a skate park than it is a cereal bowl.
A
Explanation:
Regularization is a very important technique in machine learning to prevent overfitting. Mathematically speaking, it adds a regularization term in order to prevent the coefficients to fit so perfectly to overfit. The difference between the L1 and L2 is just that L2 is the sum of the square of the weights, while L1 is just the sum of the weights.
Much of optimization theory has historically focused on convex loss functions because they’re much easier to optimize than non-convex functions: a convex function over a bounded domain is guaranteed to have a minimum, and it’s easy to find that minimum by following the gradient of the function at each point no matter where you start. For non-convex functions, on the other hand, where you start matters a great deal; if you start in a bad position and follow the gradient, you’re likely to end up in a local minimum that is not necessarily equal to the global minimum.
You can think of convex functions as cereal bowls: anywhere you start in the cereal bowl, you’re likely to roll down to the bottom. A non-convex function is more like a skate park: lots of ramps, dips, ups and downs. It’s a lot harder to find the lowest point in a skate park than it is a cereal bowl.
Question #17
In which of the following scenario we can use naTve Bayes theorem for classification
- A . Classify whether a given person is a male or a female based on the measured features.
The features include height, weight and foot size. - B . To classify whether an email is spam or not spam
- C . To identify whether a fruit is an orange or not based on features like diameter, color and shape
Correct Answer: A,B,C
A,B,C
Explanation:
naive Bayes classifiers have worked quite well in many real-world situations, famously document classification and spam filtering. They requires a small amount of training data to estimate the necessary parameters
A,B,C
Explanation:
naive Bayes classifiers have worked quite well in many real-world situations, famously document classification and spam filtering. They requires a small amount of training data to estimate the necessary parameters
Question #18
In unsupervised learning which statements correctly applies
- A . It does not have a target variable
- B . Instead of telling the machine Predict Y for our data X, we’re asking What can you tell me about X?
- C . telling the machine Predict Y for our data X
Correct Answer: A,B
A,B
Explanation:
In unsupervised learning we don’t have a target variable as we did in classification and regression.
Instead of telling the machine Predict Y for our data X, we’re asking What can you tell me about X?
Things we ask the machine to tell us about X may be What are the six best groups we can make out of X? or What three features occur together most frequently in X?
A,B
Explanation:
In unsupervised learning we don’t have a target variable as we did in classification and regression.
Instead of telling the machine Predict Y for our data X, we’re asking What can you tell me about X?
Things we ask the machine to tell us about X may be What are the six best groups we can make out of X? or What three features occur together most frequently in X?
Question #19
What is the best way to evaluate the quality of the model found by an unsupervised algorithm like k-means clustering, given metrics for the cost of the clustering (how well it fits the data) and its stability (how similar the clusters are across multiple runs over the same data)?
- A . The lowest cost clustering subject to a stability constraint
- B . The lowest cost clustering
- C . The most stable clustering subject to a minimal cost constraint
- D . The most stable clustering
Correct Answer: A
A
Explanation:
There is a tradeoff between cost and stability in unsupervised learning. The more tightly you fit the data, the less stable the model will be, and vice versa. The idea is to find a good balance with more weight given to the cost. Typically a good approach is to set a stability threshold and select the model that achieves the lowest cost above the stability threshold.
A
Explanation:
There is a tradeoff between cost and stability in unsupervised learning. The more tightly you fit the data, the less stable the model will be, and vice versa. The idea is to find a good balance with more weight given to the cost. Typically a good approach is to set a stability threshold and select the model that achieves the lowest cost above the stability threshold.
Question #20
Which of the following is not a correct application for the Classification?
- A . credit scoring
- B . tumor detection
- C . image recognition
- D . drug discovery
Correct Answer: D
D
Explanation:
Classification: Build models to classify data into different categories credit scoring, tumor detection, image recognition Regression: Build models to predict continuous data, electricity load forecasting, algorithmic trading, drug discovery
D
Explanation:
Classification: Build models to classify data into different categories credit scoring, tumor detection, image recognition Regression: Build models to predict continuous data, electricity load forecasting, algorithmic trading, drug discovery
Question #21
Your customer provided you with 2. 000 unlabeled records three groups.
What is the correct analytical method to use?
- A . Semi Linear Regression
- B . Logistic regression
- C . Naive Bayesian classification
- D . Linear regression
- E . K-means clustering
Correct Answer: E
E
Explanation:
k-means clustering is a method of vector quantization^ originally from signal processing, that is popular for cluster analysis in data mining, k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster This results in a partitioning of the data space into Voronoi cells.
The problem is computationally difficult (NP-hard); however there are efficient heuristic algorithms that are commonly employed and converge quickly to a local optimum. These are usually similar to the expectation-maximization algorithm for mixtures of Gaussian distributions via an iterative refinement approach employed by both algorithms. Additionally they both use cluster centers to model the data; however k-means clustering tends to find clusters of comparable spatial extent, while the expectation-maximization mechanism allows clusters to have different shapes.
The algorithm has nothing to do with and should not be confused with k-nearest neighbor another popular machine learning technique.
E
Explanation:
k-means clustering is a method of vector quantization^ originally from signal processing, that is popular for cluster analysis in data mining, k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster This results in a partitioning of the data space into Voronoi cells.
The problem is computationally difficult (NP-hard); however there are efficient heuristic algorithms that are commonly employed and converge quickly to a local optimum. These are usually similar to the expectation-maximization algorithm for mixtures of Gaussian distributions via an iterative refinement approach employed by both algorithms. Additionally they both use cluster centers to model the data; however k-means clustering tends to find clusters of comparable spatial extent, while the expectation-maximization mechanism allows clusters to have different shapes.
The algorithm has nothing to do with and should not be confused with k-nearest neighbor another popular machine learning technique.
Question #22
Which of the following steps you will be using in the discovery phase?
- A . What all are the data sources for the project?
- B . Analyze the Raw data and its format and structure.
- C . What all tools are required, in the project?
- D . What is the network capacity required
- E . What Unix server capacity required?
Correct Answer: A,B,C,D,E
A,B,C,D,E
Explanation:
During the discovery phase you need to find how much resources are required as early as possible and for that even you can involve various stakeholders like Software engineering team, DBAs, Network engineers, System administrators etc. for your requirement and these resources are already available or you need to procure them. Also, what would be source of the data? What all tools and software’s are required to execute the same?
A,B,C,D,E
Explanation:
During the discovery phase you need to find how much resources are required as early as possible and for that even you can involve various stakeholders like Software engineering team, DBAs, Network engineers, System administrators etc. for your requirement and these resources are already available or you need to procure them. Also, what would be source of the data? What all tools and software’s are required to execute the same?
Question #23
You are working on a problem where you have to predict whether the claim is done valid or not. And you find that most of the claims which are having spelling errors as well as corrections in the manually filled claim forms compare to the honest claims.
Which of the following technique is suitable to find out whether the claim is valid or not?
- A . Naive Bayes
- B . Logistic Regression
- C . Random Decision Forests
- D . Any one of the above
Correct Answer: D
D
Explanation:
In this problem you have been given high-dimensional independent variables like texts, corrections, test results etc. and you have to predict either valid or not valid (One of two). So all of the below technique can be applied to this problem.
Support vector machines Naive Bayes Logistic regression Random decision forests
D
Explanation:
In this problem you have been given high-dimensional independent variables like texts, corrections, test results etc. and you have to predict either valid or not valid (One of two). So all of the below technique can be applied to this problem.
Support vector machines Naive Bayes Logistic regression Random decision forests
Question #24
The method based on principal component analysis (PCA) evaluates the features according to
- A . The projection of the largest eigenvector of the correlation matrix on the initial dimensions
- B . According to the magnitude of the components of the discriminate vector
- C . The projection of the smallest eigenvector of the correlation matrix on the initial dimensions
- D . None of the above
Correct Answer: A
A
Explanation:
Feature Selection:
The method based on principal component analysis (PCA) evaluates the features according to the projection of the largest eigenvector of the correlation matrix on the initial dimensions, the method based on Fisher’s linear discriminate analysis evaluates. Them according to the magnitude of the components of the discriminate vector.
A
Explanation:
Feature Selection:
The method based on principal component analysis (PCA) evaluates the features according to the projection of the largest eigenvector of the correlation matrix on the initial dimensions, the method based on Fisher’s linear discriminate analysis evaluates. Them according to the magnitude of the components of the discriminate vector.
Question #25
Which is an example of supervised learning?
- A . PCA
- B . k-means clustering
- C . SVD
- D . EM
- E . SVM
Correct Answer: E
E
Explanation:
SVMs can be used to solve various real world problems:
• SVMs are helpful in text and hypertext categorization as their application can significantly reduce the need for labeled training instances in both the standard inductive and transductive settings.
• Classification of images can also be performed using SVMs. Experimental results show that SVMs achieve significantly higher search accuracy than traditional query refinement schemes after just three to four rounds of relevance feedback.
• SVMs are also useful in medical science to classify proteins with up to 90% of the compounds classified correctly.
• Hand-written characters can be recognized using SVM
E
Explanation:
SVMs can be used to solve various real world problems:
• SVMs are helpful in text and hypertext categorization as their application can significantly reduce the need for labeled training instances in both the standard inductive and transductive settings.
• Classification of images can also be performed using SVMs. Experimental results show that SVMs achieve significantly higher search accuracy than traditional query refinement schemes after just three to four rounds of relevance feedback.
• SVMs are also useful in medical science to classify proteins with up to 90% of the compounds classified correctly.
• Hand-written characters can be recognized using SVM
Question #26
You are designing a recommendation engine for a website where the ability to generate more personalized recommendations by analyzing information from the past activity of a specific user, or the history of other users deemed to be of similar taste to a given user. These resources are used as user profiling and helps the site recommend content on a user-by-user basis. The more a given user makes use of the system, the better the recommendations become, as the system gains data to improve its model of that user.
What kind of this recommendation engine is?
- A . Naive Bayes classifier
- B . Collaborative filtering
- C . Logistic Regression
- D . Content-based filtering
Correct Answer: B
B
Explanation:
Another aspect of collaborative filtering systems is the ability to generate more personalized recommendations by analyzing information from the past activity of a specific user, or the history of other users deemed to be of similar taste to a given user. These resources are used as user profiling and help the site recommend content on a user-by-user basis. The more a given user makes use of the system, the better the recommendations become, as the system gains data to improve its model of that user
B
Explanation:
Another aspect of collaborative filtering systems is the ability to generate more personalized recommendations by analyzing information from the past activity of a specific user, or the history of other users deemed to be of similar taste to a given user. These resources are used as user profiling and help the site recommend content on a user-by-user basis. The more a given user makes use of the system, the better the recommendations become, as the system gains data to improve its model of that user
Question #27
RMSE measures error of a predicted
- A . Numerical Value
- B . Categorical values
- C . For booth Numerical and categorical values
Correct Answer: A
Question #28
Refer to exhibit
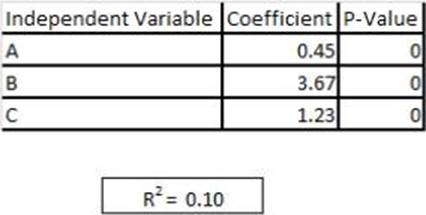
You are asked to write a report on how specific variables impact your client’s sales using a data set provided to you by the client. The data includes 15 variables that the client views as directly related to sales, and you are restricted to these variables only. After a preliminary analysis of the data, the following findings were made: 1. Multicollinearity is not an issue among the variables 2. Only three variables-A, B, and C-have significant correlation with sales You build a linear regression model on the dependent variable of sales with the independent variables of A, B, and C. The results of the regression are seen in the exhibit. You cannot request additional data.
What is a way that you could try to increase the R2 of the model without artificially inflating it?
- A . Create clusters based on the data and use them as model inputs
- B . Force all 15 variables into the model as independent variables
- C . Create interaction variables based only on variables A, B, and C
- D . Break variables A, B, and C into their own univariate models
Correct Answer: A
A
Explanation:
In statistics, linear regression is an approach for modeling the relationship between a scalar dependent variable y and one or more explanatory variables (or independent variable) denoted X. The case of one explanatory variable is called simple linear regression. For more than one explanatory variable, the process is called multiple linear regression. (This term should be distinguished from multivariate linear regression^ where multiple correlated dependent variables are predicted, rather than a single scalar variable.) In linear regression data are modeled using linear predictor functions, and unknown model parameters are estimated from the data. Such models are called linear models. Most commonly, linear regression refers to a model in which the conditional mean of y given the value of X is an affine function of X. Less commonly: linear regression could refer to a model in which the median, or some other quantile of the conditional distribution of y given X is expressed as a linear function of X. Like all forms of regression analysis, linear regression focuses on the conditional probability distribution of y given X, rather than on the joint probability distribution of y and X: which is the domain of multivariate analysis.
A
Explanation:
In statistics, linear regression is an approach for modeling the relationship between a scalar dependent variable y and one or more explanatory variables (or independent variable) denoted X. The case of one explanatory variable is called simple linear regression. For more than one explanatory variable, the process is called multiple linear regression. (This term should be distinguished from multivariate linear regression^ where multiple correlated dependent variables are predicted, rather than a single scalar variable.) In linear regression data are modeled using linear predictor functions, and unknown model parameters are estimated from the data. Such models are called linear models. Most commonly, linear regression refers to a model in which the conditional mean of y given the value of X is an affine function of X. Less commonly: linear regression could refer to a model in which the median, or some other quantile of the conditional distribution of y given X is expressed as a linear function of X. Like all forms of regression analysis, linear regression focuses on the conditional probability distribution of y given X, rather than on the joint probability distribution of y and X: which is the domain of multivariate analysis.
Question #29
Which technique you would be using to solve the below problem statement? "What is the probability that individual customer will not repay the loan amount?"
- A . Classification
- B . Clustering
- C . Linear Regression
- D . Logistic Regression
- E . Hypothesis testing
Correct Answer: D
Question #30
Question-3: In machine learning, feature hashing, also known as the hashing trick (by analogy to the kernel trick), is a fast and space-efficient way of vectorizing features (such as the words in a language), i.e., turning arbitrary features into indices in a vector or matrix. It works by applying a hash function to the features and using their hash values modulo the number of features as indices directly, rather than looking the indices up in an associative array.
So what is the primary reason of the hashing trick for building classifiers?
- A . It creates the smaller models
- B . It requires the lesser memory to store the coefficients for the model
- C . It reduces the non-significant features e.g. punctuations
- D . Noisy features are removed
Correct Answer: B
B
Explanation:
This hashed feature approach has the distinct advantage of requiring less memory and one less pass through the training data, but it can make it much harder to reverse engineer vectors to determine which original feature mapped to a vector location. This is because multiple features may hash to the same location. With large vectors or with multiple locations per feature, this isn’t a problem for accuracy but it can make it hard to understand what a classifier is doing.
Models always have a coefficient per feature, which are stored in memory during model building. The hashing trick collapses a high number of features to a small number which reduces the number of coefficients and thus memory requirements. Noisy features are not removed; they are combined with other features and so still have an impact.
The validity of this approach depends a lot on the nature of the features and problem domain; knowledge of the domain is important to understand whether it is applicable or will likely produce poor results. While hashing features may produce a smaller model, it will be one built from odd combinations of real-world features, and so will be harder to interpret. An additional benefit of feature hashing is that the unknown and unbounded vocabularies typical of word-like variables aren’t a problem.
B
Explanation:
This hashed feature approach has the distinct advantage of requiring less memory and one less pass through the training data, but it can make it much harder to reverse engineer vectors to determine which original feature mapped to a vector location. This is because multiple features may hash to the same location. With large vectors or with multiple locations per feature, this isn’t a problem for accuracy but it can make it hard to understand what a classifier is doing.
Models always have a coefficient per feature, which are stored in memory during model building. The hashing trick collapses a high number of features to a small number which reduces the number of coefficients and thus memory requirements. Noisy features are not removed; they are combined with other features and so still have an impact.
The validity of this approach depends a lot on the nature of the features and problem domain; knowledge of the domain is important to understand whether it is applicable or will likely produce poor results. While hashing features may produce a smaller model, it will be one built from odd combinations of real-world features, and so will be harder to interpret. An additional benefit of feature hashing is that the unknown and unbounded vocabularies typical of word-like variables aren’t a problem.
Question #31
You have modeled the datasets with 5 independent variables called A, B, C, D and E having relationships which is not dependent each other, and also the variable A,B and C are continuous and variable D and E are discrete (mixed mode).
Now you have to compute the expected value of the variable let say A, then which of the following computation you will prefer
- A . Integration
- B . Differentiation
- C . Transformation
- D . Generalization
Correct Answer: A
A
Explanation:
A
Explanation:

Text
Description automatically generated

Text
Description automatically generated
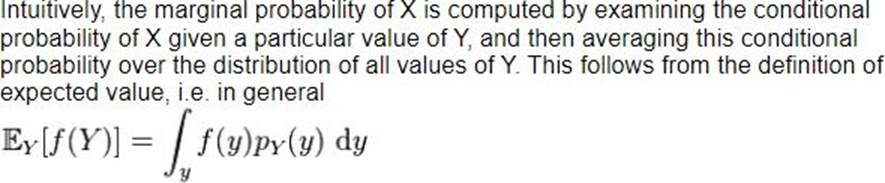
Text
Description automatically generated
Question #32
Clustering is a type of unsupervised learning with the following goals
- A . Maximize a utility function
- B . Find similarities in the training data
- C . Not to maximize a utility function
- D . 1 and 2
- E . 2 and 3
Correct Answer: E
E
Explanation:
type of unsupervised learning is called clustering. In this type of learning, The goal is not to maximize a utility function, but simply to find similarities in the training data. The assumption is often that the clusters discovered will match reasonably well with an intuitive classification. For instance, clustering individuals based on demographics might result in a clustering of the wealthy in one group and the poor in another. Clustering can be useful when there is enough data to form clusters (though this turns out to be difficult at times) and especially when additional data about members of a cluster can be used to produce further results due to dependencies in the data.
E
Explanation:
type of unsupervised learning is called clustering. In this type of learning, The goal is not to maximize a utility function, but simply to find similarities in the training data. The assumption is often that the clusters discovered will match reasonably well with an intuitive classification. For instance, clustering individuals based on demographics might result in a clustering of the wealthy in one group and the poor in another. Clustering can be useful when there is enough data to form clusters (though this turns out to be difficult at times) and especially when additional data about members of a cluster can be used to produce further results due to dependencies in the data.
Question #33
Under which circumstance do you need to implement N-fold cross-validation after creating a regression model?
- A . The data is unformatted.
- B . There is not enough data to create a test set.
- C . There are missing values in the data.
- D . There are categorical variables in the model.
Correct Answer: B
Question #34
You have data of 10.000 people who make the purchasing from a specific grocery store. You also have their income detail in the data. You have created 5 clusters using this data. But in one of the cluster you see that only 30 people are falling as below 30, 2400, 2600, 2700, 2270 etc."
What would you do in this case?
- A . You will be increasing number of clusters.
- B . You will be decreasing the number of clusters.
- C . You will remove that 30 people from dataset
- D . You will be multiplying standard deviation with the 100
Correct Answer: B
B
Explanation:
Decreasing the number of clusters will help in adjusting this outlier cluster to get adjusted in another cluster.
B
Explanation:
Decreasing the number of clusters will help in adjusting this outlier cluster to get adjusted in another cluster.
Question #35
In which phase of the data analytics lifecycle do Data Scientists spend the most time in a project?
- A . Discovery
- B . Data Preparation
- C . Model Building
- D . Communicate Results
Correct Answer: B
Question #36
What is the probability that the total of two dice will be greater than 8, given that the first die is a 6?
- A . 1/3
- B . 2/3
- C . 1/6
- D . 2/6
Correct Answer: B
Question #37
Which of the following is a correct example of the target variable in regression (supervised learning)?
- A . Nominal values like true, false
- B . Reptile, fish, mammal, amphibian, plant, fungi
- C . Infinite number of numeric values, such as 0.100, 42.001, 1000.743..
- D . All of the above
Correct Answer: D
D
Explanation:
We address two cases of the target variable. The first case occurs when the target variable can take only nominal values: true or false; reptile, fish: mammal, amphibian, plant, fungi. The second case of classification occurs when the target variable can take an infinite number of numeric values, such as 0.100, 42.001, 1000.743, …. This case is called regression.
D
Explanation:
We address two cases of the target variable. The first case occurs when the target variable can take only nominal values: true or false; reptile, fish: mammal, amphibian, plant, fungi. The second case of classification occurs when the target variable can take an infinite number of numeric values, such as 0.100, 42.001, 1000.743, …. This case is called regression.
Question #38
Which of the following true with regards to the K-Means clustering algorithm?
- A . Labels are not pre-assigned to each objects in the cluster.
- B . Labels are pre-assigned to each objects in the cluster.
- C . It classify the data based on the labels.
- D . It discovers the center of each cluster.
- E . It find each objects fall in which particular cluster
Correct Answer: A,D,E
A,D,E
Explanation:
Clustering does not require any predefined labels on the object, rather it consider the attributes on the object. Hence, option-B is out. Clustering is different than classification technique.
Hence you can discard the option-C as well. It does not use the pre-defined labels, hence it is called unsupervised learning and option-Ais correct. Main purpose of the Clustering technique is to determine the center of each Cluster and then find the distance from that center. If object is near the center than it would fall in that particular cluster. Hence, finally you will have group or clusters created and get to know that objects fall in which particular cluster.
A,D,E
Explanation:
Clustering does not require any predefined labels on the object, rather it consider the attributes on the object. Hence, option-B is out. Clustering is different than classification technique.
Hence you can discard the option-C as well. It does not use the pre-defined labels, hence it is called unsupervised learning and option-Ais correct. Main purpose of the Clustering technique is to determine the center of each Cluster and then find the distance from that center. If object is near the center than it would fall in that particular cluster. Hence, finally you will have group or clusters created and get to know that objects fall in which particular cluster.
Question #39
A problem statement is given as below
Hospital records show that of patients suffering from a certain disease, 75% die of it.
What is the probability that of 6 randomly selected patients, 4 will recover?
Which of the following model will you use to solve it?
- A . Binomial
- B . Poisson
- C . Normal
- D . Any of the above
Correct Answer: A
Question #40
A researcher is interested in how variables, such as GRE (Graduate Record Exam scores), GPA (grade point average) and prestige of the undergraduate institution, effect admission into graduate school. The response variable, admit/don’t admit, is a binary variable.
Above is an example of
- A . Linear Regression
- B . Logistic Regression
- C . Recommendation system
- D . Maximum likelihood estimation
- E . Hierarchical linear models
Correct Answer: B
B
Explanation:
Logistic regression
Pros: Computationally inexpensive, easy to implement, knowledge representation easy to interpret
Cons: Prone to underfitting, may have low accuracy Works with: Numeric values, nominal values
B
Explanation:
Logistic regression
Pros: Computationally inexpensive, easy to implement, knowledge representation easy to interpret
Cons: Prone to underfitting, may have low accuracy Works with: Numeric values, nominal values
Question #41
Which of the following statement true with regards to Linear Regression Model?
- A . Ordinary Least Square can be used to estimates the parameters in linear model
- B . In Linear model, it tries to find multiple lines which can approximate the relationship between the outcome and input variables.
- C . Ordinary Least Square is a sum of the individual distance between each point and the fitted line of regression model.
- D . Ordinary Least Square is a sum of the squared individual distance between each point and the fitted line of regression model.
Correct Answer: A,D
A,D
Explanation:
Linear regression model are represented using the below equation
A,D
Explanation:
Linear regression model are represented using the below equation
![]()
Where B(0) is intercept and B(1) is a slope. As B(0) and B(1) changes then fitted line also shifts accordingly on the plot. The purpose of the Ordinary Least Square method is to estimates these parameters B(0) and B(1). And similarly it is a sum of squared distance between the observed point and the fitted line. Ordinary least squares (OLS) regression minimizes the sum of the squared residuals. A model fits the data well if the differences between the observed values and the model’s predicted values are small and unbiased.
Question #42
Select the correct statement which applies to Supervised learning
- A . We asks the machine to learn from our data when we specify a target variable.
- B . Lesser machine’s task to only divining some pattern from the input data to get the target variable
- C . Instead of telling the machine Predict Y for our data X, we’re asking What can you tell me about X?
Correct Answer: A,B,C
A,B,C
Explanation:
Supervised learning asks the machine to learn from our data when we specify a target variable.
This reduces the machine’s task to only divining some pattern from the input data to get the target variable.
In unsupervised learning we don’t have a target variable as we did in classification and regression.
Instead of telling the machine Predict Y for our data X> we’re asking What can you tell me about X?
Things we ask the machine to tell us about X may be What are the six best groups we can make out of X? or What three features occur together most frequently in X?
A,B,C
Explanation:
Supervised learning asks the machine to learn from our data when we specify a target variable.
This reduces the machine’s task to only divining some pattern from the input data to get the target variable.
In unsupervised learning we don’t have a target variable as we did in classification and regression.
Instead of telling the machine Predict Y for our data X> we’re asking What can you tell me about X?
Things we ask the machine to tell us about X may be What are the six best groups we can make out of X? or What three features occur together most frequently in X?
Question #43
A data scientist wants to predict the probability of death from heart disease based on three risk factors: age, gender, and blood cholesterol level.
What is the most appropriate method for this project?
- A . Linear regression
- B . K-means clustering
- C . Logistic regression
- D . Apriori algorithm
Correct Answer: C
C
Explanation:
Logistic regression is used widely in many fields, including the medical and social sciences. For example, the Trauma and Injury Severity Score (TRISS), which is widely used to predict mortality in injured patients, was originally developed by Boyd et al. using logistic regression. Many other medical scales used to assess severity of a patient have been developed using logistic regression. Logistic regression may be used to predict whether a patient has a given disease (e.g. diabetes; coronary heart disease), based on observed characteristics of the patient (age, sex, body mass index, results of various blood tests, etc.; age, blood cholesterol level, systolic blood pressure, relative weight, blood hemoglobin level, smoking (at 3 levels), and abnormal electrocardiogram.).Another example might be to predict whether an American voter will vote Democratic or Republican, based on age, income, sex, race, state of residence, votes in previous elections, etc. The technique can also be used in engineering, especially for predicting the probability of failure of a given process, system or product. It is also used in marketing applications such as prediction of a customer’s propensity to purchase a product or halt a subscription, etc.[citation needed] In economics it can be used to predict the likelihood of a person’s choosing to be in the labor force, and a business application would be to predict the likelihood of a homeowner defaulting on a mortgage. Conditional random fields, an extension of logistic regression to sequential data, are used in natural language processing.
C
Explanation:
Logistic regression is used widely in many fields, including the medical and social sciences. For example, the Trauma and Injury Severity Score (TRISS), which is widely used to predict mortality in injured patients, was originally developed by Boyd et al. using logistic regression. Many other medical scales used to assess severity of a patient have been developed using logistic regression. Logistic regression may be used to predict whether a patient has a given disease (e.g. diabetes; coronary heart disease), based on observed characteristics of the patient (age, sex, body mass index, results of various blood tests, etc.; age, blood cholesterol level, systolic blood pressure, relative weight, blood hemoglobin level, smoking (at 3 levels), and abnormal electrocardiogram.).Another example might be to predict whether an American voter will vote Democratic or Republican, based on age, income, sex, race, state of residence, votes in previous elections, etc. The technique can also be used in engineering, especially for predicting the probability of failure of a given process, system or product. It is also used in marketing applications such as prediction of a customer’s propensity to purchase a product or halt a subscription, etc.[citation needed] In economics it can be used to predict the likelihood of a person’s choosing to be in the labor force, and a business application would be to predict the likelihood of a homeowner defaulting on a mortgage. Conditional random fields, an extension of logistic regression to sequential data, are used in natural language processing.
Question #44
Question-34. Stories appear in the front page of Digg as they are "voted up" (rated positively) by the community. As the community becomes larger and more diverse, the promoted stories can better reflect the average interest of the community members.
Which of the following technique is used to make such recommendation engine?
- A . Naive Bayes classifier
- B . Collaborative filtering
- C . Logistic Regression
- D . Content-based filtering
Correct Answer: B
B
Explanation:
One scenario of collaborative filtering application is to recommend interesting or popular information as judged by the community. As a typical example, stories appear in the front page of Digg as they are "voted up" (rated positively) by the community. As the community becomes larger and more diverse, the promoted stories can better reflect the average interest of the community members.
B
Explanation:
One scenario of collaborative filtering application is to recommend interesting or popular information as judged by the community. As a typical example, stories appear in the front page of Digg as they are "voted up" (rated positively) by the community. As the community becomes larger and more diverse, the promoted stories can better reflect the average interest of the community members.
Question #45
What describes a true limitation of Logistic Regression method?
- A . It does not handle redundant variables well.
- B . It does not handle missing values well.
- C . It does not handle correlated variables well.
- D . It does not have explanatory values.
Correct Answer: B
Question #46
Select the choice where Regression algorithms are not best fit
- A . When the dimension of the object given
- B . Weight of the person is given
- C . Temperature in the atmosphere
- D . Employee status
Correct Answer: D
D
Explanation:
Regression algorithms are usually employed when the data points are inherently numerical variables (such as the dimensions of an object the weight of a person, or the temperature in the atmosphere) but unlike Bayesian algorithms, they’re not very good for categorical data (such as employee status or credit score description).
D
Explanation:
Regression algorithms are usually employed when the data points are inherently numerical variables (such as the dimensions of an object the weight of a person, or the temperature in the atmosphere) but unlike Bayesian algorithms, they’re not very good for categorical data (such as employee status or credit score description).
Question #47
Refer to image below

- A . Option A
- B . Option B
- C . Option C
- D . Option D
Correct Answer: A
A
Explanation:
A
Explanation:

Text
Description automatically generated
Question #48
A fruit may be considered to be an apple if it is red, round, and about 3" in diameter. A naive Bayes classifier considers each of these features to contribute independently to the probability that this fruit is an apple, regardless of the
- A . Presence of the other features.
- B . Absence of the other features.
- C . Presence or absence of the other features
- D . None of the above
Correct Answer: C
C
Explanation:
In simple terms, a naive Bayes classifier assumes that the value of a particular feature is unrelated to the presence or absence of any other feature, given the class variable. For example, a fruit may be considered to be an apple if it is red, round, and about 3" in diameter A naive Bayes classifier considers each of these features to contribute independently to the probability that this fruit is an apple, regardless of the presence or absence of the other features.
C
Explanation:
In simple terms, a naive Bayes classifier assumes that the value of a particular feature is unrelated to the presence or absence of any other feature, given the class variable. For example, a fruit may be considered to be an apple if it is red, round, and about 3" in diameter A naive Bayes classifier considers each of these features to contribute independently to the probability that this fruit is an apple, regardless of the presence or absence of the other features.
Question #49
Suppose that the probability that a pedestrian will be tul by a car while crossing the toad at a pedestrian crossing without paying attention to the traffic light is lo be computed. Let H be a discrete random variable taking one value from (Hit. Not Hit). Let L be a discrete random variable taking one value from (Red. Yellow. Green).
Realistically, H will be dependent on L That is, P(H = Hit) and P(H = Not Hit) will take different values depending on whether L is red, yellow or green. A person is. for example, far more likely to be hit by a car when trying to cross while Hie lights for cross traffic are green than if they are red In other words, for any given possible pair of values for Hand L. one must consider the joint probability distribution of H and L to find the probability* of that pair of events occurring together if Hie pedestrian ignores the state of the light Here is a table showing the conditional probabilities of being bit. defending on ibe stale of the lights (Note that the columns in this table must add up to 1 because the probability of being hit oi not hit is 1 regardless of the stale of the light.)
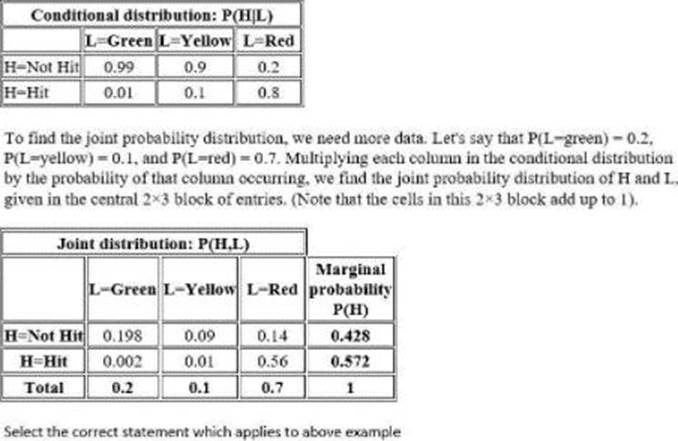
- A . The marginal probability P(H=Hit) is the sum along the H=Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green.
- B . marginal probability that P(H=Not Hit) is the sum of the H=Not Hit row
- C . marginal probability that P(H=Not Hit) is the sum of the H= Hit row
Correct Answer: A,B
A,B
Explanation:
The marginal probability P(H=Hit) is the sum along the H=Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green. Similarly, the marginal probability that P(H=Not Hit) is the sum of the H=Not Hit row
A,B
Explanation:
The marginal probability P(H=Hit) is the sum along the H=Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green. Similarly, the marginal probability that P(H=Not Hit) is the sum of the H=Not Hit row
Question #49
Suppose that the probability that a pedestrian will be tul by a car while crossing the toad at a pedestrian crossing without paying attention to the traffic light is lo be computed. Let H be a discrete random variable taking one value from (Hit. Not Hit). Let L be a discrete random variable taking one value from (Red. Yellow. Green).
Realistically, H will be dependent on L That is, P(H = Hit) and P(H = Not Hit) will take different values depending on whether L is red, yellow or green. A person is. for example, far more likely to be hit by a car when trying to cross while Hie lights for cross traffic are green than if they are red In other words, for any given possible pair of values for Hand L. one must consider the joint probability distribution of H and L to find the probability* of that pair of events occurring together if Hie pedestrian ignores the state of the light Here is a table showing the conditional probabilities of being bit. defending on ibe stale of the lights (Note that the columns in this table must add up to 1 because the probability of being hit oi not hit is 1 regardless of the stale of the light.)
- A . The marginal probability P(H=Hit) is the sum along the H=Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green.
- B . marginal probability that P(H=Not Hit) is the sum of the H=Not Hit row
- C . marginal probability that P(H=Not Hit) is the sum of the H= Hit row
Correct Answer: A,B
A,B
Explanation:
The marginal probability P(H=Hit) is the sum along the H=Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green. Similarly, the marginal probability that P(H=Not Hit) is the sum of the H=Not Hit row
A,B
Explanation:
The marginal probability P(H=Hit) is the sum along the H=Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green. Similarly, the marginal probability that P(H=Not Hit) is the sum of the H=Not Hit row
Question #49
Suppose that the probability that a pedestrian will be tul by a car while crossing the toad at a pedestrian crossing without paying attention to the traffic light is lo be computed. Let H be a discrete random variable taking one value from (Hit. Not Hit). Let L be a discrete random variable taking one value from (Red. Yellow. Green).
Realistically, H will be dependent on L That is, P(H = Hit) and P(H = Not Hit) will take different values depending on whether L is red, yellow or green. A person is. for example, far more likely to be hit by a car when trying to cross while Hie lights for cross traffic are green than if they are red In other words, for any given possible pair of values for Hand L. one must consider the joint probability distribution of H and L to find the probability* of that pair of events occurring together if Hie pedestrian ignores the state of the light Here is a table showing the conditional probabilities of being bit. defending on ibe stale of the lights (Note that the columns in this table must add up to 1 because the probability of being hit oi not hit is 1 regardless of the stale of the light.)
- A . The marginal probability P(H=Hit) is the sum along the H=Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green.
- B . marginal probability that P(H=Not Hit) is the sum of the H=Not Hit row
- C . marginal probability that P(H=Not Hit) is the sum of the H= Hit row
Correct Answer: A,B
A,B
Explanation:
The marginal probability P(H=Hit) is the sum along the H=Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green. Similarly, the marginal probability that P(H=Not Hit) is the sum of the H=Not Hit row
A,B
Explanation:
The marginal probability P(H=Hit) is the sum along the H=Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green. Similarly, the marginal probability that P(H=Not Hit) is the sum of the H=Not Hit row
Question #52
You recommend a movie with three stars but the user loves it (he’d rate it five stars).
So which statement correctly applies?
- A . In both cases, the contribution to the RMSE is the same
- B . In both cases, the contribution to the RMSE is the different
- C . In both cases, the contribution to the RMSE, could varies
- D . None of the above
Correct Answer: A
